이 글은 코드를 따라보면서 작성한 글입니다. 따라서 실제와는 다를 수 있으니 참고만 해주세요.
들어가기 전
Ktable은 기본적으로 KStream과 다르게 UpdateStream을 할 수 있다. 무슨 말이냐면 모든 이벤트를 downstream으로 보내는 것이 아니라 Cache Buffer를 이용해서 특정 조건을 만족하는 경우에만 downStream으로 보내서 Stream Process의 양을 줄이는 역할을 할 수 있다.
KTable Cache
- cache.max.bytes.buffering
- commit.interval.ms
개발자 입장에서는 KTable의 Cache는 크게 두 가지 파라메터를 이용해서 통제할 수 있다. 여기서 cache.max.bytes.buffering은 StreamTask가 작업을 하는 도중에 처리된다. 예를 들어 어떤 메세지가 들어와서 StreamTask에 전달되어서 cache에 put()을 할 때 고려된다. cache에 put()을 한 후에 해당 Cache가 가득 찼다면 flush()를 하는 동작을 한다.
commit.interval.ms는 Kafka Streams의 commit 간격을 조절하는 것이다. kafka Streams는 commit을 할 때, 레코드 뿐만 아니라 StateStore까지 flush()를 한다.
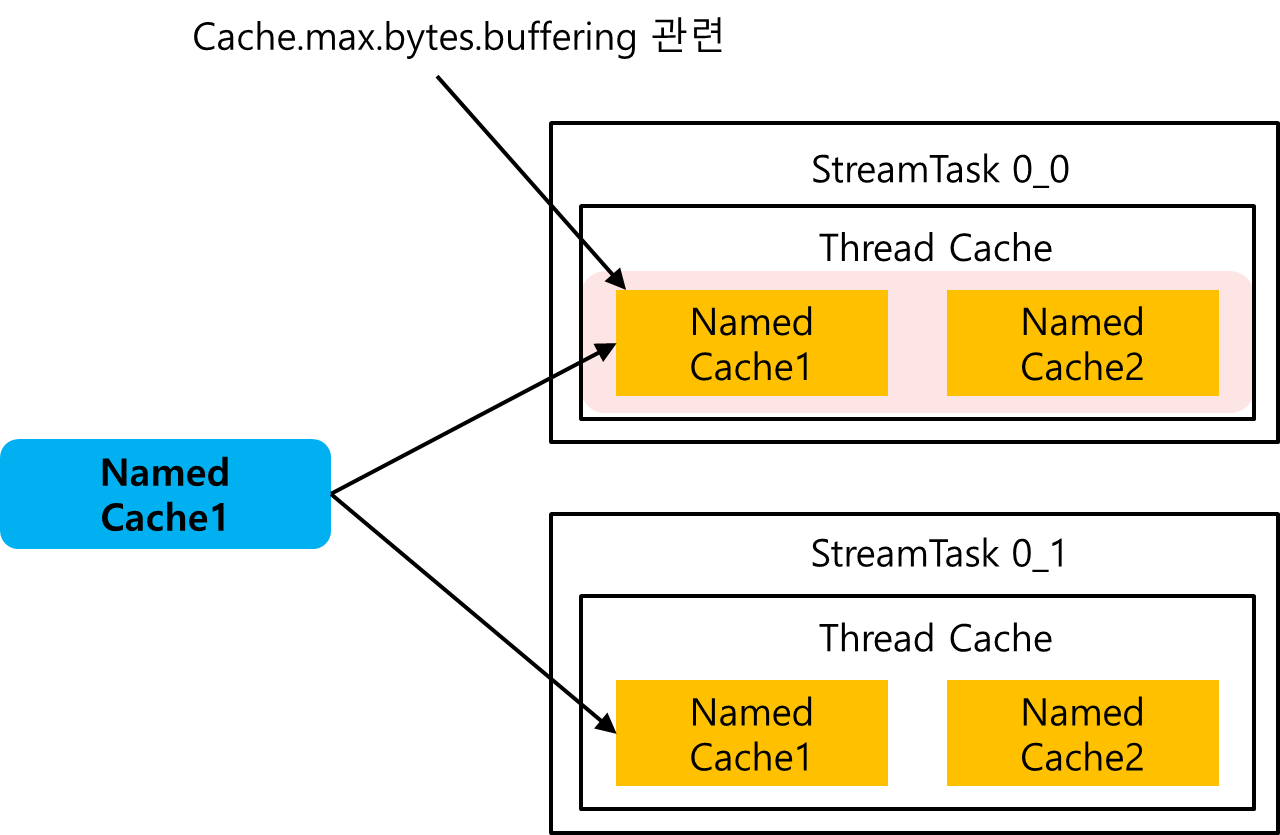
구조는 다음과 같이 생성된다. Topology Node에 하나의 StateStore가 추가되면, 해당 StateStore는 StreamTask 별로 생성이 된다. 그리고 각 StreamTask는 ThreadCache 객체, 혹은 StateManager 객체를 통해서 NamedCache를 관리하게 된다.
