들어가기 전
이 글은 Kafka Streams와 KsqlDB 정복 5장을 공부하며 작성한 글입니다.
5.0 카프카 스트림즈에서 시간의 의미
카프카 스트림즈에는 세 종류의 시간이 존재한다. Window Join, Window 집계처럼 시간 기반의 연산을 할 때 각각의 시간이 어떤 의미를 가지는지를 이해하고 사용하는 것이 매우 중요하다. 어떤 시간 종류가 있고 각 시간은 어떤 의미를 가질까?

Event Time
- Event Time은 Producer에서 이벤트가 생성된 시간을 의미한다.
- Event Time은 ProducerRecord의 timestamp에 포함될 수 있다.
- Event Time은 ProducerRecord의 Payload의 특정 필드에 포함될 수 있다.
Ingestion Time (Log Append Time)
- Ingestion Time은 Broker에 Event가 Append된 시간을 의미한다.
- Ingestion Time은 EventTime보다 항상 늦다.
- Event Time이 빠른 메세지가 항상 Ingestion Time도 빠르다는 것을 보장하지 않는다.
- 생성은 빨리 되었으나 늦게 도착하는 메세지가 존재할 수 있음.
Processing Time
- Kafka Streams 어플리케이션이 이벤트를 처리하는 순간의 시간을 의미한다.
- 이 시간은 Event time, Processing Time보다 항상 늦다.
- 같은 데이터를 재처리하면 새로운 처리 시간을 생성한다.
5.0.1 레코드의 Timestamp 설정
앞서 이야기 한 것처럼 메세지에는 Event Time / Ingestion Time 두 가지가 존재한다. 어떤 종류의 Timestamp를 사용할지 결정하기 위해서는 Broker의 설정을 수정해야한다. Broker가 참조하는 server.properties 파일 등으로 이동해서 아래 설정값을 수정해주면 된다.
// 브로커 수준
log.message.timestamp.type=CreateTime
// 토픽 수준
message.timestamp.type=LogAppendTime- 메세지의 Timestamp 설정을 CreateTime으로 하면 레코드가 가지는 시간의 의미는 EventTime이 될 것이다.
- 메세지의 Timestamp 설정을 LogAppend로 하면 레코드가 토픽에 추가될 때 마다 브로커는 브로커의 시스템 시간을 Timestamp에 덮어쓴다.
Event Time을 사용하는 것은 좀 더 이벤트의 발생 시간에 가깝게 동작하도록 한다. 예를 들어 Event Time은 빨랐으나 네트워크 문제가 있을 수 있고 (Ingestion Time), 카프카 스트림즈의 복잡한 연산으로 이해 처리가 느려질 수 (Processing Time)이 있기 때문이다.
Processing Time을 사용하는 것은 이벤트를 처리(Process)하는 시간이 이벤트가 발생(Event Time)한 시간보다 더 중요한 의미를 가질 때다.
5.1 Timestamp Extractor
카프카 스트림즈에서 시간 관련 연산을 수행하기 위해서 카프카 스트림즈는 레코드에서 필요한 Timestamp를 추출한다. 이 역할을 인터페이스 TimestampExtractor의 구현체들이 수행한다. 필요한 경우 아래 인터페이스를 직접 구현해서 사용하면 된다.
public interface TimestampExtractor {
// record : 특정 토픽 + 파티션에서의 큐
// partitionTime : 특정 토픽 + 파티션에서 현재까지 관찰된 것중 가장 최근 시간
long extract(ConsumerRecord<Object, Object> record, long partitionTime);
}레코드에게서 Timestamp를 추출하는 작업은 두 가지 단계로 동작한다.
- 먼저 레코드가 가진 Timestamp 필드에서 timestamp를 추출한다.
- 이 때 timestamp가 음수인 경우 유효하지 않은 레코드이기 때문에 Skipping Record가 발생한다.
- 정상적인 레코드라면 이 녀석이 이 파티션에서 가장 최근에 조회된 녀석이기 때문에 Head Record가 된다. Head Record는 나중에 Math.Max(partitionTime, recordToReturn.timeStamp) 메서드를 통해서 해당 파티션의 가장 최근 시간인 partitionTime으로 업데이트 될 수도 있다.
5.1.1 내장 Timestamp Extractor
카프카 스트림즈에서는 몇 가지 Timestamp Extractor를 제공해준다. 필요한 경우 이 Timestamp Extractor를 이용하면 된다.
- FailOnInvalidTimestampExtractor
- EventTime / Ingestion Time을 추출함.
