이 글은 Kafka Streams In Action 5장을 공부하고 정리한 글입니다.
들어가기 전
Stream은 끊임없는 이벤트의 흐름이다. Table은 어떤 처리(집계)등을 통해서 현재 상태를 보여주는 역할을 한다. Table은 Stream과는 꽤 다른 방식으로 동작하기도 하지만, Stream과 Join하면서 Stream에 또 다른 문맥을 추가해주는 역할을 할 수 있다. 때로는 Table은 Stream으로 바뀌어서 최신 데이터들만 Stream 하는 녀석도 될 수 있다.
5.1 스트림과 테이블의 관계
스트림은 연속적인 이벤트의 흐름이고, 테이블은 연속적인 이벤트들의 현재 상태를 나타낸다. 아래에서 좀 더 자세히 살펴보고자 한다.
5.1.1 레코드 스트림과 DB의 테이블

예를 들어 위와 같이 주가에 대한 스트림이 있다고 가정해보자. 그리고 이 스트림을 데이터베이스에 Insert 한 상황을 가정해보자. 스트림이 발생하는대로 데이터베이스에 넣기만 하면 다음과 같이 될 것이다.

스트림에서 발생한 이벤트를 데이터베이스에 넣으면 PK 값이 하나씩 올라가면서 적재되는 식으로 데이터베이스 테이블에 저장될 것이다. 그렇다면 Kafka Streams에서 이야기하는 KTable은 어떻게 다를까?
5.1.2 레코드 및 ChangeLog 업데이트
로그를 일반적인 이벤트 스트림으로 간주한다면, ChangeLog는 업데이트 스트림으로 간주할 수 있다. ChangeLog는 Log Clean Up Policy를 Compact로 이용해서 동일한 Key에 대해서는 최신 Value값을 유지한다. ChangeLog를 이용하면 이벤트 스트림이 어떻게 압축될까?
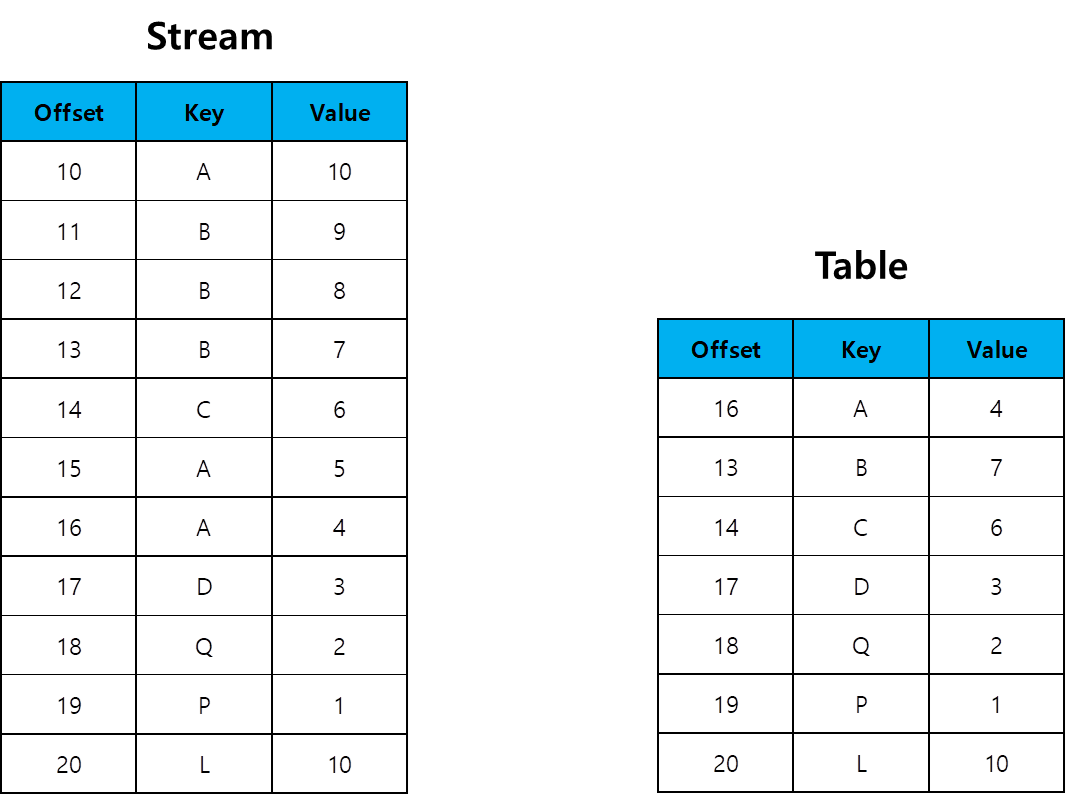
위와 같이 동일한 Key를 기준으로 Value를 최대한 유지하는 방식으로 Kafka Broker의 ChangeLog는 기록된다.
5.1.3 이벤트 스트림과 업데이트 스트림 비교 (Apache Kafka)
이벤트 스트림과 업데이트 스트림은 확연하게 차이가 있다. 이벤트 스트림(KStream)은 메세지마다 모두 출력이 되는 반면, 업데이트 스트림(KTable)은 변경된 최신값만 출력 해준다는 것이다.
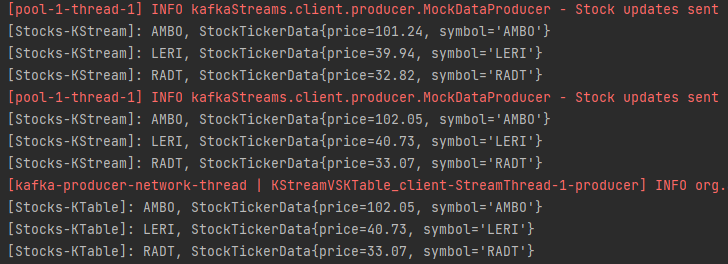
예를 들어 총 6개의 메세지가 발송되었을 때, KStream은 6개의 값이 모두 출력된다. 대조적으로 KTable은 마지막에 변경되었던 최신값인 3개만 업데이트가 된다. Key를 기준으로 최신값만 출력된다. 정리하면 다음과 같다.