Cache.max.bytes.buffering은 각 StreamTask가 가지고 있는 모든 NamedCache들의 BytesSize와 비교된다. 위의 그림을 예로 들면, Cache.max.bytes.buffering은 StreamTask0_0이 가지고 있는 모든 NamedCache의 Cache 사이즈가 cache.max.bytes.buffering 보다 큰 지를 확인한다.
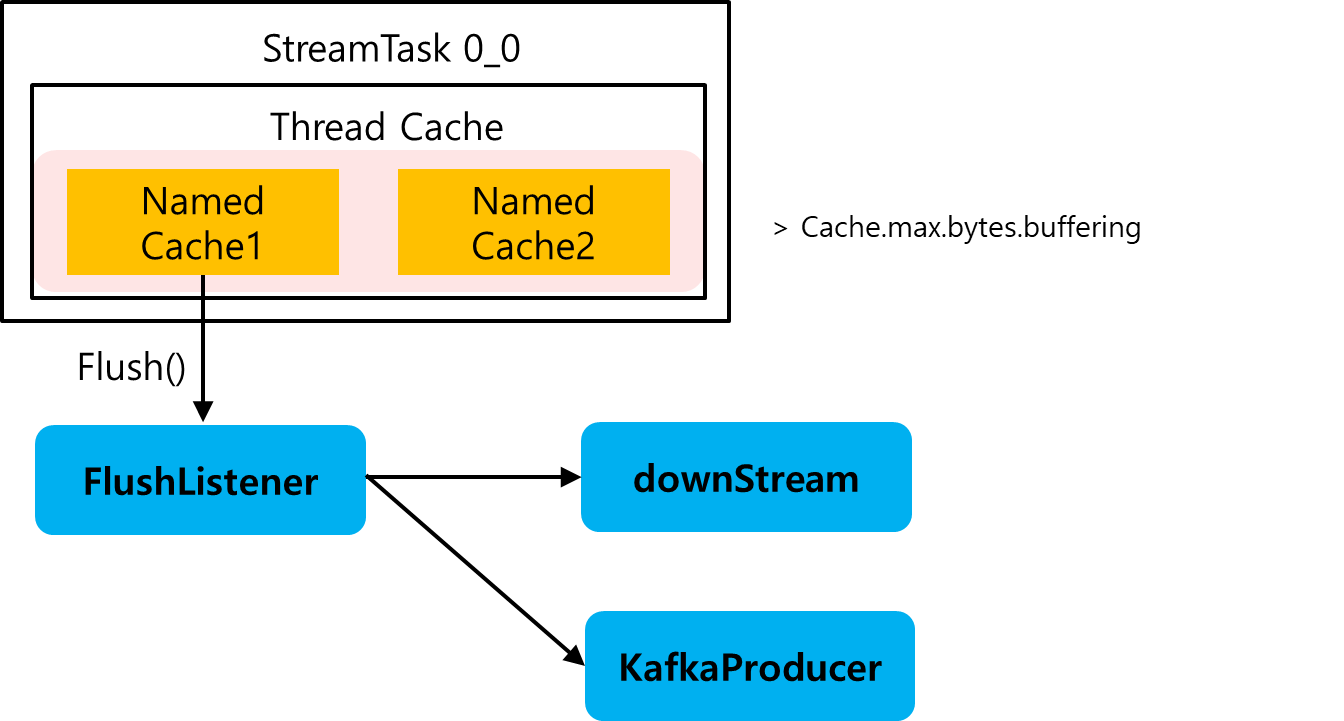
NamedCache1에 put()하는 도중에 최대 캐시 버퍼링 사이즈를 초과했다면, NamedCache는 evict() 메서드를 호출해서 해당 NamedCache를 flush하는 작업을 한다. flushListener()는 flush()작업을 대신해준다. FlushListener는 전달된 NamedCache에 존재하는 모든 LRU 캐시 노드(Value) 값을 가져와서 DownStream으로 보내주고 KafkaProducer로 보내준다.