- 유효하지 않으면 Timestamp가 추출되면 StreamException 발생함.
- LogAndSkipOnInvalidTimestampExtractor
- EventTime / Ingestion Time을 추출함.
- 유효하지 않은 Timestamp가 추출되면 Log만 남기고, 이 녀석은 Skipping Record가 된다.
- 카프카 스트림즈는 지속적으로 작업한다.
- WallclockTimestampExtractor
- Processing Time을 추출함.
- 현재 Kafka Streams 인스턴스의 System.currentTimeMillis()를 추출한다.
5.1.2 카프카 스트림즈의 Timestamp Extractor 설정 방법
위에서 카프카 스트림즈는 여러 종류의 Timestamp Extractor가 제공되는 것을 알았다. 그렇다면 이 Timestamp Extractor를 사용하려면 어떻게 해야할까? Default 설정을 바꿔주는 방법과 Stream을 생성할 때 Consumed 객체에 제공해주는 방법이 있다.
// 설정값으로 제공
props.setProperty(StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG, FailOnInvalidTimestamp.class.getName());
// Consumed 객체에 제공
KStream<String, Pulse> pulseStream = streamsBuilder.stream("pulse-events",
Consumed.with(Serdes.String(), pulseSerde, new FailOnInvalidTimestamp(), Topology.AutoOffsetReset.EARLIEST));
KStream<String, Pulse> pulseStream = streamsBuilder.
stream("pulse-events",
Consumed.with(Serdes.String(), pulseSerde)
.withTimestampExtractor(new FailOnInvalidTimestamp()));설정값으로 제공하는 경우, Timestamp Extractor를 별도로 설정해주지 않았다면 카프카 스트림즈 인스턴스 전체에서 설정값에 명시된 Timestamp Extractor를 사용한다. 만약 Consumed.With()로 Timestamp Extractor를 제공한 Stream이 있다면, 이 설정은 설정값으로 제공하는 것보다 더 우선 시 된다.
- 특정 시간동안 발생한 심장 박동 이벤트를 수집해서 초당 얼마나 심장이 뛰었는지를 계산한다.
Timestamp Extractor는 의미를 잘 살려서 사용해야한다. 예를 들어 위 같은 경우에 WallclockTimestampExtractor를 사용하면 잘못된 데이터가 나온다. 만약 이 상황이라면 사용하면 EventTime을 기준으로 1분 동안 발생한 심장 박동 이벤트는 Wallclock 기준으로 1초 안에 발생한 이벤트가 되어버릴 수 있다. 즉, 잘못된 데이터가 될 수 있다.
5.1.3 Custom Timestamp Extractor 구현
추출해야하는 Timestamp가 Payload에 존재한다면 사용자가 직접 Custom Timestamp Extractor를 구현해서 사용해야한다. 카프카 스트림즈가 제공하는 Timestamp Extractor는 Record의 timestamp 필드에 있는 값을 추출하거나 시스템 시간을 사용하기 때문이다.
public class PulseTimestampExtractor implements TimestampExtractor {
@Override
public long extract(ConsumerRecord<Object, Object> record, long partitionTime) {
String timestamp = ((Vital) record.value()).getTimestamp();
SimpleDateFormat recv = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSSX", Locale.ENGLISH);
SimpleDateFormat tran = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.sssss", Locale.ENGLISH);
String date;
try {
Date parse = recv.parse(timestamp);
date = tran.format(parse);
} catch (ParseException e) {
return -1L;
}
return LocalDateTime.parse(date).toInstant(ZoneOffset.UTC).toEpochMilli();
}
}구현할 때 반드시 고려하고 숙지해야하는 것은 두 가지다.
- TimestampExtractor는 밀리 초 단위의 Timestamp 반환을 요구한다. 다른 단위의 Timestamp를 반환할 경우, 정상적으로 동작하는 것처럼 보이지만 실제로는 잘못 동작하고 있다. 예를 들어 윈도우 연산에서 윈도우 시작 / 끝을 보면 원하는대로 설정되지 않는 것을 볼 수 있다.
- Timestamp를 얻지 못했을 때의 예외 처리를 해야한다.
- Exception을 발생시켜 카프카 스트림즈를 중단(개발자가 버그 확인할 수 있도록)
- 음수를 반환하면, Skipping Record가 발생하고 계속 작업 진행함.
