들어가기 전
이 글은 카프카 스트림즈와 ksqlDB 정복 Chapter6을 보고 공부하며 정리한 글입니다.
6. 고급 상태 관리
State Store를 처음에 쓸 때는 아주 편리하다 생각한다. 그렇지만 어플리케이션의 규모가 커져서 유지보수를 반복 수행할수록 Stateful 스트림 어플리케이션을 안정적인 운영에는 State Store 내부 동작에 대한 깊은 이해가 필요하다. 이 글을 통해서 State Store에 대해 보다 깊게 이해할 수 있게 될 것이다. 이 장에서는 아래 내용을 공부한다.
- 영구적인 저장소는 디스크에 어떻게 표현되는가?
- Stateful한 어플리케이션의 Fault Tolerance는 어떻게 구현되는가?
- StateStore는 어떻게 설정하는가?
- Stateful 어플리케이션에 가장 큰 영향을 미치는 사건은 무엇인가?
- 어떻게 Stateful Task의 복구 시간을 최소화 할 수 있는가?
- StateStore가 무한정 커지지 않게 하는 방법은 무엇이 있는가?
- 어떻게 DSL 캐시로 하위 스트림 업데이트 속도를 제한할 수 있는가?
- State Restore Listener로 어떻게 복구 진행 상황을 추적할 수 있는가?
- StateListener로 어떻게 리밸런싱을 감지할 수 있는가?
Persistent StateStore 는 디스크에 어떻게 표현되는가?
Kafka Streams는 In-memory StateStore / Persistent StateStore를 제공한다. 두 가지 StateStore는 모두 ChangeLog(내부 토픽)이 생성된다. 그렇지만 Persistent StateStore만 카프카 스트림즈 인스턴스의 Local에 RocksDB로 데이터를 함께 저장해둔다. Persistent StateStore는 장애 복구 시, 어플리케이션의 복구 시간을 줄여주므로 일반적으로 많이 선호된다.
| RocksDB 생성 여부 | ChangeLog 토픽 생성 | |
| In-Memory StateStore | X | O |
| Persistent StateStore | O | O |
아래에서 볼 수 있듯이 Persistent StateStore를 사용하면 로컬 스토리지에는 다음과 같이 rocksDB를 이용한 로컬 저장소가 생긴다. 반면 In-Memory StateStore를 사용하면 아래 구조는 생기지 않는다.
my-kafka-test // 1번
├─0_0
├─0_1
├─0_2
├─1_0
│ └─hello-store.position
│ └─hello-store2.position
│ └─rocksdb
│ └─hello-store
│ └─LOCK
│ └─0000000000000000.log // 6번
│ └─hello-store2
│ └─LOCK
│ └─0000000000000000.log
├─1_1
│ └─hello-store.position
│ └─hello-store2.position
│ └─rocksdb
│ └─hello-store
│ └─LOCK
│ └─hello-store2
│ └─LOCK
├─1_2 // 2번
│ └─hello-store.position // 4번
│ └─hello-store2.position // 4번
│ └─rocksdb
│ └─hello-store // 3번
│ └─LOCK // 5번
│ └─hello-store2 // 3번
│ └─LOCK위 폴더 구조를 바탕으로 내용을 정리하면 다음과 같다.
- StateStore가 저장되는 폴더의 최상위 이름은 Application ID가 된다. 이것을 통해 서버에서 어떤 어플리케이션이 실행되는지 알 수 있다.
- Application ID 폴더 아래에 각 StreamTask에 대한 폴더가 생성된다. 각 StreamTask의 이름으로 폴더가 생성되며, 각 StreamTask의 이름은 <서브 토폴로지 ID>_<파티션>으로 구성된다.
- 각 StreamTask 폴더 아래에는 rocksDB 폴더가 생기고, 그 폴더 아래에는 각 StreamTask가 가지고 있는 StateStore 폴더가 각각 생성된다.
- 각 StreamTask 폴더에는 StateStore에 대응되는 체크 포인트가 존재한다. 이 체크포인트는 장애를 복구할 때, 좀 더 빠르게 복구할 수 있도록 도와준다. 체크포인트에는 이 StateStore에 대응되는 변경 로그 토픽의 오프셋이 저장된다. 카프카 스트림즈가 변경 로그 토픽을 어디까지 로컬 저장소로 읽어왔는지를 알려준다. 체크포인트가 존재하면, 카프카 스트림즈는 restore 할 때 체크 포인트의 offset 이후부터 값을 읽어온다.