이때부터 DownStream에서는 KTable에서 발생한 업데이트 스트림을 확인할 수 있고, Kafka Producer의 ChangeLog에도 이 값이 저장되게 된다.
코드 따라가보기
cache.max.bytes.buffering 설정 관련
KTableSource
@Override
public void process(final Record<KIn, VIn> record) {
// if the key is null, then ignore the record
if (record.key() == null) {
...
return;
}
if (queryableName != null) {
final ValueAndTimestamp<VIn> oldValueAndTimestamp = store.get(record.key());
final VIn oldValue;
...
} else {
...
}
// 이 부분
store.put(record.key(), ValueAndTimestamp.make(record.value(), record.timestamp()));
tupleForwarder.maybeForward(record.withValue(new Change<>(record.value(), oldValue)));
} else {
context.forward(record.withValue(new Change<>(record.value(), null)));
}KTableSource의 Process() 메서드는 다음과 같이 구성되어있다.
- 만약에 Key값이 없는 메세지라면, Skipping Record가 발생한다.
- queryableName이 있는 경우에는 StateStore에 메세지를 저장한다. 그리고 tupleForwarder를 이용해서 forward() 한다.
- queryableName이 없는 경우에는 일반 Stream처럼 forward()한다.
위에서 중요하게 봐야할 점은 StateStore가 있는 경우 StateStore에 put()을 하고, tupleForwarder를 이용해서 다음 작업을 진행한다는 것이다.
StateStore.put
@Override
public void put(final Bytes key,
final byte[] value) {
...
lock.writeLock().lock();
try {
...
putInternal(key, value);
} finally {
lock.writeLock().unlock();
}
}StateStore.put()은 CahcingKeyValueStore.put()을 호출하게 된다. 이 때 putInternal()을 통해서 메세지를 넣어준다. 여기서 중요하게 봐야할 부분은 캐시 역할을 하는 StateStore에 put()을 하기 전후로 Lock을 건다는 점이다. 즉, Cahce는 동시성 문제가 해결될 수 있으나 병목 구간이 될 수도 있음을 의미한다.
private void putInternal(final Bytes key,
final byte[] value) {
context.cache().put(
cacheName,
key,
new LRUCacheEntry(
value,
context.headers(),
true,
context.offset(),
context.timestamp(),
context.partition(),
context.topic()));
StoreQueryUtils.updatePosition(position, context);
}putInternal()을 하게 되면 CachingKeyValueStore 클래스의 putInternal()로 넘어온다. 여기서는 context.cache()를 이용해서 Thread Cache를 불러온다. 이 Thread Cache는 StreamThread가 가지고 있는 캐시를 의미하는 것 같다. 아무튼 여기서 ThreadCache를 가져와서 이곳에 LRuCacheEntry를 만들어서 넣어준다.
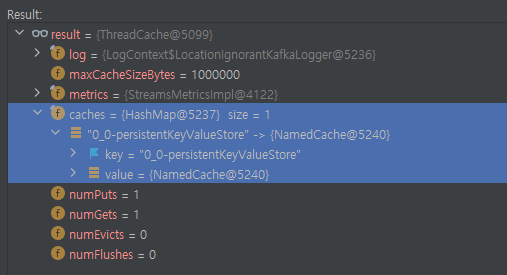
ThreadCache는 다음과 같은 구조를 가지는데, 내부적으로 caches를 가진다. 그리고 이곳에는 NamedCache 객체가 저장되어있는데, Key는 StateStore의 이름이고 Value는 NamedCache인 것을 확인할 수 있다. 그리고 한 가지 잘 봐야할 점은 StateStore에 StreamTask의 이름이 붙어있는 것이다. 즉, 하나의 StateStore를 StreamBuilder에 추가하더라도 그 StateStore는 각 StreamTask의 이름으로 하나씩 만들어져서 StreamTask마다 할당된다는 것이다.
public void put(final String namespace, final Bytes key, final LRUCacheEntry value) {
numPuts++;
final NamedCache cache = getOrCreateCache(namespace);
cache.put(key, value);
maybeEvict(namespace);
}ThreadCache의 put() 메서드로 넘어오게 된다. 여기서는 두 가지의 작업을 한다.