- partitionTime(현재 파티션의 가장 최근 시간)을 이용해서 생성
5.2 Stream Windowing
스트림은 끊임없이 들어오는 데이터다. 각각의 데이터의 의미도 있지만 State를 기억해서 문맥을 부여하면 더 좋은 데이터가 될 수 있다. State를 부여하는 방법 중 하나가 Stream Windowing이다. 특정 기간동안(Windowing)을 한 State를 얻는 것이다. 또한 각 Key 별로 Windowing이 되기 때문에 Key를 바라보고 나눌 수 있는 또 다른 관점이 될 수 있다.
5.2.0 윈도우의 종류
카프카 스트림즈에서는 윈도우 연산을 위해서 여러 종류의 윈도우를 제공한다. 각 윈도우가 어떤 특성과 의미를 지니는지 정확히 알고 필요한 상황에 맞게 윈도우를 선택해서 사용해야한다.
- Thumbling Window → Timewindow(클래스)
- Hopping Window → Timewindow(클래스)
- Session Window → Sessionwindow(클래스)
- Sliding join Window → JoinWindow(클래스)
- Sliding Aggregation Window → SlidingWindow(클래스)
5.2.1. Tumbling Window → TimeWindow 클래스
- 한 레코드는 하나의 윈도우에만 포함된다.
- Window Size로 정의됨.
- 윈도우의 단위는 밀리초(millis)다.
- 시간 시간은 포함되지만 종료 시간은 포함되지 않는다.
- 윈도우는 epoch에 맞춰진다.
- 이 말은 첫번째 윈도우가 Timestamp 0에서 시작한다는 것을 의미함.
- 윈도우 크기가 5,000이라면 0 ~ 5,000 / 5,000 ~ 10,000 형태로 윈도우 경계가 생긴다.
- 윈도우의 기준이 EPOCH이 된다.
- https://ojt90902.tistory.com/1136
5.2.2 Hopping Window → TimeWindow 클래스
- 한 레코드는 여러 윈도우에 포함될 수 있음.
- Window Size / Advance Interval로 정의됨
- 윈도우는 epoch에 맞춰진다.
- 윈도우의 기준이 EPOCH이 된다.
https://ojt90902.tistory.com/1136
5.2.3 Session Window → SessionWindow 클래스
- 비활동 기간 + Grace Period로 결정된다.
- 현재 레코드의 timestamp ± 비활동 기간의 구간으로 StateStore를 검색해서 Window가 있는 경우 Window에게 합쳐진다.
- Window의 크기는 정해져있지 않다. 메세지가 활발히 들어오면 Window의 크기는 무한히 커진다.
- 윈도우의 기준이 레코드가 된다.
https://ojt90902.tistory.com/1135
5.2.4 Sliding Join Window → JoinWindow 클래스
- 슬라이딩 조인 윈도우는 고정 길이의 윈도우다.
- 슬라이딩 조인 윈도우는 조인할 때 사용되는 윈도우다.
- 생성은 JoinWIndows로 생성한다.
- Stream과 Stream을 Join할 때 사용한다.
- 현재 레코드의 Timestamp ± Join Window 크기 구간을 상대쪽 StateStore(WindowStateStore)에서 검색하고, 이 구간에 있는 레코드들을 모두 불러와서 Join하면서 Donwstream으로 데이터를 보낸다.
- Join해서 생성된 메세지의 Timestamp는 Left, Right 중 Timestamp가 큰 녀석의 것으로 결정된다.
- 윈도우의 기준이 레코드가 된다.
https://ojt90902.tistory.com/1128
5.2.5 Sliding Aggregation Window → SlidingWindows
- Sliding Aggregation Window는 집계에도 사용할 수 있음.
- 윈도우의 기준이 레코드가 된다. 레코드의 타임 스탬프 기준으로 윈도우가 설정됨.
5.2.6 윈도우 집계
기본적인 집계는 한 Key의 상태를 기억하고 그곳에 집계를 계속하는 것이다. 윈도우 집계는 한 Key의 상태를 여러 Window로 나누고 그 Window의 상태를 기억하고 집계하는 것이다. Window를 사용하는 집계와 아닌 집계의 차이는 아래에서 확인할 수 있다.
KGroupedStream<String, Pulse> groupedStream1 = pulseStream.groupByKey();
// 윈도우 사용하지 않은 집계 → Key값이 String임.
KTable<String, Long> count = groupedStream1.count();
TimeWindows timeWindows = TimeWindows.ofSizeWithNoGrace(Duration.ofSeconds(60));
// 윈도우 사용한 집계 → Key값이 Windowed<String>임.