- LOCK은 카프카 스트림즈가 StateStore 디렉토리의 락을 얻을 때 사용한다.
- ChangeLog에서 읽어온 값을 세그먼트에 저장한다. 기본적으로 이 녀석이 있는 폴더 내부에 StateStore의 상태가 모두 저장된다.
여기서 중요한 부분은 LOCK, CheckPoint 부분이다. 몇몇 에러들이 이 파일들을 참조하기 때문이다. 예를 들어 CheckPoint 파일에 값을 기록해야하는데 쓰기 권한이 없어서 에러가 발생하거나, 카프카 스트림즈가 Lock을 얻는데 실패할 경우 에러가 발생하는데 이 때 이 파일들을 참조하게 된다.
Fault Tolerant
카프카는 분산 시스템이 고장났을 때를 대비하기 위해서 파티션을 복제한다. 예를 들어 리더 파티션의 브로커에 장애가 발생했을 경우, 주키퍼는 이것을 감지한다. 브로커의 컨트롤러는 주키퍼를 Watch하다가 이상 발생을 눈치채고 새로운 리더 파티션을 선출하면서 Fault Tolerant를 구성한다. 카프카 스트림즈는 분산 시스템에서의 Fault Tolerant를 구현하기 위해서 아래 두 가지 방법을 이용한다.
- Change Log
- Standby Replicas
아래에서는 이 부분에 대해서 좀 더 자세히 살펴보고자 한다.
Fault Tolerant - ChangeLog
선요약하면 다음과 같다.
- ChangeLog는 <Application ID>-<StateStore 이름>-changelog로 생성된다.
명시적으로 비활성화 하지 않는 이상 카프카 스트림즈는 ChangeLog 토픽을 생성하고 이 토픽을 이용해서 StateStore를 백업한다. ChangeLog 토픽은 주로 두 가지 작업의 대상이 된다.
- StateStore에서 발생하는 모든 키의 변화를 ChangeLog에 저장한다.
- StateStore를 복원할 때, ChangeLog를 Kafka Streams로 Replay해서 복원한다.
- 전체 상태를 잃어버리면 ChangeLog의 처음부터 replay한다.
- In-memory StateStore는 항상 처음부터 replay한다.
- persistent StateStore는 RocksDB의 Checkpoint 이후로 replay한다. 만약 이 내용이 다 사라졌다면, 역시 처음부터 replay한다.
- 만약 StateStore의 Check Point(ChangeLog를 어디까지 로컬에 저장했는지)가 있다면, 그 이후부터 replay한다.
- 전체 상태를 잃어버리면 ChangeLog의 처음부터 replay한다.
Fault Tolerant - Standby Replicas
Stateful 어플리케이션의 장애 복구를 위해서는 State를 복구해줘야한다. ChangeLog에 있는 값을 읽어와서 처리하는 방법도 있지만 읽어야 할 ChangeLog가 많다면 오랜 시간이 필요하다. 또 다른 방법 중 하나는 StateStore의 복제본을 생성해 다른 카프카 스트림즈 인스턴스에 저장해두고, 장애가 발생하면 바로 이 녀석을 쓰는 것이다.
StateStore의 복제본이 생성된다면 카프카 스트림즈는 장애가 발생했을 때, StateStore 복제본이 있는 Task를 Hot Standby 인스턴스로 재할당하고자 '시도'한다. 이것이 성공한다면 ChangeLog를 처음부터 읽어오지 않아도 되기 때문에 State가 큰 어플리케이션의 다운타임을 극적으로 줄여준다. StateStore의 Standby는 아래 명령어를 이용해서 설정할 수 있다.
props.setProperty(StreamsConfig.NUM_STANDBY_REPLICAS_CONFIG, "10");
리밸런싱
ChangeLog, StandbyTask는 StateStore의 장애 복구에 도움을 주는 녀석들이다. 카프카 스트림즈는 이 녀석들을 이용해서 Fault Tolerant 기능을 가지긴 하지만 StateStore의 유실은 일어날 수 있다. StateStore의 유실이 일어나면 State가 Restore 될 때까지 카프카 스트림즈는 다운된다. 복구해야 할 StateStore의 사이즈가 크다면 StateStore가 복구될 때까지는 몇 시간이 소요될 수도 있다. State 유실은 주로 'Consumer의 리밸런싱' 단계에서 일어날 가능성이 크다.