- ThreadCache가 가지고 있는 캐시들 중에서 namespace(StateStore)의 이름으로 검색해서 캐시를 가져온 후에, 메세지를 넣는 작업을 한다.
- 찾아온 캐시 저장소에서 evict가 되어야 하는지 확인하고, 필요 시 evict을 진행한다.
synchronized void put(final Bytes key, final LRUCacheEntry value) {
...
LRUNode node = cache.get(key);
if (node != null) {
numOverwrites++;
currentSizeBytes -= node.size();
node.update(value);
updateLRU(node);
} else {
node = new LRUNode(key, value);
// put element
putHead(node);
cache.put(key, node);
}
if (value.isDirty()) {
// first remove and then add so we can maintain ordering as the arrival order of the records.
dirtyKeys.remove(key);
dirtyKeys.add(key);
}
currentSizeBytes += node.size();
}NamedCache의 put() 메서드로 넘어왔다.
- NamedCache에서 Key로 조회해서 LRU 캐시 노드를 불러온다. 만약 노드가 있다면 이미 해당 Key로 NamedCache에 저장된 값이 있기 때문에 그 값을 삭제하고 업데이트 해준다.
- LRU 캐시 노드가 없는 경우 새로운 LRU 캐시 노드를 만들고 NamedCache에 넣어준다.
- dirtyKeys에서 Key를 제거하고 새로 추가해준다.
- 해당 NamedCache 사이즈를 새로 생성된 Node(캐시 노드)의 Size()만큼 추가해준다.
이 때, Value(LRU Cache Entry)는 생성될 때 항상 dirtyValue가 true로 생성되기 때문에 dirtyKeys에서 key를 제거하고 다시 넣는 작업을 한다.
private void maybeEvict(final String namespace) {
int numEvicted = 0;
while (sizeBytes() > maxCacheSizeBytes) {
final NamedCache cache = getOrCreateCache(namespace);
// we abort here as the put on this cache may have triggered
// a put on another cache. So even though the sizeInBytes() is
// still > maxCacheSizeBytes there is nothing to evict from this
// namespaced cache.
if (cache.isEmpty()) {
return;
}
cache.evict();
numEvicts++;
numEvicted++;
}
if (log.isTraceEnabled()) {
log.trace("Evicted {} entries from cache {}", numEvicted, namespace);
}
}위는 maybeEvict() 메서드다.
- sizeBytes()는 현재 ThreadCache가 가지고 있는 모든 캐시의 Byte 사이즈를 체크한다. 만약 ThreadCache가 가지고 있는 모든 캐시의 사이즈가 maxCacheSizeBytes보다 클 경우에는 evict()을 실행한다.
- 이 때, maxCacheSizeBytes는 cache.max.bytes.buffering에서 설정한 값과 동일하다.
- 만약 문제가 없다면 cache를 evict하지 않는다.
- evict을 할 때는 NamedCache에 전달된 Cache 이름으로 검색한 녀석으로 한다. 예를 들어 여기서는 0_0-persistentKeyValueStore가 Evict 대상이 된다.
synchronized void evict() {
if (tail == null) {
return;
}
final LRUNode eldest = tail;
currentSizeBytes -= eldest.size();
remove(eldest);
cache.remove(eldest.key);
if (eldest.entry.isDirty()) {
flush(eldest);
}
}NamedCache의 evict()으로 넘어온다. NamedCache는 LRU Cache를 가지고 있기 때문에 Tail부터 검사한다.
- Cache의 Tail이 없는 경우는 처리할 것이 없기 때문에 아무것도 하지 않는다.