KTable<Windowed<String>, Long> count1 = groupedStream1.windowedBy(timeWindows).count();위에서 이야기 한 것처럼 일반 집계는 Key로만 상태를 기억하고, 윈도우 집계는 Key의 하위 집합으로 Window까지 고려해서 함께 상태를 기억한다는 점이다. Windowed 클래스는 Wrapper 클래스로 Key와 Window를 함께 나타내는 것을 볼 수 있다.
public class Windowed<K> {
private final K key;
private final Window window;
}윈도우 집계 중간 결과
윈도우 집계는 어떤 StateStore를 쓰느냐에 따라 다르긴 하지만 중간 결과, 혹은 매 레코드를 Downstream으로 내려보낸다. 예를 들어 아래 로그를 살펴보면 동일한 Window 기간에서 ID 1을 가지는 녀석의 Count가 1 → 2로 증가하는 것을 볼 수 있다. 이런 중간 결과는 좋지 않은 문제를 만들 수도 있기 때문에 완결된 Window만 보고 싶을 수 있다. 그것은 아래에서 알아보기로 하고 여기서 알아두고 넘어가야 할 부분은 Window 집계는 중간 결과를 생성해서 Downstream으로 내려주어 불명확한 Context를 보여줄 수 있다는 점이다.
[[HELLO]]: [0@1670822100000/1670822160000], 1
[[HELLO]]: [1@1670822100000/1670822160000], 1
[[HELLO]]: [1@1670822100000/1670822160000], 2
[[HELLO]]: [0@1670822100000/1670822160000], 1
[[HELLO]]: [1@1670822100000/1670822160000], 1
[[HELLO]]: [0@1670822100000/1670822160000], 1
5.3 윈도우의 유예 기간과 중간 결과 제거
카프카 스트림즈는 Timestamp가 아니라 Record의 Offset을 기준으로 처리한다. 이 말은 카프카 스트림즈로 공곱된 일련의 메세지 덩어리들이 Event Time 순서대로 정렬되어있지 않음을 의미한다. 그렇다면 왜 이런 결과가 나타나게 되는 것일까? 이것은 이벤트들이 가끔씩 지연되기 때문이다.

환자1, 환자2에는 심장박동이 발생하면 Event가 발행되어 Broker에게 메세지를 전달해주는 기계가 있다. 그런데 이 때 환자2의 기계에 네트워크 문제가 발생해서 일정 기간동안 데이터 공급이 늦어졌다고 가정해보자. 이 경우 환자2에게서 발생한 이벤트는 환자1보다 빠르지만 Broker에 저장된 Offset은 더 늦어지게 된다. 따라서 발행된 이벤트가 Broker 내에서 Timestamp 순으로 정렬되는 것이 보장되지 않는다.
이처럼 데이터는 Timestamp 순으로 들어오지 않는다. 이 부분은 윈도우 연산을 할 때 더 중요 시 여겨야 한다. 현재 들어온 메세지가 윈도우의 끝인지 아닌지를 판별할 수 없기 때문이다. 위와 같이 네트워크 지연이 된 경우 때문에 Timestamp는 이르지만 Offset이 뒷쪽에 있는 경우가 있다. 따라서 뒷쪽에 들어오는 메세지가 실제 발생 시점은 현재 이벤트보다 더 빠를 수 있기 때문에 Event의 끝이 어디인지 알 수 없다는 것이다.
카프카 스트림즈는 이 문제를 지속적 정제(Continuous refinement) 방식으로 해결했다 (https://oreil.ly/-tii3). 지속적 정제는 새 이벤트가 윈도우에 추가될 때마다 카프카 스트림즈는 이 이벤트로 계산을 하고, 계산 결과를 즉시 Donwstream으로 내려보낸다. 카프카 스트림즈가 이런 정제 전략을 선택했기 때문에 중간 연산 결과를 계속 관찰할 수 있게 된 것이다. 그렇다면 최종 연산 결과만 볼 수 있는 방법은 없을까?
5.3.1 유예 기간 (Grace Period Time)
Grace Period Time은 지연된 데이터를 받아주는 시간을 의미한다. 예를 들어 Event 발행 시간은 윈도우 안에 들어올 수 있지만, 이 메세지가 윈도우 Processor에 도착한 시간이 늦어지는 경우가 존재할 수 있다. 이 때 Grace Period Time은 이 메세지가 늦게 도착했더라도 Window에 포함될 수 있도록 해준다.
