OneToMany에서 CascadeType.ALL의 N+1 문제 야기
- Spring/JPA
- 2023. 11. 18.
들어가기 전
CascadeType.ALL은 생애주기를 함께 하는 엔티티를 다루는데 있어서는 좋은 도구가 될 수 있다. 그렇지만 CascadeType.ALL을 사용할 때 발생할 수 있는 문제점은 잘 파악해야 필요한 위치에 사용할 수 있게 될 것 같다.
Cascade.ALL 동작 방식
CascadeType.ALL은 부모 엔티티의 영속화 상태가 변할 때, 그 변화가 자식 엔티티에도 고스란히 전파되는 것을 의미한다. 예를 들어 아래 코드에서는 다음과 같이 동작하는 것을 상상해 볼 수 있다.
- Team을 영속성 컨텍스트에 영속화 한다 → Team과 연관된 Member들도 모두 영속화 된다.
- Team이 영속성 컨텍스트에서 삭제된다 → Team과 연관된 Member들도 영속성 컨텍스트에서 삭제된다.
@Entity
@Getter
@Setter
public class Team {
@Id
@GeneratedValue
private Long id;
@OneToMany(mappedBy = "team", fetch = FetchType.LAZY, cascade = CascadeType.ALL)
private List<Member> memberList = new ArrayList<>();
...
}
@Entity
@Getter
@Setter
public class Member {
@Id
@GeneratedValue
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team")
private Team team;
...
}CascadeType.ALL의 문제가 발생하는 상황
CascadeType.ALL은 완벽히 생명주기를 하는 엔티티를 관리할 때는 좋은 도구가 될 수 있다. 그렇지만 특정 상황에서는 의도치 않은 동작이 발생하면서 문제를 만들 수도 있다. 내가 겪은 상황은 부모 엔티티를 삭제할 때 발생한다. 다음 테스트 코드를 실행하고, 매 단계마다 실행되는 쿼리를 살펴보자. 대략적인 상황은 다음과 같다
- Team을 1개 생성한다. Team에 속한 Member를 5개 생성한다. 모두 영속화한다.
- Team을 DB에서 삭제한다. Member도 CascadeType.ALL에 의해서 자동으로 삭제되기를 기대한다.
@Test
void test3() {
Team team = new Team();
em.persist(team);
for (int i = 0; i < 5; i++) {
createNewMember(team);
}
em.flush();
em.clear();
System.out.println("INIT VALUE AND FLUSH COMPLETED");
System.out.println("BEFORE EM.FIND");
Team findTeam = em.find(Team.class, team.getId());
System.out.println("AFTER EM.FIND");
em.remove(findTeam);
System.out.println("AFTER EM.REMOVE");
em.flush();
em.clear();
}
// 헬퍼 메서드
void createNewMember(Team team) {
Member member = new Member();
member.setTeam(team);
em.persist(member);
}위의 테스트 코드를 실행하면 어떤 쿼리가 발생할까? 아래는 발생한 쿼리 내용이다. 주의해서 봐야 할 부분은 두 가지다.
- em.remove()를 하기 직전에 Team에 속한 Member들에 대한 Select 쿼리가 자동적으로 나간다. (memberList)
- em.remove()를 한 후에 각 멤버들에 대한 Delete 쿼리가 5번 나간다.
: insert into team (id) values (?)
: insert into member (team, id) values (?, ?)
: insert into member (team, id) values (?, ?)
: insert into member (team, id) values (?, ?)
: insert into member (team, id) values (?, ?)
: insert into member (team, id) values (?, ?)
INIT VALUE AND FLUSH COMPLETED
BEFORE EM.FIND
: select team0_.id as id1_1_0_ from team team0_ where team0_.id=?
AFTER EM.FIND
: select memberlist0_.team as team2_0_1_, memberlist0_.id as id1_0_1_, memberlist0_.id as id1_0_0_, memberlist0_.team as team2_0_0_ from member memberlist0_ where memberlist0_.team=?
AFTER EM.REMOVE
: delete from member where id=?
: delete from member where id=?
: delete from member where id=?
: delete from member where id=?
: delete from member where id=?