- Tail이 있다면, 가장 오래된 녀석이기 때문에 이녀석을 제거한 후에 Cache의 사이즈를 작게 표현해준다.
- tail 부분을 flush() 해준다.
Cache에서 evict 된다는 것은 캐시 내에서 제거되고, 그 값이 downStream으로 전달된다는 것을 의미한다.
private void flush(final LRUNode evicted) {
...
final List<ThreadCache.DirtyEntry> entries = new ArrayList<>();
...
if (evicted != null) {
entries.add(new ThreadCache.DirtyEntry(evicted.key, evicted.entry.value(), evicted.entry));
dirtyKeys.remove(evicted.key);
}
for (final Bytes key : dirtyKeys) {
final LRUNode node = getInternal(key);
...
entries.add(new ThreadCache.DirtyEntry(key, node.entry.value(), node.entry));
...
}
...
dirtyKeys.clear();
listener.apply(entries);
...
}NamedCache.flush() 메서드로 넘어오게 된다. 여기서 먼저 변수를 설명하면 다음과 같다.
- evicted : NamedCache의 evict() 메서드에서 전달된 녀석이다. 이 녀석은 NamedCache의 Tail Node를 의미한다. 즉, 캐시에서 가장 오래된 녀석이다.
- entries : NamedCache에서 flush()될 녀석들을 의미한다.
먼저 변수에 대해서 다음과 같이 이해를 한다. 그리고 동작을 살펴보면 다음과 같다.
- evicted는 LRU Cache의 tail 부분이다. Flush() 대상이기 때문에 entries에 추가한다.
- dirtyKeys는 NamedCache가 내부적으로 가지고 있는 CacheNode들의 키의 목록이다. NamedCache가 가지고 있는 모든 dirtyKeys를 가지고 와서 entries()에 추가한다.
- FlushListenr()에게 entries를 전달하면서 Flush()를 요청한다.
다음과 같은 작업을 하게 된다. 여기서 모든 dirtyKeys를 넘겨주는 이유는 cache.max.bytes.buffering이 가득 찬 경우에 Cache에 있는 모든 녀석을 Flush()하는 동작이기 때문이다. FlushListener()는 flush() 해야할 Cache Entry를 받아서 각각 downStream과 KafkaProducer에게 전달해주는 동작을 한다.
tupleForwarder.maybeForwarder()
public void maybeForward(final Record<K, Change<V>> record) {
if (!cachingEnabled) {
if (sendOldValues) {
context.forward(record);
} else {
context.forward(record.withValue(new Change<>(record.value().newValue, null)));
}
}
}TimestampTupleForwarder의 maybeForward() 메서드가 호출된다. 이 때 caching이 가능하지 않은 경우에는 ProcessorContext를 불러와서 downstream으로 메세지를 흘린다. 만약에 caching이 가능한 경우에는 downstream으로 메세지를 보내지않고 return 한다.
@SuppressWarnings("unchecked")
@Override
public void init(final ProcessorContext<KIn, Change<VIn>> context) {
this.context = context;
final StreamsMetricsImpl metrics = (StreamsMetricsImpl) context.metrics();
droppedRecordsSensor = droppedRecordsSensor(Thread.currentThread().getName(),
context.taskId().toString(), metrics);
if (queryableName != null) {
store = context.getStateStore(queryableName);
tupleForwarder = new TimestampedTupleForwarder<>(
store,
context,
new TimestampedCacheFlushListener<>(context),
sendOldValues);
}
}이 cachingEnable은 Node를 초기화할 때 init()가 호출되면서 진행된다. Processor들도 각각 초기화를 하는데 이 때, quaryableName이 있는 경우에는 tupleForwarder가 등록된다. 만약 quaryableName이 없는 경우 tupleForwarder가 등록되지 않기 때문에 ProcessorContext를 이용해서 forward()하게 된다.