Group Coordinator : Consumer Group의 Consumer를 관리하는 특정 브로커다. 주로 Consumer에게 Heartbeat를 수신 받고, 이상이 발생한 경우 탐지해서 처리한다.
Group Leader : Consumer Group의 리더다. 이 녀석은 파티션 할당을 책임지는 특정 Consumer다.
카프카 스트림즈 인스턴스가 새로 들어와서 리밸런싱이 발생한다면 Stateful Task가 다른 Kafka Streams로 이동할 수 있다. 이동된 Kafka Streams에 State가 존재하지 않았다면, ChangeLog에서 모든 토픽을 다시 읽어와야하기 때문에 State Restore에 많은 시간이 필요해진다. 이런 사태를 막기 위해서는 두 가지 전략이 필요하다.
- 가능하면 상태가 이동하지 않게 막기
- 상태를 이동하고 재생해야 한다면, 가능한 복구 시간을 짧게 만들기
다행스럽게도 카프카 스트림즈는 위 내용을 지원한다.
리밸런싱 - State Movement 최소화
Stateful Task가 다른 카프카 스트림즈로 재할당되면, StateStore도 같이 이동되어야한다. StateStore가 이동되려면 ChangeLog에서 Log Replay를 해야하기 때문에 매우 오랜 시간이 필요하다. 따라서 가능하면 불필요한 Stateful Task의 이동은 방지해야한다. 불필요한 Stateful Task 이동 방지를 위해서 Kafka Streams는 StickyTaskAssignor를 제공한다.
일반적인 TaskAssignor
일반적인 TaskAssignor를 이용했을 때, 리밸런싱을 고려해보면 아래와 같다. 동그라미는 Stateless task, 네모는 Stateful Task다.
- 카프카 스트림즈 인스턴스가 하나 죽는다.
- 카프카 스트림즈가 하나 죽으면서 담당하던 Stateless Task 2개를 처리할 녀석이 필요해졌다. 따라서 리밸런싱이 진행되어야 한다.
- 리밸런싱이 진행될 때, 모든 카프카 스트림즈 인스턴스가 가지고 있던 Task는 할당이 해제된다.
- 리밸런싱이 진행이 완료되었다. 리밸런싱 결과 Stateful Task는 다른 카프카 스트림즈로 이동하게 되었다.
4번의 동작 때문에 카프카 스트림즈 인스턴스는 ChangeLog 토픽에서 StateStore를 복구하기 위해서 Log를 Replay하게 된다. 따라서 이 때, 리밸런싱 완료에 필요한 비용이 Stateful Task가 옮겨가지 않는 상황보다 훨씬 많아진다. 이런 부분을 방지하기 위해 Kafka Streams는 StickyTaskAssignor를 지원한다.

StickyTaskAssignor
카프카 스트림즈에는 StickyTaskAssignor가 포함되어있다. 이 녀석은 어떤 카프카 스트림즈 인스턴스가 어떤 Task를 가졌었는지를 기억해둔다. 리밸런싱이 일어나면, 원래 Task를 가지고 있던 인스턴스에게 Task를 재할당해서 불필요한 Task의 이동을 방지해준다. 불필요한 Task의 이동을 방지하게 되면 StateStore의 이동이 최소화 되기 때문에 State Restore에 필요한 시간이 최소화된다.
StickyTaskAssignor는 기본적으로 리밸런싱 동작을 할 때, 가지고 있는 자원을 모두 포기하기는 하지만 리밸런싱을 할 때 이전에 카프카 스트림즈가 가지고 있었던 Task를 기억하고 있고, 이걸 최대한 유지하도록 다시 리밸런싱한다. 중요한 내용은 가지고 있는 자원을 일시적으로 모두 포기한다.