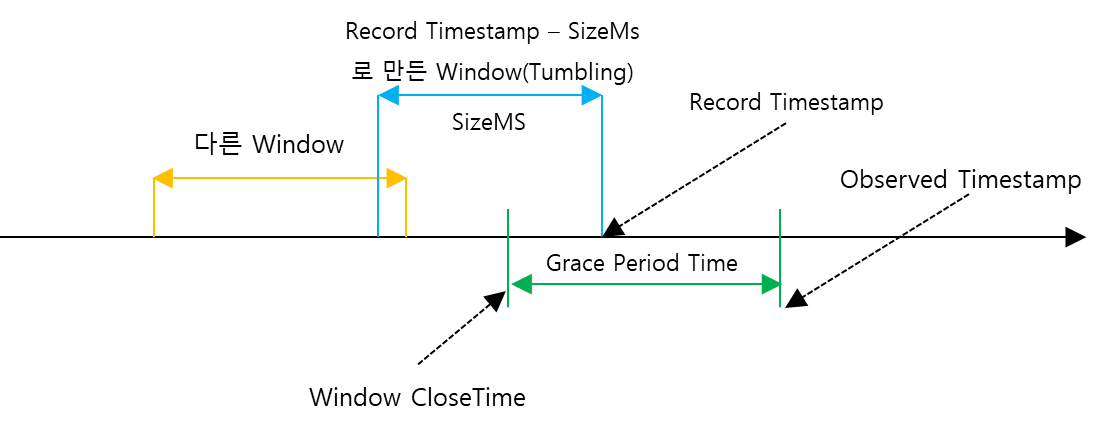
Window 연산을 할 때, Record가 관찰된 시간을 기준으로 SizeMs만큼을 Window 구간으로 Window를 생성한다. 그리고 Overserved Timestamp(RecordTimestamp, Overserved Timestamp 중에서 큰 값, 즉 대부분 프로세스에 데이터가 도착한 시간)에서 GracePeriod를 뺀 값으로 Window Close Time을 구한다. 만약 생성된 Window의 Endtime이 Window CloseTime보다 늦다고 하면 생성된 Window는 닫혀진 Window가 아니게 된다. 따라서 이 Window는 Close된 Window가 아니기 때문에 Window StateStore에서 Window Aggregator를 찾아와서 집계 연산을 하면 된다. 지금은 Tumbling Window + 긴 Grace Period Time을 봤기 때문에 저게 무슨 소용일까? 라는 생각이 들 것이다.
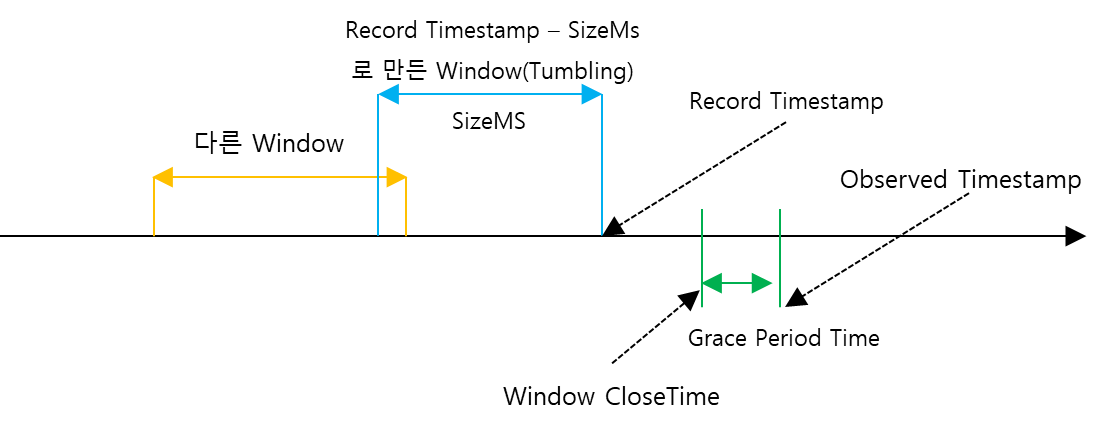
예를 들어서 위 경우라면 바로 이 Record는 Skipping Record가 되어 버려진다. 왜냐하면 현재 Record Timestamp으로 만들어진 Window는 Window Close Time보다 앞에 있고 이것은 이 메세지가 연산되어야 할 Window가 Close 된 것을 의미하기 때문이다.