TimestampedTupleForwarder(final StateStore store,
final ProcessorContext<K, Change<V>> context,
final CacheFlushListener<K, ?> flushListener,
final boolean sendOldValues) {
this.context = (InternalProcessorContext<K, Change<V>>) context;
this.sendOldValues = sendOldValues;
cachingEnabled = ((WrappedStateStore) store).setFlushListener(flushListener, sendOldValues);
}아무튼 이 때, TupleForwarder가 생성되면서 StateStore가 setFlushListener()로 등록될 때 cachingEnable이 True가 된다. 만약 StateStore가 없다면 QueryableName이 없기 때문에 tupleForwarder가 생성조차 되지 않는다.
commit.interval.ms 관련
int maybeCommit() {
final int committed;
// commit.interval.ms 초과 확인
if (now - lastCommitMs > commitTimeMs) {
committed = taskManager.commit(
taskManager.tasks()
.values()
.stream()
.filter(t -> t.state() == Task.State.RUNNING || t.state() == Task.State.RESTORING)
.collect(Collectors.toSet())
);
if (committed > 0 && (now - lastPurgeMs) > purgeTimeMs) {
// try to purge the committed records for repartition topics if possible
taskManager.maybePurgeCommittedRecords();
lastPurgeMs = now;
}
...
}StreamThread의 maybeCommit()이 호출된다. 여기서 (now - lastCommitMs > commitTimeMs)를 이용해서 interval.commit.ms 시간이 지났는지를 확인한다. 시간이 지났다면 commit 대상이 된다. 따라서 taskManager.commit()을 호출한다.
int commitTasksAndMaybeUpdateCommittableOffsets(final Collection<Task> tasksToCommit,
final Map<Task, Map<TopicPartition, OffsetAndMetadata>> consumedOffsetsAndMetadata) {
int committed = 0;
for (final Task task : tasksToCommit) {
// we need to call commitNeeded first since we need to update committable offsets
if (task.commitNeeded()) {
final Map<TopicPartition, OffsetAndMetadata> offsetAndMetadata = task.prepareCommit();
if (!offsetAndMetadata.isEmpty()) {
consumedOffsetsAndMetadata.put(task, offsetAndMetadata);
}
}
}TaskExecutor() 객체는 StreamTask를 하나씩 불러와서 for문을 돌면서 task.prepareCommit()을 호출한다.
@Override
public Map<TopicPartition, OffsetAndMetadata> prepareCommit() {
switch (state()) {
...
if (commitNeeded) {
...
stateMgr.flushCache();
recordCollector.flush();
...
return committableOffsetsAndMetadata();
} else {
...
}
...
}StreamTask의 prepareCommit() 메서드가 호출된다. StreamTask 단위로 커밋을 준비하는데, 이 때 각 StreamTask가 가지고 있는 StateManager와 RecordCollector가 순차적으로 flush()된다.
StateManager의 Flush()
이 과정은 StateManager가 관리하는 StateStore에 최신 값을 업데이트하고, DownStream에 메세지를 전달해주는 역할을 한다.
public void flushCache() {
if (!stores.isEmpty()) {
for (final StateStoreMetadata metadata : stores.values()) {
final StateStore store = metadata.stateStore;
...
} else if (store instanceof CachedStateStore) {
// Flush 한다.
((CachedStateStore) store).flushCache();
}
...
}StateManager는 StreamTask별로 존재한다. StateManager는 StreamTask의 StateStore를 관리하고 있는데, StreamTask의 모든 StateStore를 불러와서 For 문을 이용해서 flushCache() 메서드를 호출한다. 즉, 일단 해당 StreamTask가 가지고 있는 StateStore의 Flush()를 시도하는 것이다.
@Override
public void flushCache() {
validateStoreOpen();
lock.writeLock().lock();
try {
validateStoreOpen();
context.cache().flush(cacheName);
} finally {
lock.writeLock().unlock();
}
}flushCache()를 하는 과정에서 lock()을 얻어야지 flush()를 할 수 있는 것을 볼 수 있다. 따라서 동시성 문제에서 자유로울 것임을 예상할 수 있다.
public void flush(final String namespace) {
numFlushes++;
final NamedCache cache = getCache(namespace);
if (cache == null) {
return;
}
cache.flush();
if (log.isTraceEnabled()) {
log.trace("Cache stats on flush: #puts={}, #gets={}, #evicts={}, #flushes={}", puts(), gets(), evicts(), flushes());
}
}ThreadCache의 flush()로 넘어온다. 여기서 namespace(StateStore의 이름)에 대응되는 Cache를 가져와서 Flush()하는 작업을 한다.