- KStream은 모든 메세지를 출력한다.
- KTable은 Key값을 기준으로 최신 Value만 출력한다.
그런데 위와 같이 출력을 하기 위해서는 StateStore를 사용해야 한다는 것이다. StateStore를 사용하지 않으면 KTable이라도 메세지가 나올 때마다 값이 출력된다.
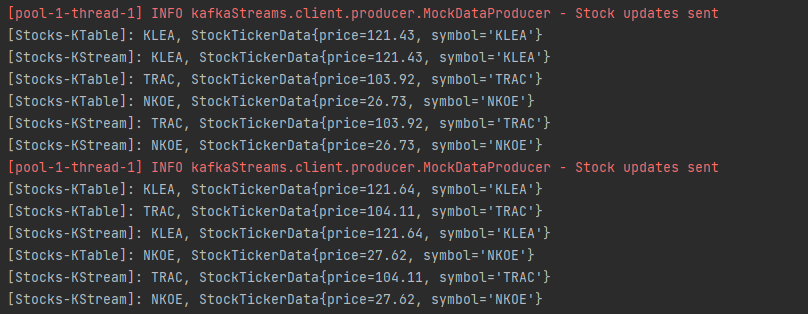
StateStore를 사용하지 않았을 때는 위에서 볼 수 있듯이 6개의 메세지가 발생했을 때 스트림과 테이블에서 각각 6개의 출력 결과가 나온 것을 확인할 수 있었다. 즉, 최신값만 업데이트 하는 형식을 사용하기 위해서는 StateStore를 이용해야만 한다.
// StateStore를 사용한 KTable → 이렇게 하면 최신값만 나옴
KeyValueBytesStoreSupplier persistentKeyValueStore = Stores.persistentKeyValueStore("persistentKeyValueStore");
KTable<String, StockTickerData> stockTickerTable = builder.
table(STOCK_TICKER_TABLE_TOPIC, Consumed.with(stringSerde, stockTickerDataSerde),
Materialized.as(persistentKeyValueStore));
stockTickerTable.toStream().print(Printed.<String, StockTickerData>toSysOut().withLabel("Stocks-KTable-With-StateStore"));
// StateStore를 사용하지 않은 KTable → 메세지가 전달될 때 마다 나옴
KTable<String, StockTickerData> stockTickerTable1 = builder.
table(STOCK_TICKER_TABLE_TOPIC, Consumed.with(stringSerde, stockTickerDataSerde));
stockTickerTable1.toStream().print(Printed.<String, StockTickerData>toSysOut().withLabel("Stocks-KTable-Without-StateStore"));
// KStream → 메세지가 전달될 때마다 나옴.
KStream<String, StockTickerData> stockTickerStream = builder.stream(STOCK_TICKER_STREAM_TOPIC,
Consumed.with(stringSerde, stockTickerDataSerde));각 코드에서는 다음과 같은 차이를 볼 수 있다.
5.2 레코드 업데이트와 KTable 구성
KTable을 생성하면 내부적으로 StateStore를 만들어서 이를 통해 Key의 최신 Value만 업데이트하는 업데이트 스트림을 구성한다. 이 때 생성되는 StateStore는 내부적으로 생성되기 때문에 대화형 쿼리에서는 사용할 수 없다. 그렇다면 KTable 관련해서 두 가지 질문을 생각해보자.
- Record는 어디에 저장되는가?
- KTable은 레코드를 내보내는 결정을 어떻게 하는가?
Record는 StateStore와 ChangeLog 토픽에 저장된다. KTable에서 레코드를 DownStream으로 보내는 시점은 두 가지 경우가 있다.
- cache.max.bytes.buffering
- commit.interval.ms
- 들어오는 데이터의 양이 많을 경우 (업데이트 된 레코드가 많을 것임)
- 구별 가능한 Key가 많이 들어올 경우 (업데이트 된 레코드가 많을 것임)
위의 네 가지 경우 중 파라메터로 조절 가능한 것은 cache.max.bytes.buffering / commit.interval.ms이다.
5.2.1 캐시 버퍼 크기 설정하기
KTable은 캐시 버퍼를 이용해서 DownStream으로 보낼 메세지를 압축할 수 있다. 즉, 동일한 Key에 여러 Value가 들어오는 경우 하나의 Key로 압축해서 메세지를 보내기 때문에 DownStream이 처리해야할 메세지수가 줄어든다. 캐시 버퍼 크기를 어떻게 설정하느냐에 따라 다양한 장점이 존재할 수 있다.
- 캐시 크기를 크게 하면 업데이트 수가 줄어든다.
- 로깅(ChangeLog에 복사)을 활성화 한 경우 KafkaBroker로 전송되는 레코드 수가 줄어든다.
캐시 크기를 크게 할 경우 위와 같은 장점이 있다. 따라서 캐시 크기를 크게 사용하기 위해서 StateStore로 Local에서 사용하는 RocksDB를 사용하는 것이 추천된다.
또한 캐시를 사용하지 않는 방법도 있다. 이것은 cache.max.bytes.buffering의 값을 0으로 설정해주는 것이다. 이렇게 되며 KTable 노드로 전달되는 모든 메세지는 모두 바로바로 Downstream으로 전달된다.
5.2.2 캐시 커밋 주기 설정하기
commit.interval.ms를 이용해서 커밋 주기를 조절할 수 있다. 커밋을 하게 되면 현재 프로세서의 상태를 저장하는 것을 의미한다. 프로세서의 상태를 저장할 때 캐시를 flush()한 후, 캐시에 저장된 레코드들을 Downstream에 전달하는 동작을 한다.