Static Membership
카프카 스트림즈 인스턴스가 StickyAssignor를 이용해서 최대한 상태를 유지한다고 하더라도, 특정 Kafka Streams 인스턴스는 일시적으로 오프라인 상태가 될 수 있다. Kafka Streams가 온라인으로 돌아오게 되면, 각 Kafka Streams가 가지고 있는 Consumer들의 Consumer Group ID(멤버 ID, Consumer가 등록될 때 코디네이터가 부여하는 고유 식별자)는 모두 초기화된다. 이 경우, Coordinator는 새로운 컨슈머가 들어온다고 판단하고 새 멤버로 취급되어 작업을 재할당 받을 것이다.
이것을 방지하기 위해 Static Membership을 사용할 수 있다. Static Membership은 하드코딩으로 고정된 Consumer Member ID를 사용한다. 이렇게 설정할 경우, 카프카 스트림즈가 재기동되는 상태에도 동일한 Consumer Member ID를 유지하기 때문에 이전의 작업을 그대로 이어받을 수 있을 것이다. 즉, 리밸런싱이 일어나지 않는다.
Static Membership은 큰 session.timeout.ms와 사용된다. session.timout.ms는 heartbeat을 기다리는 최대 시간인데, 이 시간 내에 Static Membership이 재기동되어서 heartbeat을 보낼 수 있다면 코디네이터는 리밸런싱을 동작하지 않는다. 그렇지만 이 부분은 조심히 사용해야하는데, 재기동이 아니라 실제로 Kafka Streams가 죽은 상태라면 장애를 감지하는 시간이 그만큼 늦어진다는 것을 의미한다.
리밸런싱 영향 줄이기
Static Membership을 이용해서 리밸런싱을 최대한 줄일 수는 있지만, 정말로 장애가 발생해서 리밸런싱이 필요한 상황이 올 수 있다. 이 때는 리밸런싱의 영향을 최대한 줄이는 방법이 필요하다. 리밸런싱은 Eager / Cooperative Protocol로 각각 나누어지는데 Eager Protocol은 리밸런싱이 발생할 때 성능에 영향을 준다.
Eager Protocol은 Stop the world가 발생한다. 이 현상은 가지고 있는 모든 자원을 할당 해제하는 것을 의미하는데, 이 기간동안 Kafka Streams는 동작하지 않는다.