이처럼 Grace Period Time을 이용하면 버려질뻔한 메세지도 살릴 수 있다. 즉 완결성을 가져갈 수 있다. 그렇지만 메세지의 완결까지 Grace Period Time만큼 기다려야 하기 때문에 Latency가 길어지는 단점이 있다.
TimeWindows.ofSizeAndGrace(
Duration.ofSeconds(10),
Duration.ofSeconds(1));Grace Period Time을 어떻게 줄지는 Window를 생성할 때 인자로 전달할 수 있다.
5.3.2 중간 결과 제거
카프카 스트림즈는 지속적 정제(Continuous Redefine)을 하기 때문에 중간 연산 결과는 끊임없이 Donwstream으로 전달된다. 완결성은 부족하지만 Latency 관점에서는 훌륭하다. 그런데 만약 지연 시간이 길어도 괜찮으니 연산이 완료된 결과만 보고 싶다면 어떻게 해야할까? suppress 연산자를 사용하면 된다. supress 연산자는 Window 연산의 최종 계산 결과만을 내보내고 불필요한 데이터를 제거할 때 사용할 수 있다. 이 때 결정해야 할 것은 세 가지다.
- 윈도우 중간 계산 결과를 제거할 때 사용할 제거 전략
- 제거할 이벤트를 버퍼링하는 메모리의 양
- 버퍼 메모리 제한량을 초과했을 때 해야할 일
아래에서 각각 해야할 일들에 대해 알아보자.
윈도우 중간 계산 결과 제거 전략 선택
| 전략 | 설명 |
| Suppressed.untilWindowCloses | 윈도우의 최종 결과만 Downstream으로 전달함. |
| Suppressed.untilTimeLimit | 1. 첫번째 메세지를 받은 후, 특정 시간동안 기다림. 2. 그 시간동안 다른 메세지가 오면 버퍼에 있는 첫번째 이벤트를 교체함. 교체하더라도 타이머는 리셋되지 않음. 3. 특정 시간이 지나면 Buffer Flush 함. 4. 다시 타이머를 리셋함. |
기본적으로 메모리에 메세지를 버퍼링 한 후에 필요한 결과만 내보내는 작업을 한다. 메모리에는 동일한 Key에 대해서 최신 레코드를 유지하는 작업을 한다. 만약 Key가 다양하게 존재한다면 버퍼의 메모리 공간을 많이 차지할 것이다. 따라서 Suppress를 사용하다면 메모리 버퍼를 얼마나 사용할지도 설정해줘야한다.
메모리 버퍼값 설정하기
| 버퍼 설정 | 설명 |
| BufferConfig.maxBytes() | 메모리 버퍼를 최대 보관 가능한 Bytes 용량으로 컨트롤 한다. |
| BufferConfig.maxRecords() | 메모리 버퍼를 최대 보관할 레코드의 숫자로 설정한다. |
| BufferConfig.unbounded() | 이 설정을 이용하면 가능한 많은 Heap 메모리를 사용한다. 만약 Application이 Heap을 다 사용하면 OOM이 발생한다. |
maxBytes(), maxRecords()로 메모리 버퍼 설정을 하게 되면 언젠가는 Buffer가 설정값을 넘게 가득 채우는 경우가 있을 수 있다. 이런 경우가 발생한다면, 이 경우를 어떻게 처리해야할지도 함께 정의해줘야한다.
버퍼가 가득 찼을 때 행동 설정
| 버퍼 풀 전략 | 설명 |
| shutDownWhenFull | 버퍼가 꽉 차면 어플리케이션을 Graceful하게 종료함. 이 전략을 사용하면 중간 결과를 볼 수 있는 가능성이 줄어든다. |
| emitEarlyWhenFull | 버퍼가 꽉 차면 가장 오래된 결과(일찍 들어온 결과)를 Flush 한다. 이 전략을 사용하면 중간 윈도우 연산 결과를 볼 수 있다. |
Buffer가 가득차면 어떤 행동을 해서 그 상태를 해소해줘야한다. Graceful하게 종료하는 것이 항상 나쁘지만은 않다. 예를 들어 심박수를 계산하는 어플리케이션을 만들고 있고, 메세지를 버퍼링 하다가 60초마다 한번씩 심박수를 계산한 결과를 보내줘야한다. 이 때 메모리가 30초만에 가득찼을 때, 중간 연산 결과를 downstream으로 보내준다면 부정확한 결과가 전달되면서 상황이 악화될 수 있다. 따라서 비지니스 로직에 맞는 녀석을 잘 사용해야한다.
countWindow
.suppress(
Suppressed.untilWindowCloses(
Suppressed.BufferConfig.unbounded().shutDownWhenFull()));결론적으로는 다음과 같은 형태로 코드를 구성해볼 수 있게 된다.