캐시 커밋 주기를 길게 가져가는 것도 Downstream에 전달되는 업데이트의 양을 줄이는 방법 중 하나가 될 수 있다. 그렇지만 캐시 커밋 주기를 길게 가져가게 되면, 여유 공안 확보를 위해서 Cache Eviction이 발생하므로 업데이트가 줄어들 수 있다.
5.3 집계와 윈도우 작업
이 곳에서는 스트림 데이터의 윈도윙에 대해서 실습을 하려고 한다.
5.3.1. 업계별 거래량 집계
스트림 데이터가 들어왔을 때 스트림 데이터를 단순히 나열하는 것 이상의 동작이 필요할 수 있다. 예를 들어 실시간 스트림 데이터를 받아서 이것을 집계해서 실시간으로 보여주는 동작을 할 수 있다.

- 주식 거래 토픽에서 데이터를 소스 프로세서(StockTransaction)로 받아온다.
- mapValues()를 이용해서 StockTransaction 객체를 ShareVolume 객체로 바꿔준다.
- ShareVolume의 symbol 필드를 Key로 해서 리파티셔닝 한다.
- Reduce 프로세서는 ShareVolume의 shares 값을 집계한다.
위의 작업을 순서대로 진행하도록 코드를 작성한다.
StreamsBuilder builder = new StreamsBuilder();
KStream<String, StockTransaction> sourceStream = builder.stream(STOCK_TRANSACTIONS_TOPIC,
Consumed.with(stringSerde, stockTransactionSerde).withOffsetResetPolicy(EARLIEST));
// 리파티셔닝을 할 때는 내부적으로 Internal Topic을 하나 더 만든다.
// 그것은 Broker에게 Log를 전송한다는 것이다. 따라서 Key / Value Serde가 필요하다.
KGroupedStream<String, ShareVolume> stringShareVolumeKGroupedStream = sourceStream
.mapValues(value -> ShareVolume.newBuilder(value).build())
.groupBy((key, value) -> value.getSymbol(),
Grouped.<String, ShareVolume>keySerde(stringSerde).withValueSerde(shareVolumeSerde));
// 같은 Key에 Value가 존재, 또 다른 Value가 들어오면 이걸 바탕으로 뭔가를 해주는 역할을 한다.
KTable<String, ShareVolume> shareVolume = stringShareVolumeKGroupedStream.reduce(ShareVolume::sum,
Materialized.<String, ShareVolume, KeyValueStore<Bytes, byte[]>>as("" +
"hello"));위와 같이 코드를 작성할 수 있다. 여기서 주의해서 봐야할 것은 두 가지다.
- groupBy에서 Group 객체에 KeyValue Serde를 각각 전달해야한다. Group을 만든다는 것은 리파티셔닝이 일어난다는 이야기다. 리파티셔닝이 일어나는 경우 Broker에 토픽이 생성되는 것이기 때문에 Serde가 필요하다. 따라서 전달해줘야한다. 이 때, withValueSerde()와 같은 형태로 값을 넘겨주는 경우에는 앞에 반드시 타입을 선언해줘야 한다.
- reduce는 집계를 하는 역할을 하는데, 이 녀석은 전달받은 값과 동일한 형태의 객체를 반환한다. 만약에 다른 객체를 전달하고 싶다면 aggregate 메서들 이용하면 된다.
이제 Sharevolume.sum(v1,v2)를 이용해서 동일한 Key에 들어오는 ShareVolume 객체에 대한 최신 값이 집계되는 형태가 된다.

마지막에 사용했던 리듀스 프로세서를 바탕으로 다시 한번 데이터 핸들링을 할 수 있다.
- ShareVolume의 industry 필드를 이용해서 리파티셔닝 한다.
- 각 industry 필드는 Value로 FixedPriorityQue를 가지고, 이 PQ는 각 산업별 상위 5개의 ShareVolume을 가진다.
- FixedPriorityQue를 String으로 바꾼다.
- String / String 형태의 Key, Value 값을 Sink Topic으로 보낸다.
위와 같은 로직을 이용한다. 이 때는 추가적인 작업이 필요한데 먼저 fixedQue를 생성하고, FixedQue에서 값의 대소비교를 할 때 필요한 comparator를 생성해야한다는 점이다.
shareVolume.groupBy((key, value) -> KeyValue.pair(value.getIndustry(), value),
Grouped.with(stringSerde, shareVolumeSerde))
.aggregate(
() -> new FixedSizePriorityQueue<ShareVolume>(shareVolumeComparator, 5),
(key, value, aggregate) -> aggregate.add(value),
(key, value, aggregate) -> aggregate.remove(value),
Materialized.with(stringSerde, fixedSizePriorityQueueSerde))
.mapValues(valueMapper)
.toStream().peek((key, value) -> log.info("Stock Volume by industry {} {}", key, value))
.to("stock-volume-by-company",
Produced.with(stringSerde, stringSerde));위에서 이야기한 것처럼 코드를 작성할 수 있다.
이 때 aggregate는 adder / substrator를 각각 구현해야한다. adder는 새로운 Key가 들어왔을 때 호출되고, substrator는 이미 존재하는 Key가 들어왔을 때 호출된 후 다시 adder가 호출된다. 따라서 각각의 행위에 대해서 정의를 해서 전달해줘야한다. 그리고 집계를 하는 녀석이기 때문에 stateStore가 필요하고, 따라서 Materialized를 이용하게 된다.
mapValues()는 현재 Value가 FixedPQ인데 이것을 Topic으로 보내기 위해서 값을 String 타입으로 바꿔준다. 이를 위해서 ValueMapper를 구현해야한다.
ValueMapper<FixedSizePriorityQueue, String> valueMapper = fpq -> {
StringBuilder stringBuilder = new StringBuilder();
Iterator<ShareVolume> iterator = fpq.iterator();
int counter = 1;
while (iterator.hasNext()) {
ShareVolume stockVolume = iterator.next();
if (stockVolume != null) {
stringBuilder
.append(counter++)
.append(")")
.append(stockVolume.getSymbol())
.append(":")
.append(numberFormat.format(stockVolume.getShares()))
.append(" ");
}
}
return builder.toString();
};valueMapper는 다음과 같이 구현되어있다. FixedQue에 있는 값들을 하나씩 불러와서 StringBuilder에 넣고 그것을 마지막으로 String으로 바꾸어주는 형태다.