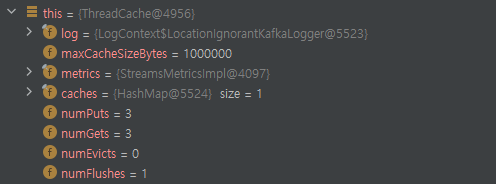
이 때 ThreadCache의 필드 중 maxCacheSizeBytes를 살펴보면 앞서 설정했던 cache.max.bytes.buffering 사이즈와 동일한 것을 확인할 수 있다.
private void flush(final LRUNode evicted) {
final List<ThreadCache.DirtyEntry> entries = new ArrayList<>();
final List<Bytes> deleted = new ArrayList<>();
if (evicted != null) {
entries.add(new ThreadCache.DirtyEntry(evicted.key, evicted.entry.value(), evicted.entry));
dirtyKeys.remove(evicted.key);
}
for (final Bytes key : dirtyKeys) {
final LRUNode node = getInternal(key);
entries.add(new ThreadCache.DirtyEntry(key, node.entry.value(), node.entry));
node.entry.markClean();
if (node.entry.value() == null) {
deleted.add(node.key);
}
}
// clear dirtyKeys before the listener is applied as it may be re-entrant.
dirtyKeys.clear();
listener.apply(entries);
for (final Bytes key : deleted) {
delete(key);
}
}NamedCache 클래스의 flush() 메서드가 호출된다. 이 때, DirtyEntry를 의미하는 entries와 삭제된 deleted 객체가 생성된다. DirtyEntry는 업데이트 되어서 downStream으로 흘러갈 녀석들을 의미한다.dirtyKey가 있는 경우 flushListener에게 dirtyKey를 전달해준다.
private void initInternal(final InternalProcessorContext<?, ?> context) {
this.context = context;
this.cacheName = ThreadCache.nameSpaceFromTaskIdAndStore(context.taskId().toString(), name());
this.context.registerCacheFlushListener(cacheName, entries -> {
for (final ThreadCache.DirtyEntry entry : entries) {
putAndMaybeForward(entry, context);
}
});
}CachingKeyValueStore 클래스의 initInternal() 메서드로 넘어오게 된다. 여기서 entries는 이전 메서드에 전달받은 dirtyKey를 의미한다. 즉, dirtyKey에 대해서 하나씩 putAndMaybeForward()를 처리하는 것을 볼 수 있다.
private void putAndMaybeForward(final ThreadCache.DirtyEntry entry,
final InternalProcessorContext<?, ?> context) {
if (flushListener != null) {
final byte[] rawNewValue = entry.newValue();
final byte[] rawOldValue = rawNewValue == null || sendOldValues ? wrapped().get(entry.key()) : null;
...
wrapped().put(entry.key(), entry.newValue());
flushListener.apply(
new Record<>(
entry.key().get(),
new Change<>(rawNewValue, sendOldValues ? rawOldValue : null),
entry.entry().context().timestamp(),
entry.entry().context().headers()));
...
}CachingKeyValueStore의 putAndMaybeForward() 메서드로 넘어오게 된다. 여기서 먼저 이 행동을 하는 것을 볼 수 있다.
- DirtyKey에서 받아온 값을 newValue()로 불러온다. 즉, DirtyKey는 업데이트 될 NewValue를 의미한다.
- DirtyKey는 LRU Entry를 생성할 때 isDirty 인자로 전달되는데, 이 때 항상 True로 전달된다.
- Dirty라는 것은 프로세서 노드에서 이미 처리된 것을 의미한다. 프로세서 노드에서 처리된 후에 (특정 로직) Cache에 전달된 객체를 의미한다.
- rawNewValue가 존재하지 않거나 sendOldValues가 Flag가 True인 경우에는 rawOldValue의 값을 설정해준다.
- 이 때, CachineKeyValueStore에서 key로 값을 찾아와 OldValue에 넣어준다.
위 두 작업을 통해서 DirtyKey는 최근에 처리되어서 전달된 값을 의미한다. OldValue는 DirtyKey가 도착하기 전에 Cache에 도착해서 CacheStore에 보관되고 있는 옛날 값을 의미한다. 캐싱 관점에서 OldValue은 Compaction 되는 과정이기 때문에 더는 필요없어진다.