Eager Protocol 수행 중, Stateful Task가 다른 카프카 스트림즈 인스턴스에 배정된다면 State Restore가 필요하기 때문에 많은 복구 시간이 필요하다. 그렇지만 이 부분은 StickyTaskAssignor를 이용해서, 최대한 방지해준다.
Eager Protocol 대신 Cooperative Protocol을 이용해서 리밸런싱을 진행한다면, Stop The world에 의한 가용성 이슈는 최소화된다.
리밸런싱 영향 줄이기 : Incremental Cooperative Rebalancing
Cooperative Rebalancing은 다음 기능을 제공해준다.
- 전역적인 리밸런싱을 여러 개의 작은(점진적) 리밸런싱으로 교체한다.
- 클라이언트는 소유자 변경이 필요 없는 자원(Task)를 유지하고, 이관이 필요한 Task들만 처리를 중단한다. (cooperative)
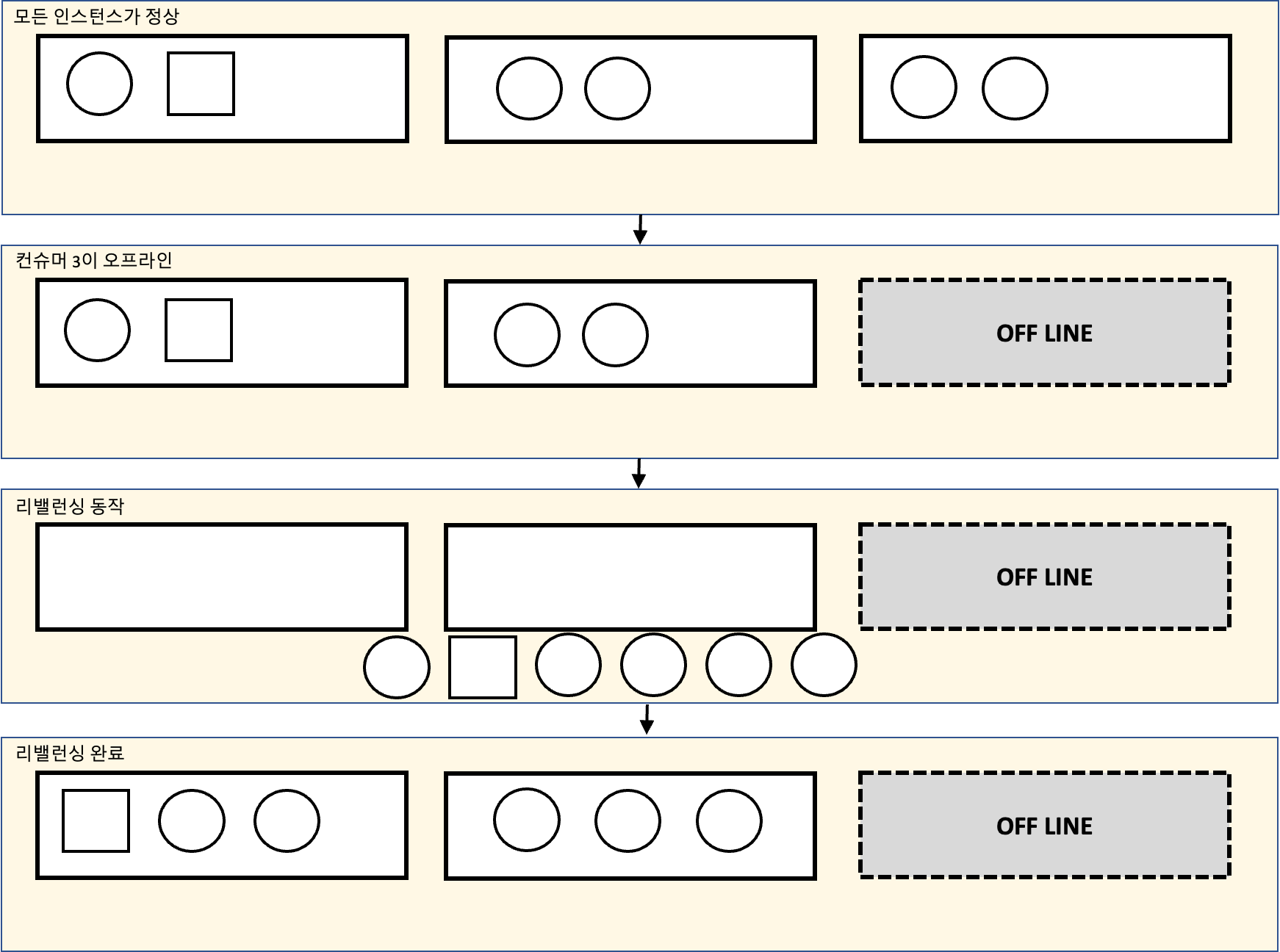
아래 그림을 살펴보면 내용이 좀 더 명확히 이해가 될 것이다. 리밸런싱 동작을 할 때, 카프카 스트림즈 인스턴스는 소유자 변경이 필요 없는 Task는 유지하며 처리를 계속 진행한다. 그리고 리밸런싱 과정에서는 OFF LINE으로 발생한 Task만 다시 재할당하고, 리밸런싱을 마무리한다. 즉, Stop The World 영향이 최소화 된다는 것을 의미한다.

리밸런싱 영향 줄이기 : 상태 크기 제어
리밸런싱이 발생할 때 주요한 성능 이슈가 되는 것은 State의 Restore다. State Restore 성능 이슈를 개선하기 위해서는 State의 크기를 제어하는 것도 한 가지 방법이 될 수 있다. 불필요한 State는 삭제하고 필요한 State만 가지고 있으면 State의 크기를 최적화 할 수 있다. State가 최적화 되면 State의 크기는 최적화 되고, State Restore에 필요한 시간이 줄어드는 것을 의미한다. 아래에서는 State의 크기를 제어하는 방법을 작성했다.
리밸런싱 영향 줄이기 : 상태 크기 제어 - Tombstone / 어플리케이션 레벨
tombstone은 Key 값은 존재하지만, value 값은 null인 메세지를 의미한다. tombstone 메세지는 StateStore와 ChangeLog 토픽 모두에서 불필요한 메세지를 삭제하는 역할을 한다. Use Case는 다음과 같다.