StreamsBuilder builder = new StreamsBuilder();
KStream<String, StockTransaction> sourceStream = builder.stream(STOCK_TRANSACTIONS_TOPIC,
Consumed.with(stringSerde, stockTransactionSerde).withOffsetResetPolicy(EARLIEST)).peek((key, value) -> System.out.println("value = " + value));
// 리파티셔닝을 할 때는 내부적으로 Internal Topic을 하나 더 만든다.
// 그것은 Broker에게 Log를 전송한다는 것이다. 따라서 Key / Value Serde가 필요하다.
KGroupedStream<String, ShareVolume> stringShareVolumeKGroupedStream = sourceStream
.mapValues(value -> ShareVolume.newBuilder(value).build())
.groupBy((key, value) -> value.getSymbol(),
Grouped.<String, ShareVolume>keySerde(stringSerde).withValueSerde(shareVolumeSerde));
// 같은 Key에 Value가 존재, 또 다른 Value가 들어오면 이걸 바탕으로 뭔가를 해주는 역할을 한다.
KTable<String, ShareVolume> shareVolume = stringShareVolumeKGroupedStream.reduce(ShareVolume::sum,
Materialized.<String, ShareVolume, KeyValueStore<Bytes, byte[]>>as("" +
"hello"));
NumberFormat numberFormat = NumberFormat.getInstance();
ValueMapper<FixedSizePriorityQueue, String> valueMapper = fpq -> {
StringBuilder stringBuilder = new StringBuilder();
Iterator<ShareVolume> iterator = fpq.iterator();
int counter = 1;
while (iterator.hasNext()) {
ShareVolume stockVolume = iterator.next();
if (stockVolume != null) {
stringBuilder
.append(counter++)
.append(")")
.append(stockVolume.getSymbol())
.append(":")
.append(numberFormat.format(stockVolume.getShares()))
.append(" ");
}
}
return builder.toString();
};
shareVolume.groupBy((key, value) -> KeyValue.pair(value.getIndustry(), value),
Grouped.with(stringSerde, shareVolumeSerde))
.aggregate(
() -> new FixedSizePriorityQueue<>(shareVolumeComparator, 5),
(key, value, aggregate) -> aggregate.add(value),
(key, value, aggregate) -> aggregate.remove(value),
Materialized.with(stringSerde, fixedSizePriorityQueueSerde))
.mapValues(valueMapper)
.toStream().peek((key, value) -> log.info("Stock Volume by industry {} {}", key, value))
.to("stock-volume-by-company",
Produced.with(stringSerde, stringSerde));위의 코드를 전체적으로 정리하면 다음과 같은 코드가 된다. 이 예제에서 했던 중요한 작업들은 다음과 같다.
- KTable에서 공통된 Key로 값을 그룹화 함.
- 그룹화한 값으로 Reduce / Aggregate 연산등을 진행함
Reduce / Aggregate 연산을 하게 되면 KTable이 반환된다. KTable은 Reduce / Aggregate 연산 결과를 업데이트하기 위해서 내부적으로 각각 StateStore를 사용한다. 이렇게 KTable로 집계된 레코드들은 Cache Flush Strategy가 어떤 전략이냐에 따라 다르지만, 기본적으로 모든 업데이트 스트림이 DownStream으로 전달되게 할 수도 있고 그렇게 하지 않을 수도 있다.
5.3.2 윈도 연산
위 챕터에서는 무한한 시간에 대해서 집계 연산한 내용을 반환했다. 그렇지만 어떠한 경우에는 주어진 시간 범위에서만 작업이 필요한 경우도 있다. Kafka Streams는 이런 조건을 지원하고, 이런 연산을 Window 연산이라고 한다.
Window 유형
- Session Window : 메세지의 비활성 시간을 기준으로 Window를 작성함. 시간에 제약받지 않고, 사용자의 활동을 추적할 때 유용하다.
- Tumbling WIndow : 고정된 시간폭을 기준으로 Window를 구현함. 그리고 이 Window가 끝나면 새로운 Window를 생성함.
- Hopping Window : 고정된 시간폭을 기준으로 Window를 구현함. 그렇지만 AdvancedTime마다 Window를 새로 생성하고 집계함.
Kafka Streams에서는 위의 세 가지 Window 유형을 지원한다. 위에 대한 내용들은 아래에 정리했다.
Session Window 예제
Session Window를 이용한 예제는 다음과 같다.
- StockTransaction 레코드가 들어오면, 이것을 TransactionSummary 객체로 변경한다.
- TransactionSummary 객체는 SessionWindow를 이용해서 count() 된다. SessionWindow는 Session 유지 기간을 20초로 해서 작성된다.
Session 유지 기간을 20초동안 유지한다는 것은 메세지 사이의 간격이 20초 이내인 경우에는 하나의 Window로 합쳐진다는 것을 의미한다.
