
Kafka Streams : 리파티셔닝의 노드 구성
- Kafka eco-system / KafkaStreams
- 2022. 10. 30.
KStream<String, StockTransaction> sourceStream = builder.stream(STOCK_TRANSACTIONS_TOPIC,
Consumed.with(stringSerde, stockTransactionSerde).withOffsetResetPolicy(EARLIEST)).peek((key, value) -> System.out.println("value = " + value));
// 리파티셔닝을 할 때는 내부적으로 Internal Topic을 하나 더 만든다.
// 그것은 Broker에게 Log를 전송한다는 것이다. 따라서 Key / Value Serde가 필요하다.
KGroupedStream<String, ShareVolume> stringShareVolumeKGroupedStream = sourceStream
.mapValues(value -> ShareVolume.newBuilder(value).build())
.groupBy((key, value) -> value.getSymbol(),
Grouped.<String, ShareVolume>keySerde(stringSerde).withValueSerde(shareVolumeSerde));
// 같은 Key에 Value가 존재, 또 다른 Value가 들어오면 이걸 바탕으로 뭔가를 해주는 역할을 한다.
KTable<String, ShareVolume> shareVolume = stringShareVolumeKGroupedStream.reduce(ShareVolume::sum,
Materialized.<String, ShareVolume, KeyValueStore<Bytes, byte[]>>as("" +
"hello"));
shareVolume.groupBy((key, value) -> KeyValue.pair(value.getIndustry(), value),
Grouped.with(stringSerde, shareVolumeSerde))
.aggregate(
() -> new FixedSizePriorityQueue<>(shareVolumeComparator, 5),
(key, value, aggregate) -> aggregate.add(value),
(key, value, aggregate) -> aggregate.remove(value),
Materialized.with(stringSerde, fixedSizePriorityQueueSerde))
.mapValues(valueMapper)
.toStream().peek((key, value) -> log.info("Stock Volume by industry {} {}", key, value))
.to("stock-volume-by-company",
Produced.with(stringSerde, stringSerde));다음과 같이 토폴로지를 구성을 했다고 가정해보자. 토폴로지를 요약하면 다음과 같다.
- "STOCK_TRANSACTIONS_TOPIC"에서 소스를 읽어온다.
- mapValues()를 이용해서 객체를 StockTransaction에서 ShareVolume으로 바꾼다.
- ShareVolume의 Symbol 필드를 이용해서 키를 그룹핑 한다.
- 그룹핑 된 녀석을 바탕으로 리듀스 연산을 진행한다.
- 리듀스 연산이 진행된 녀석을 바탕으로 다시 groupBy를 진행한다.
- groupBy가 진행된 녀석을 대상으로 aggregate를 진행한다.
이렇게 만들어지면 topology를 봤을 때는 Source - mapValue - Partition - Reduce가 순서대로 각각 child를 가져야 할 것처럼 보인다. 그렇지만 실제로는 그렇지 않다.
StreamTask는 어떻게 구성될까?