: delete from team where id=?위의 상태를 정리하면 다음과 같다
- CascadeType.ALL은 부모 엔티티가 삭제되었을 때, 자식 엔티티가 삭제되어야 한다는 동작은 만족한다.
- CasCadeType.ALL은 em.remove()를 할 때, 삭제할 자식들을 찾아오기 위해서 SELECT 쿼리를 한번 보낸다.
- CasCadeType.ALL에 의해서 자식 엔티티가 삭제될 때는 쿼리가 N+1만큼 나가게 된다.
기능은 만족하지만 쓸 데 없는 쿼리가 발생한다는 것이다. N+1이 가장 dominant한 문제고, 의미없는 SELECT 쿼리도 문제다.
의미없는 SELECT 쿼리는 memberList가 이미 PersistenBag 구조에 필요한 Member 정보 (PK) 값이 다 있음에도 불구하고 나가기 때문이다. 자동으로 DELETE 쿼리가 나갈 때도 member의 PK값이 Where 절에 포함되어 나가기 때문에 의미가 없는 쿼리가 맞다. 그럼에도 불구하고 CascadeType.ALL의 동작을 수행하기 위해서 JPA는 SELECT 쿼리를 보낸다. 하나의 엔티티 내부에 OneToMany 필드가 100개가 있으면, 100개의 SELECT 쿼리가 나가는 상황도 발생할 수 있겠다. 따라서 이 부분의 해결이 필요하다.
OneToMany에서 Cascade를 하면 왜 연관관계를 반드시 조회할까?
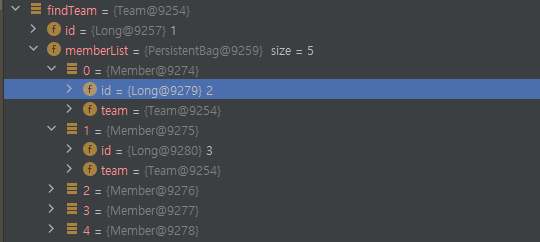
위의 코드 동작은 다음 부분에서 볼 수 있다. (https://github.com/hibernate/hibernate-orm/blob/943c2210dde2bf5d120721fa9e5944036d031a19/hibernate-core/src/main/java/org/hibernate/engine/internal/Cascade.java#L84-L151)
public static void cascade(
final CascadingAction action,
final CascadePoint cascadePoint,
final EventSource eventSource,
final EntityPersister persister,
final Object parent,
final Object anything) throws HibernateException {
if ( persister.hasCascades() || action.requiresNoCascadeChecking() ) { // performance opt
final boolean traceEnabled = LOG.isTraceEnabled();
if ( traceEnabled ) {
LOG.tracev( "Processing cascade {0} for: {1}", action, persister.getEntityName() );
}
final PersistenceContext persistenceContext = eventSource.getPersistenceContextInternal();
final Type[] types = persister.getPropertyTypes();
final String[] propertyNames = persister.getPropertyNames();
final CascadeStyle[] cascadeStyles = persister.getPropertyCascadeStyles();
final boolean hasUninitializedLazyProperties = persister.hasUninitializedLazyProperties( parent );
for ( int i = 0; i < types.length; i++) {
final CascadeStyle style = cascadeStyles[ i ];
final String propertyName = propertyNames[ i ];
final boolean isUninitializedProperty =
hasUninitializedLazyProperties &&
!persister.getBytecodeEnhancementMetadata().isAttributeLoaded( parent, propertyName );
if ( style.doCascade( action ) ) {
final Object child;
if ( isUninitializedProperty ) {
// parent is a bytecode enhanced entity.
// Cascade to an uninitialized, lazy value only if
// parent is managed in the PersistenceContext.
// If parent is a detached entity being merged,
// then parent will not be in the PersistencContext
// (so lazy attributes must not be initialized).
...
}
else {
// 이 부분에서 SELECT 쿼리 나감.
child = persister.getPropertyValue( parent, i );
}위 코드를 필요한 부분만 간략히 이해해보면 다음과 같다.
- 부모 엔티티에 지연로딩 되지 않은 녀석이 있으면, isUninitializedProperty가 항상 False가 되어서 persiste.getPropertyValue()가 호출된다.