환자가 퇴원했다는 이벤트가 발생하면 이 환자에 대한 추가 이벤트가 발생하지 않을 것으로 기대한다. 따라서 상태 저장소에서 환자의 기록을 삭제한다.
stream
.groupByKey().
.reduce(
(value1, value2) -> {
if (value2.equals(PATIENT_CHECKED_OUT){
// Tombstone 생성
return null
}
return doSomething(value1, value2);
});
리밸런싱 영향 줄이기 : 상태 크기 제어 - 보관기간 / 어플리케이션 레벨
StateStore는 상태 저장소를 작게 유지할 수 있는 보관 기간 설정을 가지고 있다. Materialized 클래스는 withRetention() 메서드를 가지고 있고, 이 메서드를 이용해서 StateStore의 State 보관 기간을 설정할 수 있다. WindowStateStore에 retention을 설정할 때는 더 고려할 부분이 있다. Retention time은 Window size + grace Period보다 항상 커야한다는 점이다.
TimeWindows timeWindows = TimeWindows.ofSizeAndGrace(Duration.ofSeconds(60), Duration.ofSeconds(5));
hello
.groupByKey()
.windowedBy(timeWindows)
.count(
Materialized.<String, Long, WindowStore<Bytes, byte[]>>
as("pulse-counts").
withRetention(Duration.ofHours(6)));보관 기간을 줄이게 되면 StateStore에 저장된 Key - Value Fair는 더 줄어들 것이고, 변경 로그 토픽도 줄일 수 있다. 따라서 State의 크기가 작아지기 때문에 복구 속도를 향상시킬 수 있다.
리밸런싱 영향 줄이기 : 상태 크기 제어 - 공격적 토픽 압축 / 설정 값 수정
ChangeLog 토픽은 Compact Policy를 사용하기 때문에 각 Key에 대해서 최신 Value만 남아있다. 그렇지만 몇 가지 맹점이 있다. 먼저 풀어서 설명하면 StateStore는 삭제 / 압축을 바로 반영하지만 ChangeLog는 오랜 시간동안 압축되지 않거나, 값을 삭제하지 않아 필요 이상으로 큰 상태로 남아있다. 이것은 아래 내용에서 기인한다.
- Log Compaction의 대상은 In-active Segment다.
- In-acitve Segment의 생성 주기는 Segment의 크기에 의존한다.
- Log Compaction 주기는 dirty-ratio 비율에 의해서 결정된다.
Segment는 In-acitve Segment와 active Segment가 있다. 이 중에 Log Compaction의 대상이 되는 것은 In-active Segment다. In-acitve Segment는 Active Segment가 최대 Segment 크기가 되었을 때, 새로 생성된다. 그리고 실제로 Log Compaction이 진행되는 시점은 dirty-ratio 비율을 초과했을 때다. dirty-ratio 비율은 파티션 내의 dirty segment / total segment의 비율이다.
예를 들어서 dirty-ratio 비율을 굉장히 높게 설정하고, active-segment의 크기를 크게 해서 생성 시점을 늦추는 경우 ChangeLog의 Log Compaction이 극단적으로 느리게 일어날 수 있다. 반대로 설정한다면 ChangeLog의 Log Compaction을 활성화 할 수 있다. 이 부분을 각 StateStore에 설정해주게 되면서 좀 더 공격적으로 토픽을 압축해보는 것이다. 이것과 관련된 파라메터는 다음과 같다.
| 설정 | 기본값 | 설명 |
| segment.bytes | 1GB | 세그먼트 파일의 최대크기. |
| segment.ms | 7일 | 세그먼트 파일이 꽉 차지 않아도 delete policy의 대상이 되는 기간. 이 기간이 지나면 delete policy의 적용을 받는다. |
| min.cleanable.dirty.ratio | 0.5 | log compaction이 트리거 되는 값. |
| max.compaction.lag.ms | Long_Max_VALUE - 1 | 메시지가 압축 대상이 아닌 상태로 로그에 남아 있을 수 있는 최대 시간. 압축이 진행 중인 로그에만 적용 가능하다. |
| min.compaction.lag.ms | 0 | 메시지가 압축되지 않은 상태로 로그에 남아 있을 수 있는 최소 시간. 압축이 진행 중인 로그에만 적용 가능하다. |
사용은 아래와 같이 할 수 있다.
