들어가기 전
이번 포스팅에서는 Kafka Streams에서 제공하는 Tumbling Window / Hopping Window가 실제로 어떻게 동작하는지 코드 단위로 확인해보고자 한다.
알아둬야 할 부분
Tumbling Window와 Hopping Window는 TimeWindow를 바탕으로 동작한다. TimeWindow는 고정된 기간이 있는 것을 의미한다. Tumbling Window는 고정된 기간이 끝나면 새로운 Window를 생성해서 집계하는 동작을 하고, Hopping Window는 TimeWindow에 설정된 기간동안 집계는 하되 advanceMs에 설정된 기간동안 새로운 TimeWindow를 만들어서 좀 더 자주 집계하는 동작을 한다.

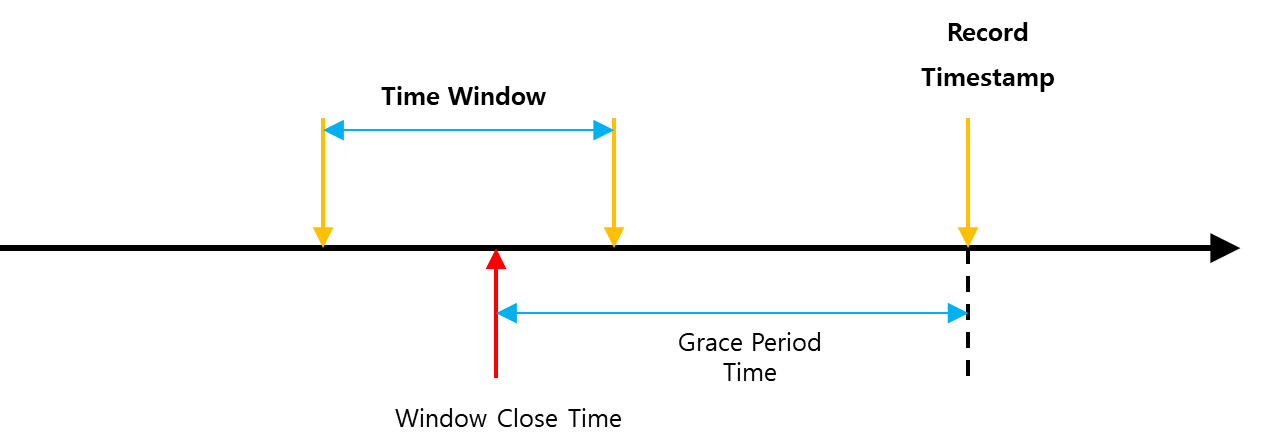
TimeWindow를 구할 때 가장 먼저 Window Close Time을 구한다. Window Close Time은 현재 Record Timestamp에서 Grace Period Time을 뺀 값으로 구한다. 이 때, 어떤 Time Window의 End가 Window Close Time보다 빠르다면, 즉 포함되지 않는다면 이 레코드는 해당 Window에는 집계되지 않는다.
이 때 GracePeriod Time은 레코드의 Timestamp를 조금 더 이른 곳까지 설정하고 그 값을 바탕으로 Window를 찾는 것으로 설정해준다. TimeStamp는 어떤 TimestampExtractor를 쓰느냐에 따라 다르게 동작하는데, 예를 들어 레코드가 도착한 시점으로 Timestamp를 뽑아온다면 이런 문제가 있을 수 있다.
- 레코드를 보냈는데 네트워크 사정으로 조금 딜레이 되서 도착한 경우
위 경우에는 Grace Period Time을 설정해서 다른 Window에 포함이 될 수 있도록 고려하는 것이 한 방법이 될 수 있다.
반면 다음과 같이 Window Close Time보다 Window의 EndTime이 큰 경우에는 해당 Window에 Record의 결과가 집계되기 시작한다.
Hopping, Thumbling Window는 TimeWindow 객체에서 설정된 값에 대응되는 TimeWindow 들을 생성한 다음에 동작한다.

먼저 Tumbling Window는 다음과 같이 하나의 Window만 생성한다. 현재 레코드의 TimeStamp를 기준으로 WindowStart를 설정하고 SizeMs를 더해서 WindowEnd를 만들어서 Window를 생성한다.