public class SessionWindowStreamRetry {
public static final String STOCK_TRANSACTIONS_TOPIC = "stock-transactions";
public static void main(String[] args) {
GsonSerializer<StockTransaction> stockTransactionGsonSerializer = new GsonSerializer<>();
GsonDeserializer<StockTransaction> stockTransactionGsonDeserializer = new GsonDeserializer<>(StockTransaction.class);
GsonSerializer<TransactionSummary> transactionSummaryGsonSerializer = new GsonSerializer<>();
GsonDeserializer<TransactionSummary> transactionSummaryGsonDeserializer = new GsonDeserializer<>(TransactionSummary.class);
Serde<String> stringSerde = Serdes.String();
Serde<StockTransaction> stockTransactionSerde = Serdes.serdeFrom(stockTransactionGsonSerializer, stockTransactionGsonDeserializer);
Serde<TransactionSummary> transactionSummarySerde = Serdes.serdeFrom(transactionSummaryGsonSerializer, transactionSummaryGsonDeserializer);
Properties props = new Properties();
props.setProperty(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.setProperty(StreamsConfig.APPLICATION_ID_CONFIG, UUID.randomUUID().toString());
StreamsBuilder builder = new StreamsBuilder();
KTable<Windowed<TransactionSummary>, Long> countStream = builder.stream(STOCK_TRANSACTIONS_TOPIC,
Consumed.with(stringSerde, stockTransactionSerde)
.withOffsetResetPolicy(EARLIEST))
.groupBy((key, stockTransaction) -> TransactionSummary.from(stockTransaction),
Grouped.with(transactionSummarySerde, stockTransactionSerde))
.windowedBy(SessionWindows.ofInactivityGapWithNoGrace(Duration.ofSeconds(20)))
.count();
countStream.toStream().peek((key, value) -> System.out.println("key = " + key + " value = " + value));
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), props);
kafkaStreams.start();
}
}코드는 다음과 같이 작성할 수 있다. 이 때 Window는 windowBy() 메서드를 이용해서 구현하고, 이곳에 SessionWindow 객체를 넘겨주면서 처리할 수 있다.

Peek() 메서드를 이용해서 DownStream으로 들어온 녀석들 출력한다. 우측에 @ 이후로 표시되는 녀서들은 각각 Session Window의 WindowStart / WindowEnd를 의미한다. 그리고 우측의 Values는 Count()된 값을 의미한다.
Tumbling Window 예제
Tumbling Window를 이용한 예제는 다음과 같다.
- StockTransaction 레코드가 들어오면, 이것을 TransactionSummary 객체로 변경한다.
- TransactionSummary 객체는 TimeWindows를 이용해서 count() 된다. TimeWindow를 이용해서 고정 Window Width를 20분으로 설정한다.
위의 의미는 20:00:00 ~ 20:19:59까지 하나의 Window가 되고, 20:20:20 ~ 20:39:59까지 하나의 Window가 된다는 것을 의미한다. 따라서 각 Window에 집계된 이벤트는 서로 다른 Window에서 집계되지 않는 것을 의미한다.
public class TumblingWindowStreamRetry {
public static final String STOCK_TRANSACTIONS_TOPIC = "stock-transactions";
public static void main(String[] args) {
GsonSerializer<StockTransaction> stockTransactionGsonSerializer = new GsonSerializer<>();
GsonDeserializer<StockTransaction> stockTransactionGsonDeserializer = new GsonDeserializer<>(StockTransaction.class);
GsonSerializer<TransactionSummary> transactionSummaryGsonSerializer = new GsonSerializer<>();
GsonDeserializer<TransactionSummary> transactionSummaryGsonDeserializer = new GsonDeserializer<>(TransactionSummary.class);
Serde<String> stringSerde = Serdes.String();
Serde<StockTransaction> stockTransactionSerde = Serdes.serdeFrom(stockTransactionGsonSerializer, stockTransactionGsonDeserializer);
Serde<TransactionSummary> transactionSummarySerde = Serdes.serdeFrom(transactionSummaryGsonSerializer, transactionSummaryGsonDeserializer);
Properties props = new Properties();
props.setProperty(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.setProperty(StreamsConfig.APPLICATION_ID_CONFIG, UUID.randomUUID().toString());
StreamsBuilder builder = new StreamsBuilder();
KTable<Windowed<TransactionSummary>, Long> countStream = builder.stream(STOCK_TRANSACTIONS_TOPIC,
Consumed.with(stringSerde, stockTransactionSerde)
.withOffsetResetPolicy(EARLIEST))
.groupBy((key, stockTransaction) -> TransactionSummary.from(stockTransaction),
Grouped.with(transactionSummarySerde, stockTransactionSerde))
.windowedBy(TimeWindows.ofSizeWithNoGrace(Duration.ofMinutes(20)))
.count();
countStream.toStream().peek((key, value) -> System.out.println("key = " + key + " value = " + value));
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), props);
kafkaStreams.start();
}
}Tumbling Window는 windowedBy() 메서드를 이용해서 한다. 그리고 windowedBy() 메서드에는 TimeWindow 객체를 넘겨주면서 처리할 수 있다.

Peek() 메서드를 이용해서 DownStream으로 들어온 녀석들 출력한다. 우측에 @ 이후로 표시되는 녀서들은 각각 TimeWindow의 WindowStart / WindowEnd를 의미한다. 그리고 우측의 Values는 Count()된 값을 의미한다.
Hopping Window 예제
Hopping Window를 이용한 예제는 다음과 같다.
- StockTransaction 레코드가 들어오면, 이것을 TransactionSummary 객체로 변경한다.
- TransactionSummary 객체는 TimeWindows를 이용해서 count() 된다. TimeWindow를 이용해서 고정 Window Width를 20분으로 설정한다. 그리고 advancedBy()를 이용해서 Hopping Interval 1분으로 설정한다.