5.4 윈도우의 키 재생성 + 팁
아래 코드를 보면 윈도우 집계 연산의 결과로 Key가 Windowed<String>으로 바뀌었다는 것을 알 수 있다. 이 말은 기존에 Grouping 했던 Key들을 시간 Window로 한번씩 더 하위 Grouping 된 것을 의미한다. 만약 이 집계를 다른 녀석과 Join을 해야한다면 다시 한번 키를 생성해야한다.
KTable<Windowed<String>, Long> countWindow = timeWindowedKStream.count(Materialized.as(
Stores.persistentWindowStore("pulse-count", Duration.ofSeconds(60), Duration.ofSeconds(60), true)));키를 생성하기 전에는 할 수 있다면 반드시 필터링 작업을 한다. 필터링 작업을 해서 Downstream으로 전달되는 레코드 수를 줄여줘야한다. 레코드 수가 줄어들게 되면 Repartition Internal Topic으로 전달되는 Read / Write 행위를 줄여서 Application의 성능을 개선할 수 있기 때문이다. 따라서 다음 순서로 코드를 작성해 볼 수 있다.
KStream<String, Long> highPulse = suppress.toStream()
.filter((key, value) -> value > 100)
.map((key, value) -> KeyValue.pair(key.key(), value));value > 100인 녀석들만 먼저 필터링을 하게 되면 downstream으로 전달되는 레코드가 줄어들어서 map() 연산의 비용을 조금 더 줄여볼 수 있다.
5.6 Window Join
Stream끼리 Join을 하기 위해서는 Window Join을 해야하고, Window Join에는 JoinWindows 객체가 필요하다. 왜냐하면 Stream은 무한하기 때문에 무한한 녀석들끼리 Join을 할 수 없다. 따라서 약간의 제약 사항을 위해서 JoinWindow를 넣어줘야한다. JoinWindows 객체는 기본적으로는 다음 방식으로 동작한다
- Stream-Stream Join을 하게 되면 KStreamJoinWindow Processor가 생기게 되고 이 녀석은 각각 StateStore를 가진다.
- Record가 KStreamJoinWindow의 downstream으로 전달되서 KStreamKStreamJoin Processor에게 전달된다.
- KStreamStreamJoin은 반대편 JoinWindow에 있는 StateStore 현재 Record의 Window + Key를 기준으로 검색한다.
- Window에 포함되어 있는 Value들을 Join한 후 Downstream으로 보낸다. 이 때 여러 Value가 찾아지면, 1:N 레코드가 생성되어 DownStream으로 전송된다.
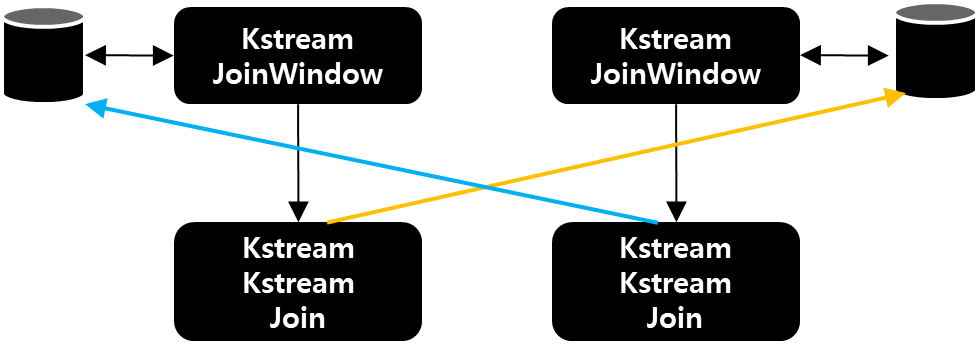
Window Join을 위해서는 다음과 같이 코드를 작성할 수 있다.