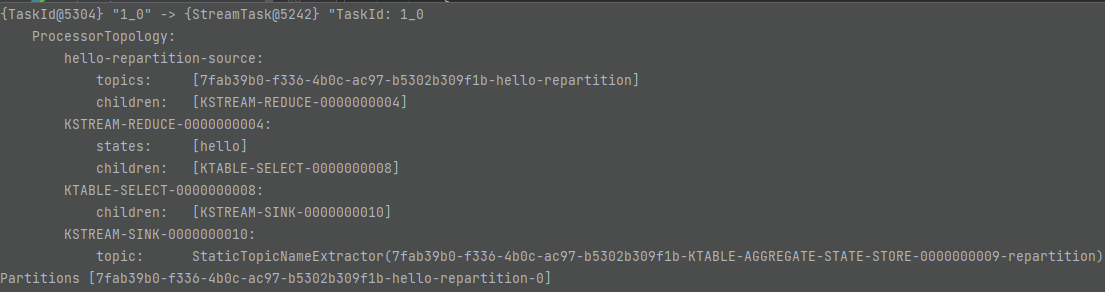
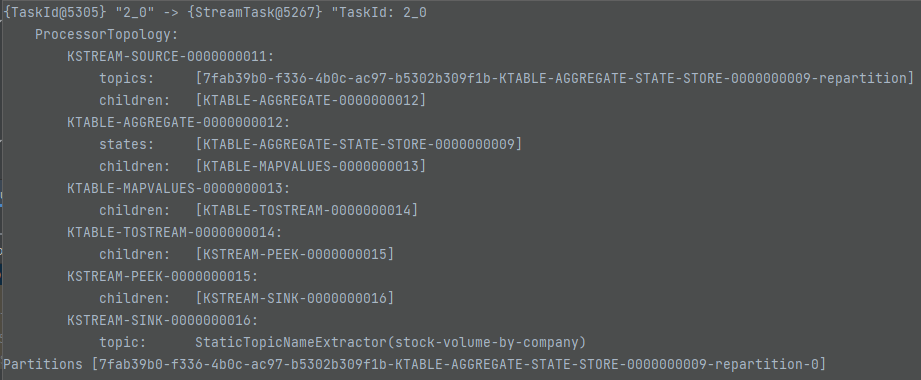
실제는 위와 같은 구성이 되는 것을 볼 수 있다. StreamTask의 번호가 0 - 1 - 2 순으로 2개가 더 생겼다. 그리고 순서대로 어떤 작업을 하는지도 확인할 수 있다. 각 StreamTask의 끝에는 현재 Sink가 있고, 이 Task가 끝이 나면 우선은 Kafka Broker에게 메세지를 전달한다는 것을 의미한다. 그리고 StreamTask의 가장 앞에는 Source가 있는데, 이것은 Kafka Broker에게서 메세지를 받아와서 일을 하겠다는 것을 의미한다. 즉, 위의 토폴로지는 Kafka Broker로부터 3번에 걸쳐서 데이터를 받아온다는 의미다.
MapValues - KeySelect - Repartition - Sink 순으로 되는데 이것은 어떻게 보면 당연한 것이다. Kafka Stream는 리파티셔닝이 필요할 때 내부적으로 Internal Topic을 만들고, Internal 토픽에서 다시 값을 불러오는 방식으로 동작하기 때문이다. 따라서 리파티셔닝 결과를 밖으로 보내주는 Sink Node가 생성되게 된다.
Sink Node는 인터널 토픽으로 메세지를 보내주고, 그렇다면 KafkaStreams는 다시 한번 Kafka Broker에게서 인터널 토픽에 대한 메세지를 읽어와서 다시 한번 처리를 해야한다. 즉, 리파티셔닝을 하게 되면 Topology 상에서 자식 노드를 가지지 않게 되는 것을 의미한다.
레코드 관점에서는 뭐가 달라질까?
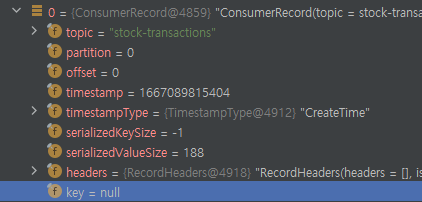
가져온 레코드 관점에서 다시 한번 살펴보면 다음과 같다. 첫번째로 가져온 pollPhase에서는 Key가 없는 것을 볼 수 있다.

그렇지만 그 다음 pollPhase()에서 불러온 것을 보면 stock-transaction의 첫번째 Batch를 불러오는 것은 물론이고 AGGREGATE에서 사용하고 있는 StateStore에 대한 repartition 인터널 토픽, 그리고 groupBy() 메서드를 이용해서 만든 인터널 토픽인 hello-repartition까지 볼 수 있다.
// TaskExecutor.process()
int process(final int maxNumRecords, final Time time) {
int totalProcessed = 0;
Task lastProcessed = null;
for (final Task task : tasks.activeTasks()) {
final long now = time.milliseconds();
try {
if (taskExecutionMetadata.canProcessTask(task, now)) {
lastProcessed = task;
totalProcessed += processTask(task, maxNumRecords, now, time);
}
} catch (final Throwable t) {
taskExecutionMetadata.registerTaskError(task, t, now);
tasks.removeTaskFromCuccessfullyProcessedBeforeClosing(lastProcessed);
commitSuccessfullyProcessedTasks();
throw t;
}
}
return totalProcessed;
}가져온 레코드는 각 StreamTask의 PartitionGroup에 각각 저장된다. TaskExecutor의 process()에서는 for 문을 돌면서 모든 activeTask를 불러와서 processTask()를 한다.

이 때 Tasks는 ActiveTask에 있는 녀석들이고 위와 같이 각각 순서대로 진행을 할 수 있도록 작성된 것을 볼 수 있다. 여기서 알 수 있는 것은 StreamTask는 두 개의 숫자 이름을 가지는데 첫번째는 Topology 상에서의 실행 순서, 두번째 숫자는 파티션의 번호라는 것을 알 수 있다. 아무튼 이렇게 구성이 되어있기 때문에 만약 해당 StreamTask에 레코드가 없으면 아무런 일을 하지 않고 다음 StreamTask가 실행될 것이다.
StreamTask 관점의 노드 리파티셔닝
StreamTask 단위로 Commit이 된다. 따라서 각각 StreamTask 단위로 Commit Interval이 적용이 될텐데, 이것은 Buffer.Cache가 차지 않았고 각각이 StateStore를 쓰는 형태라면 최대 Commit interval * 3의 시간이 지난 후에야 최종 결과를 받아볼 수 있따는 것을 의미한다.
'Kafka eco-system > KafkaStreams' 카테고리의 다른 글
| Kafka Streams : Aggregate 동작 방식 (0) | 2022.11.01 |
|---|---|
| Kafka Streams : Tumbling Window / Hopping Window 동작 (0) | 2022.10.31 |
| Kafka Streams : Process 과정에서의 레코드 (0) | 2022.10.30 |
| Kafka Streams : KTable과 Cache 내부동작 (0) | 2022.10.25 |
| KafkaStreams : StateStore (0) | 2022.10.24 |