Hopping Window는 현재 레코드의 Timestamp를 기준으로 SizeMs를 빼고, Advance Ms를 더해서 WindowStart Time을 설정한다. 이 WindowStart Time을 기준으로 Window를 하나 생성하고, Window Start에 AdvanceMs를 더해서 그 다음 Window를 생성하는 동작을 반복한다. 이 동작은 WindowStart Time이 현재 레코드의 Timestamp보다 작거나 같을 때까지만 생성한다.
정리하면 Hopping Window / Tumbling Window는 하나의 레코드가 들어왔을 때 생성되는 Window의 갯수가 차이가 난다는 것을 의미하고, 각 Window마다 집계되는 것을 의미한다. 즉, Tumbling Window보다 Hopping Window는 더 자주 업데이트 되지만, 중복된 데이터의 집계가 보일 수 있다는 것을 의미한다.
의문이 드는 부분 → WindowStart는 왜 딱 나눠떨어질까?
위와 같이 Window를 계속 생성한다면 분명히 밀리 세컨드 단위로 계속 새로운 Window가 생성되어야 할 것 같다. 왜냐하면 레코드가 생성된 TimeRecord를 기준으로 Window를 생성한다면 TimeRecord가 밀리 세컨드 단위로 생성된다면 Window가 Window Start Time이 그만큼 생성될 것이기 때문이다. 그렇지만 실제로는 그렇게 동작하지 않는다.

여기서보면 위에서 9번째자리 숫자까지만 timestamp에 찍히는 것을 볼 수 있다. 이 말은 어디선가 값을 변경해주고 있다는 것이다.