HashMap<String, String> topicConfigs = new HashMap<>();
topicConfigs.put("segment.bytes", "5368709212");
topicConfigs.put("min.cleanable.dirty.ratio", "0.3");
Materialized.as("hello")
.withLoggingEnabled(topicConfigs);
리밸런싱 영향 줄이기 : 상태 크기 제어 - 고정 길이 LRU 캐시 사용
In-Memory LRU 캐시를 이용해서 상태 저장소가 무한으로 커지는 것을 방지할 수 있다. In-memory LRU 캐시는 크기 설정이 가능하고, In-Memory LRU 캐시가 설정 크기를 초과하게 되면, 최근에 사용이 가장 적은 엔트리를 자동 삭제한다. In-Memory LRU 캐시에서 삭제되면 ChangeLog에는 Tomstone 레코드가 발송된다. 사용은 다음과 같이 할 수 있다.
int MAX_CACHE_SIZE = 10;
KeyValueBytesStoreSupplier lruStore = Stores.lruMap("hello", MAX_CACHE_SIZE);
Materialized.as(lruStore)
.withKeySerde(Serdes.String())
.withValueSerde(Serdes.String());한 가지 주의해야할 점은 공격적 토픽 압축에서 언급한 것처럼 LRU 캐시에서 삭제된 내용(StateStore)이 ChangeLog에 바로 반영되지 않는다는 점이다. 그리고 이 녀석은 In-memory 저장소이기 때문에 실패 시, StateStore를 복구하기 위해 ChangeLog의 모든 Log를 replay 해야하기 때문에 복구에 오랜 시간이 걸릴 수 있다.
리밸런싱 영향 줄이기 : 레코드 캐시로 쓰기 중복 제거
카프카 스트림즈는 StateStore의 업데이트와 StateStore를 DownStream으로 보내주는 운영 파라메터를 가지고 주기적으로 동작하고 있다. 이 운영 파라메터를 잘 이용하면 중복된 Key를 가진 메세지의 업데이트를 조금 줄일 수 있다. 예를 들어 StateStore에 A : 10 -> B : 20 -> A : 100이라는 메세지가 차례대로 들어왔다고 가정해보자. 이 때, StateStore의 간격이 충분히 크고 사이즈가 충분히 크다면 실제 DownStream에 전달되는 메세지를 3개에서 2개로 줄일 수 있다. 제공되는 파라메터는 다음과 같다.
| 원래 설정 | 기본값 | 설명 |
| cache.max.bytes.buffering | 10MB | 바이트 단위의 최대 메모리 양. 모든 스레드들이 버퍼링할 때 사용함. |
| commit.interval.ms | 30초 | 프로세서의 위치를 저장하는 주기 |
장/단점은 다음과 같다.
- 장점
- 읽기 지연 감소
- 쓰기 용량 감소
- StateStore, ChangeLog, 하위 Stream Processor
- 단점
- 더 많은 메모리 사용
- 더 긴 지연 시간(레코드를 덜 자주 내보낸다)
- StateStore를 복구해야 할 시간이 더 클 수 있음. ChangeLog로 나가는게 늦기 때문임.
cache.max.bytes.buffering으로 설정된 최대 메모리 양은 카프카 스트림즈 인스턴스의 StreamThread가 공평하게 나눠가져간다. 그런데 여기서 핫파티션(다른 파티션에 비해 상대적으로 데이터 용량이 큰 파티션)을 처리하는 StreamThread는 좀 더 빈번하게 Cache를 flush 할 것이다.
commit.interval.ms가 길 경우에는 장애 발생 후 재생에 필요한 작업량은 이 설정값을 증가시킬수록 증가할 것이다.
상태 저장소 모니터링
상용 환경에 어플리케이션을 배포하기 전에 어플리케이션 모니터링을 원활히 할 수 있도록 어플리케이션에 대한 충분히 가시성을 확보하는 것이 중요하다. State를 리스닝 할 수 있는 방법들이 두 가지 제공된다.