위의 의미는 20:00 ~ 20:20이 하나의 Window가 된다. 그리고 다음 Window는 20:01 ~ 20:21이 생성된다. 들어온 레코드는 각 Window에 포함되는 경우에는 모두 집계된다. 위의 경우 20:19분에 들어오는 메세지는 19개의 Window에 집계된 결과가 생길 수 있다. Hopping Window는 Tumbling Window에 비해서 좀 더 자주 결과를 피드백 받아볼 수 있다는 장점이 있다.
public class HoppingWindowStreamRetry {
public static final String STOCK_TRANSACTIONS_TOPIC = "stock-transactions";
public static void main(String[] args) {
GsonSerializer<StockTransaction> stockTransactionGsonSerializer = new GsonSerializer<>();
GsonDeserializer<StockTransaction> stockTransactionGsonDeserializer = new GsonDeserializer<>(StockTransaction.class);
GsonSerializer<TransactionSummary> transactionSummaryGsonSerializer = new GsonSerializer<>();
GsonDeserializer<TransactionSummary> transactionSummaryGsonDeserializer = new GsonDeserializer<>(TransactionSummary.class);
Serde<String> stringSerde = Serdes.String();
Serde<StockTransaction> stockTransactionSerde = Serdes.serdeFrom(stockTransactionGsonSerializer, stockTransactionGsonDeserializer);
Serde<TransactionSummary> transactionSummarySerde = Serdes.serdeFrom(transactionSummaryGsonSerializer, transactionSummaryGsonDeserializer);
Properties props = new Properties();
props.setProperty(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.setProperty(StreamsConfig.APPLICATION_ID_CONFIG, UUID.randomUUID().toString());
StreamsBuilder builder = new StreamsBuilder();
KTable<Windowed<TransactionSummary>, Long> countStream = builder.stream(STOCK_TRANSACTIONS_TOPIC,
Consumed.with(stringSerde, stockTransactionSerde)
.withOffsetResetPolicy(EARLIEST))
.groupBy((key, stockTransaction) -> TransactionSummary.from(stockTransaction),
Grouped.with(transactionSummarySerde, stockTransactionSerde))
.windowedBy(TimeWindows.ofSizeWithNoGrace(Duration.ofMinutes(20)).advanceBy(Duration.ofMinutes(1)))
.count();
countStream.toStream().peek((key, value) -> System.out.println("key = " + key + " value = " + value));
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), props);
kafkaStreams.start();
}
}Tumbling Window는 windowedBy() 메서드를 이용해서 한다. 그리고 windowedBy() 메서드에는 TimeWindow 객체를 넘겨주면서 처리할 수 있다. 그리고 advancedBy() 메서드를 이용해서 Hopping Interval을 설정할 수 있다.

Peek() 메서드를 이용해서 DownStream으로 들어온 녀석들 출력한다. 우측에 @ 이후로 표시되는 녀석들은 각각 TimeWindow의 WindowStart / WindowEnd를 의미한다. 그리고 우측의 Values는 Count()된 값을 의미한다. 여기서 주의할 점은 Tumling Window와 다르게 동일한 Key에서 생성된 녀석들이지만 우측에서 보이는 TimeWindow가 좀 더 촘촘하다는 것을 의미한다.
지금 Hopping Interval은 1분으로 설정되어있다. 따라서 Unix 시간에서 60씩 증가하는 것을 볼 수 있다. 즉, 60초마다 새로운 Window가 생성되었고, 위의 결과에서 볼 수 있듯이 결과는 좀 더 자주 반환되는 것을 볼 수 있다.
5.3.3 Kstream과 KTable 조인하기
이 곳에서는 Kstream과 KTable을 조인하는 작업을 해보고자 한다. KStream과 KTable을 Join 한다는 것은 '업데이트 빈도가 상대적으로 적은' KTable을 이용해서 KStream의 데이터를 더욱 풍부하게(enrich) 만든다는 점이다. Stream - Stream Join에서는 적절한 Window가 필요했었지만, Stream - Table의 Join에는 Window가 필요하지 않다. 따라서 Table은 시작 ~ 현재까지의 누적 데이터, 혹은 최신 데이터를 가진 녀석이고, Stream은 실시간 데이터를 가지게 된다.
public static void main(String[] args) {
GsonSerializer<StockTransaction> stockTransactionGsonSerializer = new GsonSerializer<>();
GsonDeserializer<StockTransaction> stockTransactionGsonDeserializer = new GsonDeserializer<>(StockTransaction.class);
GsonSerializer<TransactionSummary> transactionSummaryGsonSerializer = new GsonSerializer<>();
GsonDeserializer<TransactionSummary> transactionSummaryGsonDeserializer = new GsonDeserializer<>(TransactionSummary.class);
Serde<StockTransaction> stockTransactionSerde = Serdes.serdeFrom(stockTransactionGsonSerializer, stockTransactionGsonDeserializer);
Serde<TransactionSummary> transactionSummarySerde = Serdes.serdeFrom(transactionSummaryGsonSerializer, transactionSummaryGsonDeserializer);
Serde<String> stringSerde = Serdes.String();
Properties props = new Properties();
props.setProperty(StreamsConfig.APPLICATION_ID_CONFIG, UUID.randomUUID().toString());
props.setProperty(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
StreamsBuilder builder = new StreamsBuilder();
KTable<Windowed<TransactionSummary>, Long> customerTransactionCounts = builder.stream(STOCK_TRANSACTIONS_TOPIC,
Consumed.with(stringSerde, stockTransactionSerde)
.withOffsetResetPolicy(EARLIEST))
.groupBy((noKey, stockTransaction) -> TransactionSummary.from(stockTransaction)
, Grouped.with(transactionSummarySerde, stockTransactionSerde))
.windowedBy(TimeWindows.ofSizeWithNoGrace(Duration.ofMinutes(5)).advanceBy(Duration.ofSeconds(30)))
.count();
// countStream 생성
KStream<String, TransactionSummary> countStream = customerTransactionCounts.toStream()
.map((window, count) -> {
TransactionSummary transactionSummary = window.key();
String newKey = transactionSummary.getIndustry();
transactionSummary.setSummaryCount(count);
return KeyValue.pair(newKey, transactionSummary);
});
// table 생성
KTable<String, String> financialNews = builder.
table("financial-news", Consumed.with(stringSerde, stringSerde).withOffsetResetPolicy(EARLIEST));
ValueJoiner<TransactionSummary, String, String> valueJoiner =
(transactionSummary, news) ->
String.format("%d shares purchased %s related news [%s]",
transactionSummary.getSummaryCount(), transactionSummary.getStockTicker(), news);
KStream<String, String> joinedStream = countStream.join(financialNews, valueJoiner,
Joined.with(stringSerde, transactionSummarySerde, stringSerde));
joinedStream.print(Printed.<String, String>toSysOut().withLabel("Transactions and News"));
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), props);
kafkaStreams.start();
}위 코드는 다음과 같다.