실제로 KStreamWindowAggregator로 들어온 timeStamp의 값을 보면 훨씬 큰 값이 존재하고 있는 것을 볼 수 있다. 그렇다면 windowStart는 어디서 생성되는 것일까?
@Override
public Map<Long, TimeWindow> windowsFor(final long timestamp) {
long windowStart = (Math.max(0, timestamp - sizeMs + advanceMs) / advanceMs) * advanceMs;
...
}바로 위 식에서 Raw한 Timestamp가 약간의 가공이 되는 것이다.
// sizeMs = 90000, advanceMs = 90000
timestamp
>>> 1667200780479
Math.max(0, timestamp - sizeMs + advanceMs)
>>> 1667200780479
Math.max(0, timestamp - sizeMs + advanceMs) / advanceMs
>>> 18524453
(Math.max(0, timestamp - sizeMs + advanceMs) / advanceMs) * advanceMs
>>> 1667200770000다음과 같이 값이 변경되는 것을 볼 수 있다. 이렇게 변경되는 이유는 나눗셈의 결과가 Long 타입으로 주어지기 때문에 나머지가 모두 버려진다. Window의 WindowStart는 다음과 같이 결정되게 된다.
코드 보기
@Override
public void process(final Record<KIn, VIn> record) {
...
// first get the matching windows
final long timestamp = record.timestamp();
updateObservedStreamTime(timestamp);
final long windowCloseTime = observedStreamTime - windows.gracePeriodMs();
final Map<Long, W> matchedWindows = windows.windowsFor(timestamp);
// try update the window whose end time is still larger than the window close time,
// and create the new window for the rest of unmatched window that do not exist yet;
for (final Map.Entry<Long, W> entry : matchedWindows.entrySet()) {
final Long windowStart = entry.getKey();
final long windowEnd = entry.getValue().end();
if (windowEnd > windowCloseTime) {
final ValueAndTimestamp<VAgg> oldAggAndTimestamp = windowStore.fetch(record.key(), windowStart);
VAgg oldAgg = getValueOrNull(oldAggAndTimestamp);
final VAgg newAgg;
final long newTimestamp;
if (oldAgg == null) {
oldAgg = initializer.apply();
newTimestamp = record.timestamp();
} else {
newTimestamp = Math.max(record.timestamp(), oldAggAndTimestamp.timestamp());
}
newAgg = aggregator.apply(record.key(), record.value(), oldAgg);
// update the store with the new value
windowStore.put(record.key(), ValueAndTimestamp.make(newAgg, newTimestamp), windowStart);
maybeForwardUpdate(record, entry.getValue(), oldAgg, newAgg, newTimestamp);
} else {
final String windowString = "[" + windowStart + "," + windowEnd + ")";
logSkippedRecordForExpiredWindow(log, record.timestamp(), windowCloseTime, windowString);
}
}
maybeForwardFinalResult(record, windowCloseTime);
}Thumbling Window와 Hopping Window는 KStreamWindowAggregate 클래스를 이용해서 처리된다.
- 전달받은 레코드의 Key가 없는 경우 Skipping 레코드 처리를 한다.
- 레코드에서 Timestamp를 읽어온다.
- 읽어온 Timestamp에서 앞서 설정한 GracePeriod를 빼서 windowCloseTime을 생성한다.
- windows.windowsFor()를 이용해서 현재 timestamp에 대응되는 window들을 생성한다. (자세한 내용은 아래에 기술)
- 생성한 window들을 대상으로 아래 동작을 반복한다.
- windowEnd > windowCloseTime인 경우 windowStore에서 key + windowStart를 이용해서 값을 불러온다. (key + windowStart Time이 Byte 형태로 변경되어 저장됨)
- 불러온 값이 존재하지 않는 경우 집계 값을 초기화한다. 또한 timestamp는 현재 시간으로 설정한다.
- 불러온 값이 존재하는 경우, 불러온 값과 현재 timestamp 중에서 큰 값을 기준으로 시간을 설정한다.
- aggregator를 기준으로 현재 key에 대해 oldAgg, newAgg를 연산해서 newAgg에 저장한다. (업데이트 동작)
- windowStore에서 현재 Key와 newAgg, newTimeStamp를 기준으로 값을 넣고, 이 때 windowStart 시간을 넣는다.
- windowEnd > windowCloseTime인 경우 windowStore에서 key + windowStart를 이용해서 값을 불러온다. (key + windowStart Time이 Byte 형태로 변경되어 저장됨)
- maybeForwardUpdate를 이용해서 downstream 처리를 한다.
- 만약 cache가 가능할 경우에는 cahce.buffer.size, commit.interval.ms를 고려해서 후에 downstream한다.
- cache가 불가능할 경우 바로 downstream 처리를 한다.
@Override
public Map<Long, TimeWindow> windowsFor(final long timestamp) {
long windowStart = (Math.max(0, timestamp - sizeMs + advanceMs) / advanceMs) * advanceMs;
final Map<Long, TimeWindow> windows = new LinkedHashMap<>();
while (windowStart <= timestamp) {
final TimeWindow window = new TimeWindow(windowStart, windowStart + sizeMs);
windows.put(windowStart, window);
windowStart += advanceMs;
}
return windows;
}MatchedWindow를 구할 때는 TimeWindows의 windowsFor() 메서드를 이용해서 처리된다. 이 때 sizeMs와 advanceMs가 존재한다.
- sizeMS : ofSizeWithNoGrace로 설정한 값
- advanceMs : advanceBy()로 설정한 값. 설정하지 않았으면 sizeMS와 동일한 값임.
이 메서드에서는 레코드의 현재 시간을 기준으로 sizeMs를 빼고 advanceMs를 더해서 windowStart 시간을 구한다. 이 때 두 가지 경우가 있을 수 있다.
- advanceBy를 설정하지 않은 경우(Tumbling window) : windowStart = timestamp
- advanceBy를 설정한 경우(Hopping window) : windowStart = timestamp - sizeMs + advanceMs
위와 같이 분기되기 때문에 SizeWindow만 설정한 Tumbling Window는 while문을 단 한번만 수행한다. 반면 Hopping Window는 advanceMs만큼 시간을 조금씩 더해가면서 새로운 Window를 만들고 HashMap에 저장하는 동작을 반복한다. 따라서 Hopping Window에서는 HashMap에는 해당 Key에 대한 많은 Window가 존재하게 된다. 반면 Tumbling은 이 메서드의 실행 결과로 하나의 Window만 생성하게 된다.
'Kafka eco-system > KafkaStreams' 카테고리의 다른 글
| Kafka Streams In Action 5장 : KTable API (0) | 2022.11.01 |
|---|---|
| Kafka Streams : Aggregate 동작 방식 (0) | 2022.11.01 |
| Kafka Streams : 리파티셔닝의 노드 구성 (0) | 2022.10.30 |
| Kafka Streams : Process 과정에서의 레코드 (0) | 2022.10.30 |
| Kafka Streams : KTable과 Cache 내부동작 (0) | 2022.10.25 |