// TimeWindow 설정
TimeWindows timeWindows = TimeWindows.ofSizeWithNoGrace(Duration.ofMinutes(1));
// ValueJoiner 설정
ValueJoiner<String, String, CustomTestJoiner> valueJoiner = CustomTestJoiner::new;
// JoinStream 생성
KStream<String, CustomTestJoiner> joinedStream = topicA.join(topicB, valueJoiner, joinWindows,
StreamJoined.with(Serdes.String(), Serdes.String(), Serdes.String()));
5.7 카프카 스트림즈의 입력 스트림 동기화 (시간 기반 데이터 흐름)
카프카 스트림즈는 여러 소스로부터 메세지를 Consume해서 Stream Processing을 한다. 이 때, 데이터의 정합성을 위해서는 여러 소스로부터 온 메세지의 StreamTime을 동기화 하는 것이 중요하다. 카프카 스트림즈는 Stream의 시간 동기화를 위해서 PartitionGroup을 생성하고 Partition Group의 우선순위 큐를 이용한다.
- PartitionGroup은 각 StreamTask마다 생성된다.
- PartitionGroup은 우선순위 큐를 가지고 있고, 우선순위 큐에는 여러 소스에서 들어온 레코드들이 저장된다.
- Stream Task는 메세지를 뽑을 때, Partition Group의 우선순위 큐에서 시간 상 가장 빠른 레코드를 가져와서 Donwstream으로 전달한다.
하나의 Partition Group에는 여러 TopicPartition Record들이 있을 것이고, 각 Topic Partition의 Head Record를 비교해서 시간이 가장 빠른 녀석만 내려보낸다. 아래 내용을 살펴보면 더 간단하게 상황을 정의할 수 있다. 카프카 스트림즈는 다음 상황으로 각 소스의 스트림을 동기화한다.
- 같은 TopicPartition의 레코드들은 Offset에 맞춰서 내려간다.
- 서로 다른 TopicPartition의 레코드들 중에서 뭐가 먼져 빠져나갈지는 Timestamp가 빠른 녀석을 기준으로 설정한다.

집계 연산 참고
- 집계 연산은 aggregate, reduce, count 등으로 할 수 있다.
- Topology에서는 KTable이 생성된다.
- 실제 동작하는 ProcessorNode의 Processor는 다음과 같다.
- KStreamAggregate
- KStreamWindowAggregate
- KStreamSlidingWindowAggregate
- KStreamSessionWindowAggregate
store.put(record.key(), ValueAndTimestamp.make(newAgg, newTimestamp), windowStart);
maybeForwardUpdate(record, entry.getValue(), oldAgg, newAgg, newTimestamp);위 메서드는 Aggregate 클래스의 마지막 부분에 공통으로 있는 메서드다. 이 때 두 메서드는 어떤 종류의 StateStore를 사용하느냐에 따라 다르게 동작한다.
CacheStateStore를 사용하는 경우는 다음과 같이 동작한다.
- maybeForwardUpdate에서는 어떠한 레코드도 DownStream으로 전달되지 않는다.
- store.put()에서 In-memory NamedCache에 저장할 때, Cache의 용량이 가득차거나 Interval이 다 되면 각 Cache의 레코드를 Downstream으로 보내준다.
반면 PersistentStateStore를 사용하는 경우는 다음과 같이 동작한다.
- store.put()에서는 RocksDB에 레코드를 저장하기만 한다.
- maybeForwardUpdate()에서는 매번 레코드가 downStream으로 전달된다.
이런 형태로 동작하기 때문에 처음 카프카 스트림즈를 사용하는 사람들이 "왜 Window 전인데 데이터가 나오죠?"라고 이야기를 한다. Downstream으로 내려온 녀석들을 Window Size에 맞게 잘 처리하면 Suppress 메서드를 이용해야한다.
StreamTime
- StreamTime은 기존에 알고 있던 Timestamp와는 다른 개념이다.
- StreamTime은 특정 토픽 파티션에서 관찰된 시간들 중 가장 큰 값이다.
- 이 값은 초기에는 알 수 없으므로 증가하거나 값을 유지한다. 새로운 데이터가 들어올 때만 값을 전진ㅅ이킨다.
Suppressor
KTableSuppressProcessorSupplier가 제공된다.
'Kafka eco-system > KafkaStreams' 카테고리의 다른 글
| Kafka Streams와 ksqlDB 정복 : Processor API (7장) (0) | 2022.12.20 |
|---|---|
| Kafka Streams와 ksqlDB 정복 : 고급 상태 관리 (6장) (0) | 2022.12.20 |
| Kafka Streams와 ksqlDB 정복 : 상태가 있는 처리 (4장) (1) | 2022.12.20 |
| Kafka Streams와 ksqlDb 정복 : 상태가 없는 처리 (3장) (0) | 2022.12.20 |
| Kafka Streams와 ksqlDB 정복 : 카프카 스트림즈 시작하기 (2장) (0) | 2022.12.20 |