- StockTransaction에서 TransactionSummary 객체 생성 스트림을 만든다.
- TransactionSummary 객체를 바탕으로 Tumbling Window로 count()를 집계한 countTable을 생성한다.
- Join을 하기 위해 countTable을 countStream으로 변경한다.
- finanacial-news를 브로커에서 읽어와서 Table로 만들어둔다.
- ValueJoiner를 생성하고, 이를 이용해서 countStream과 finanacial-news Table을 Join하고 출력한다.
다음 순서대로 Join을 한다.
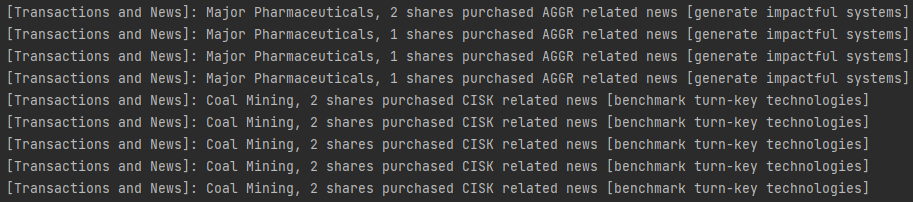
Join의 결과는 다음과 같이 출력되는 것을 볼 수 있다. 앞쪽은 TransactionSummary에서 나온 값이고, [~~~]로 표시된 것이 finanacial-news에 의한 값이다.
5.3.4 GlobalKTable
KStream과 KTable을 결합했다. 이 때 Key를 새 타입이나 값으로 맵핑한다면 리파티셔닝이 되어야한다. 가끔은 직접 리파티셔닝을 할 때가 있기도 하고, 자동으로 해주는 경우가 있을 수도 있다.
리파티셔닝 비용
리파티셔닝은 큰 비용이 든다. 왜냐하면 Kafka Streams가 내부적으로 사용하는 내부 토픽을 Broker에 하나 만들어서 메세지를 보낸다. 다시 보내는 과정에서 리파티셔닝이 되고, 다시 읽어야 하기 때문에 그만큼 지연 시간이 발생한다.
더 작은 데이터 집합과 조인하기
만약 Join 하려는 데이터가 충분히 작다면, 이 데이터 전체 사본을 개별 노드의 로컬에 배치할 수 있다. 즉, GlobalKTable을 사용해볼 수 있다. 각 Kafka Streams 노드에 동일한 데이터가 모두 복제되기 때문에 GlobalKTable은 모두 같은 값을 가진다. 전체 데이터가 각 노드에 이미 존재하기 때문에 Kafka Streams는 모든 파티션에 데이터를 공급하기 위해 조회할 데이터 키로 리파티션할 필요가 없다. 또한, GlobalKTable은 키 없는 Join도 가능하다.
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
props = InitProducerProperty.initProperty(props);
GsonSerializer<StockTransaction> stockTransactionGsonSerializer = new GsonSerializer<>();
GsonDeserializer<StockTransaction> stockTransactionGsonDeserializer = new GsonDeserializer<>(StockTransaction.class);
GsonSerializer<TransactionSummary> transactionSummaryGsonSerializer = new GsonSerializer<>();
GsonDeserializer<TransactionSummary> transactionSummaryGsonDeserializer = new GsonDeserializer<>(TransactionSummary.class);
Serde<TransactionSummary> transactionSummarySerde = Serdes.serdeFrom(transactionSummaryGsonSerializer, transactionSummaryGsonDeserializer);
Serde<StockTransaction> stockTransactionSerde = Serdes.serdeFrom(stockTransactionGsonSerializer, stockTransactionGsonDeserializer);
Serde<String> stringSerde = Serdes.String();
StreamsBuilder builder = new StreamsBuilder();
KTable<Windowed<TransactionSummary>, Long> countTable = builder.stream(STOCK_TRANSACTIONS_TOPIC,
Consumed.with(stringSerde, stockTransactionSerde)
.withOffsetResetPolicy(EARLIEST))
.groupBy((noKey, stockTransaction) -> TransactionSummary.from(stockTransaction),
Grouped.with(transactionSummarySerde, stockTransactionSerde))
.windowedBy(TimeWindows.ofSizeWithNoGrace(Duration.ofMinutes(1)))
.count();
KStream<String, TransactionSummary> countStream = countTable.toStream().map((window, count) -> {
TransactionSummary transactionSummary = window.key();
String newKey = transactionSummary.getIndustry();
transactionSummary.setSummaryCount(count);
return KeyValue.pair(newKey, transactionSummary);
});
GlobalKTable<String, String> publicCompanies = builder.globalTable(COMPANIES.topicName(),
Consumed.with(stringSerde, stringSerde));
GlobalKTable<String, String> clients = builder.globalTable(CLIENTS.topicName(),
Consumed.with(stringSerde, stringSerde));
countStream.leftJoin(publicCompanies, (key, txn) -> txn.getStockTicker(),(readOnlyKey, value1, value2) -> value1.withCompanyName(value2))
.leftJoin(clients, (key, value) -> value.getCustomerId(), (readOnlyKey, value1, value2) -> value1.withCustomerName(value2))
.print(Printed.<String, TransactionSummary>toSysOut().withLabel("My Resolved"));
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), props);
kafkaStreams.start();
}다음과 같은 코드를 작성할 수 있다.
- GlobalKTable을 가져온다.
- CounStream과 GlobalKTable을 LeftJoin을 2회 실행하면서 데이터를 가져온다.
5.3.5 쿼리 가능한 상태
구체화된 View(Materialized View)는 "쿼리 결과를 담는 데이터베이스 객체"를 의미한다. Kafka Streams는 이런저런 쿼리 결과를 StateStore나 Topic 등에 저장한다. 우리가 이것을 Consumer 등으로 다시 읽는 행위가 Materialized View로 이해할 수 있다.