- 현재 StateStore에 DirtyKey에서 받은 값을 넣는다. 즉, 최신 값으로 업데이트한다.
- flushListener에게 현재 값을 기준으로 Record를 생성해서 전달해준다. 즉, 최신 값에 대해서 다음 프로세싱을 하라는 의미다.
@SuppressWarnings("unchecked")
@Override
public boolean setFlushListener(final CacheFlushListener<K, V> listener,
final boolean sendOldValues) {
final KeyValueStore<Bytes, byte[]> wrapped = wrapped();
if (wrapped instanceof CachedStateStore) {
return ((CachedStateStore<byte[], byte[]>) wrapped).setFlushListener(
record -> listener.apply(
record.withKey(serdes.keyFrom(record.key()))
.withValue(new Change<>(
record.value().newValue != null ? serdes.valueFrom(record.value().newValue) : null,
record.value().oldValue != null ? serdes.valueFrom(record.value().oldValue) : null
))
),
sendOldValues);
}
return false;
}MeteredKeyValueStore에서는 setFlushListener()를 이용해서 다음 일을 한다.
@Override
public void apply(final Record<KOut, Change<ValueAndTimestamp<VOut>>> record) {
@SuppressWarnings("rawtypes") final ProcessorNode prev = context.currentNode();
context.setCurrentNode(myNode);
try {
context.forward(
record
.withValue(
new Change<>(
getValueOrNull(record.value().newValue),
getValueOrNull(record.value().oldValue)))
.withTimestamp(
record.value().newValue != null ? record.value().newValue.timestamp()
: record.timestamp())
);
} finally {
context.setCurrentNode(prev);
}
}TimestampcacheFlushListener()의 apply 메서드에서는 flush() 해야될 메세지를 전달받는다. 그런데 지금까지 캐싱을 하고 있어서, 캐시에 있던 녀석들은 다른 프로세서에서 처리가 되지 않았다. 따라서 이 때 FlushListener()는 전달받은 메세지를 context.forward()를 통해서 처리한다. 이 때, context는 Processor Context이며, forward()로 호출하게 되면 일반적으로 Stream에 메세지를 전달한 것처럼 하나씩 처리된다.
RecordCollector의 Flush()
@Override
public void flush() {
log.debug("Flushing record collector");
streamsProducer.flush();
checkForException();
}
위는 RecordCollector의 Flush() 함수다. 여기서는 Producer를 호출해서 flush()하는 동작을 한다. 위 flush()를 호출하다보면 kafkaProducer의 flush()를 호출하게 된다.
@Override
public void flush() {
log.trace("Flushing accumulated records in producer.");
long start = time.nanoseconds();
this.accumulator.beginFlush();
this.sender.wakeup();
try {
this.accumulator.awaitFlushCompletion();
} catch (InterruptedException e) {
throw new InterruptException("Flush interrupted.", e);
} finally {
producerMetrics.recordFlush(time.nanoseconds() - start);
}
}위는 kafkaProducer의 flush() 메서드다. 여기서는 accumulator를 beginFlush()를 하고, sender를 wakeup 시킨다.
- Sender는 KafkaProducer가 레코드를 Broker로 보낼 때 사용하는 녀석이다. 내부적으로 NetworkClient를 가지고 있고, 이 녀석을 이용해서 메세지를 보낸다.
- this.accumulator.beginFlush()를 이용해서 accumulator가 가지고 있는 메세지를 직접 보낸다. 이 경우는 recordCollector가 가지고 있는 Cache의 Commit 대상이 되는 녀석이 될 것이다.
위의 작업을 통해서 Commit 되면서 메세지가 flush()될 것이다.
참고
'Kafka eco-system > KafkaStreams' 카테고리의 다른 글
| Kafka Streams : 리파티셔닝의 노드 구성 (0) | 2022.10.30 |
|---|---|
| Kafka Streams : Process 과정에서의 레코드 (0) | 2022.10.30 |
| KafkaStreams : StateStore (0) | 2022.10.24 |
| Kafka Streams : StreamTask가 생성되는 과정 (0) | 2022.10.22 |
| Kafka Streams : Source 토픽에서 메세지 가져오기 (0) | 2022.10.22 |