상태 저장소 모니터링 - StateListener
StateListener는 카프카 스트림즈가 제공하는 인터페이스다. 이 인터페이스는 onChange() 메서드를 제공해주는데, 이 메서드를 구현한 StateListener를 카프카 스트림즈에 추가해두면 카프카 스트림즈의 State가 변할 때 마다 알려준다. 이 때 이야기 하는 State는 StateStore의 State가 아닌 정말 카프카 스트림즈의 상태가 어떤지를 알려주는 녀석이다.
이 녀석을 이용해서 카프카 스트림즈의 리밸런싱이 일어나고 있는지 아닌지를 확인하는 동작을 추가할 수 있다. 예를 들면 다음과 같은 구성으로 해볼 수 있다.
new KafkaStreams.StateListener() {
@Override
public void onChange(KafkaStreams.State newState, KafkaStreams.State oldState) {
if ((newState == KafkaStreams.State.REBALANCING) && (KafkaStreams.State.RUNNING == oldState)) {
System.out.println("change staage");
}
}
};
상태 저장소 모니터링 - StateRestoreListener
StateListener는 리밸런싱 상태로 변경되거나 완료되는 시점을 살펴보는 녀석이다. 그런데 정작 리밸런싱이 어느 정도 단계로 진행되고 있는지는 알려주지 않는다. 이것은 StateRestoreListener를 이용해서 할 수 있다. 카프카 스트림즈는 StateRestoreListener 인터페이스를 제공해주고, 사용자는 이 인터페이스를 구현해서 카프카 스트림즈에 추가해주기만 하면 된다.
public interface StateRestoreListener {
void onRestoreStart(final TopicPartition topicPartition,
final String storeName,
final long startingOffset,
final long endingOffset);
void onBatchRestored(final TopicPartition topicPartition,
final String storeName,
final long batchEndOffset,
final long numRestored);
void onRestoreEnd(final TopicPartition topicPartition,
final String storeName,
final long totalRestored);
}이 인터페이스는 세 가지 메서드를 가진다.
- onRestoreStart
- onBatchRestored
- onRestoreEnd
onRestoreStart는 StateStore의 Restart가 시작 되는 시점에 한번 호출된다. 따라서 호출횟수는 많지 않다. 이 때, startingOffset이라는 것이 보이는데 상태를 완전히 잃어버렸을 경우에는 startingOffset은 0부터 시작한다. 즉, 전체 로그를 replay한다. 반면 startingOffset이 0보다 큰 경우에는 상태를 가지고 있기 때문에 StateStore 복구 시간이 다소 줄어들 수 있다.
onRestoreEnd는 StateStore의 복구가 완료될 때마다 호출된다.
OnBatchRestored 메소드는 단일 레코드 배치가 복구될 때 마다 호출된다. ChangeLog에서 메세지를 Batch 단위로 읽어와서 복구하기 시작하는데, 배치의 최대 크기는 MAX_POLL_RECORDS 설정과 동일하다. 이 레코드는 많이 호출될 가능성이 높기 때문에 이 메서드 안에서 동기 처리를 수행하는 경우에는 매우 조심해야한다. 대부분 이 메서드 안에서는 아무 작업도 하지 않도록 한다.
참고 : https://www.confluent.io/blog/watermarks-tables-event-time-dataflow-model/
리밸런싱 영향 줄이기 : Incremental Cooperative Rebalancing
궁금한 것
1. StickTaskAssignor와 Partitioner는 어떻게 상호작용 하는가?
2. Cooperative Rebalncing 했을 때, 자신이 가지고 있는 State를 포기해야하는 경우는?
3. 윈도우 보관기간이 지나면, ChangeLog에 삭제는 어떻게 들어가는가? 알아서 툼스톤을 생성할까?
4. Cache Flush, Commit 차이는?
'Kafka eco-system > KafkaStreams' 카테고리의 다른 글
| Kafka Streams와 ksqlDB 정복 : Processor API (7장) (0) | 2022.12.20 |
|---|---|
| Kafka Streams와 ksqlDB 정복 : 윈도우와 시간(5장) (0) | 2022.12.20 |
| Kafka Streams와 ksqlDB 정복 : 상태가 있는 처리 (4장) (1) | 2022.12.20 |
| Kafka Streams와 ksqlDb 정복 : 상태가 없는 처리 (3장) (0) | 2022.12.20 |
| Kafka Streams와 ksqlDB 정복 : 카프카 스트림즈 시작하기 (2장) (0) | 2022.12.20 |