Kafka Streamse는 State Store로부터 대화형 쿼리도 제공한다. 즉, Materialized View에서 직접 데이터를 읽는 기능을 제공한다. 그런데 이 작업은 '읽기 전용 작업'이라는 점을 유의해야한다. 또한 이것은 Kafka Consumer에서 데이터를 소비 하지 않아도 StateStore에서 직접 데이터를 가져와서 새로운 대시보드 어플리케이션 등을 만들 수 있는 것을 의미하기도 한다.
상태 저장소의 장점을 설명하면 다음과 같다.
- Kafka Consumer로 읽어서 DB에 저장 → DB에서 값을 읽어서 구성
- StateStore에서 직접 읽어서 구성
전자의 경우에는 Consumer와 DB가 필요하지만, 후자의 경우에는 Consumer와 DB가 필요없다. 즉, 데이터를 한번 더 쓰고 읽는 시간이 필요없어지고 작성해야하는 코드의 양도 줄어든다는 것을 의미한다.
Kafka Stremas 5장 요약
- KStream은 이벤트 스트림, KTable은 업데이트 스트림을 의미한다.
- KTable의 크기는 계속 증가하지 않으며, 같은 Key에 있는 Value가 최신으로 업데이트 된다.
- KTable은 집계 작업이 필요하다.
- Window 연산을 이용해서 데이터를 집계해서 넣을 수 있다.
- GlobalKTable은 파티션에 대한 고려 없이 어플리케이션 전체에 걸쳐 조회 데이터를 제공한다.
- KStream, KTable, GlobalKTable과 서로 Join 할 수 잇다.
알아둘 것
Local State를 이용해서 이벤트 스트림과 업데이트 스트림을 결합할 수 있다. 그리고 업데이트 스트림이 충분히 작다면 GlobalKTable에 저장할 수 있다. GlobalKTable은 Kafka Streams 클러스터 전체 노드가 동일한 데이터를 가진다.
ChangeLog와 Log의 차이 : Log는 모든 스트림 레코드가 Append 되어 저장된다. 그래서 이것을 불러와서 읽을 수 있다. 그렇지만 ChangeLog는 Compact 방식으로 Log를 관리하기 때문에 동일한 Key의 최신값만 유지한다.
GroupByKey, GroupBy의 차이점
GroupByKey는 이미 스트림이 키를 가지고 있는 경우에만 사용한다. GroupByKey를 사용할 경우 리파티셔닝 필요 플래그가 절대로 활성화 되지 않는다. 반면 GroupBy는 그룹화를 위한 키가 변경될 수 있다고 가정한다. 따라서 GroupBy 함수를 호출하게 되면 자동적으로 리파티셔닝이 된다.
KGroupedStream
Stream에서 GroupBy, GroupByKey를 하게 되면 중간에 KGroupedStream이 생긴다. 이것은 리파티셔닝 된 스트림을 이야기한다. 리파티셔닝 되었다는 말은 새로운 내부 토픽이 브로커에 생성되었다는 것을 의미한다. KGroupedStream이 생기면 이것을 바탕으로 Aggreagte, Reduce를 이용해 집계 작업을 할 수 있다. 집계 작업을 할 때는 StateStore를 사용하기 때문에 KTable이 될 것이고 이에 따라 모든 업데이트가 Downstream으로 전달되지는 않는다.
찾아봐야 할 것
1. aggregate 함수에서 init()는 언제 호출되는지 ? 예상은 Key가 없는 경우에만..
@Override
public void process(final Record<KIn, Change<VIn>> record) {
...
final ValueAndTimestamp<VAgg> oldAggAndTimestamp = store.get(record.key());
final VAgg oldAgg = getValueOrNull(oldAggAndTimestamp);
final VAgg intermediateAgg;
long newTimestamp = record.timestamp();
// first try to remove the old value
// 메세지에 값이 있고, StateStore에 저장된 값이 있을 때
if (record.value().oldValue != null && oldAgg != null) {
// remove를 호출한다.
intermediateAgg = remove.apply(record.key(), record.value().oldValue, oldAgg);
newTimestamp = Math.max(record.timestamp(), oldAggAndTimestamp.timestamp());
} else {
intermediateAgg = oldAgg;
}
// then try to add the new value
final VAgg newAgg;
if (record.value().newValue != null) {
final VAgg initializedAgg;
if (intermediateAgg == null) {
initializedAgg = initializer.apply();
} else {
initializedAgg = intermediateAgg;
}
newAgg = add.apply(record.key(), record.value().newValue, initializedAgg);
if (oldAggAndTimestamp != null) {
newTimestamp = Math.max(record.timestamp(), oldAggAndTimestamp.timestamp());
}
} else {
newAgg = intermediateAgg;
}
// update the store with the new value
store.put(record.key(), ValueAndTimestamp.make(newAgg, newTimestamp));
tupleForwarder.maybeForward(
record.withValue(new Change<>(newAgg, sendOldValues ? oldAgg : null))
.withTimestamp(newTimestamp));
}
}
aggregate Processor로 들어왔을 때 호출됨.

KTableAggregate는 CommitInterval을 만족하거나 CacheSize를 만족했을 때에만
2. aggregate 함수에서 adder / substrator는 각각 어떨 때 호출된느지.
3. KTable은 파티셔닝 되어있는지, GlobalKTable은 파티셔닝 되어있는지.
'Kafka eco-system > KafkaStreams' 카테고리의 다른 글
| Kafka Streams : Session Window 동작 (0) | 2022.11.11 |
|---|---|
| Kafka Streams : Join 스트림의 내부동작 (2) | 2022.11.11 |
| Kafka Streams : Aggregate 동작 방식 (0) | 2022.11.01 |
| Kafka Streams : Tumbling Window / Hopping Window 동작 (0) | 2022.10.31 |
| Kafka Streams : 리파티셔닝의 노드 구성 (0) | 2022.10.30 |