- 지연로딩이 되었는지 아닌지를 확인하는 것은 properties의 이름으로 판단한다. 이 때, 'memberList'라는 String을 넘기는데 memberList는 PersistentBag 객체다. PersistenBag는 내부적으로 Member 객체를 가지고 있다.
- PersistentBag 관점에서 봤을 때는 이미 초기화 되어 필요한 Member를 가지고 있다. 즉, 초기화 되었기 때문에 persister.getPropertyValue()가 호출된다.
- persister.getPropertyValue()를 호출하면 parent의 필드에 접근하기 때문에 초기화 되지 않은 Member 들이 지연로딩 되면서 SELECT 쿼리가 나가게 된다.
- 위의 코드에 적용하면 다음과 같다.
- Team은 내부적으로 Member를 MemberList로 가진다.
- Team이 가지는 Properties는 Member가 아니라 MemberList다.
- Team이 em.find()로 조회되었을 때, MemberList는 PersistentBag 객체가 배정되어있다. 즉, MemberList는 초기화되어있다.
- 따라서 isUnintializedProperty는 False가 되고, 바로 getPropertyValue()를 한다.
- getPropertyValue()에서는 memberList에 있는 Member를 가져오는 동작을 한다. 이 때 Member는 프록시 객체였는데, 조회가 발생하자마자 DB에서 실제 값을 가져와서 초기화한다. (SELECT 쿼리 발생함)
즉, remove()에 대해서 cascade 동작이 발현되게 된다면 반드시 SELECT 쿼리가 나갈 수 밖에 없게 되어 있는 구조다. 그리고 불러온 녀석들은 PersistentContext(영속성 컨텍스트)에 각각 영속화 되는데, 이 녀석들에게 DELETE 쿼리가 각각 나가게 되는 불상사가 만들어진다.
왜 이렇게 동작해야만 하는 걸까?
이미 연관관계 Entity의 PK 값을 다 알고 있기 때문에 SELECT 쿼리 없이 PK 값으로 지우면 되지 않을까? 라고 생각할 수 있다. 그렇지만 이 부분은 일반적인 경우에는 잘못된 이야기다.
public class B {
@Id
@GeneratedValue
private Long id;
private C;
}위 경우를 고려해보자.
- A는 List<B>를 가진다. A가 불러와지면 B는 Lazy Loading이므로 PK 값만 채워진 프록시 객체가 들어가있다.
- 그런데 B는 엔티티 C를 가지는데, 어떤 엔티티가 B에 속하는지 알 수 없다.
따라서 B가 삭제되면 C 역시 삭제 되어야 하는데, B가 어떤 C를 가진지 모르기 때문에 Lazy Loading된 B를 로딩해서 C의 정보를 가져와야만 하는 것이다. 그래서 Cascade Type이 ALL이고 DELETE를 했을 때, N+1 SELECT 쿼리가 발생하게 된다.
N+1 쿼리 및 SELECT 쿼리 문제 해결
방법은 em.remove()가 Cascade를 유발하지 않도록 하는 것이다. 그렇게 하면 N+1, SELECT 쿼리 문제가 모두 해결된다. 그렇다면 이런 결론에 도달한다.
- CascadeType은 PERSIST를 사용한다. 이 동작은 remove()에 의해서 영속성 전이가 일어나지 않도록 한다. 따라서 SELECT 쿼리 및 N+1 삭제 쿼리가 나가지 않는다.
- 자식 Entity는 WHERE 문을 이용해서 직접 삭제한다.
다음과 같이 작성해 볼 수 있다.
// PERSIST로 수정
@OneToMany(mappedBy = "team", fetch = FetchType.LAZY, cascade = CascadeType.PERSIST)
private List<Member> memberList = new ArrayList<>();그리고 삭제 쿼리를 다음과 같이 직접 작성한다.
@Test
void test4() {
Team team = new Team();
em.persist(team);
for (int i = 0; i < 5; i++) {
createNewMember(team);
}
em.flush();
em.clear();
Team findTeam = em.createQuery("SELECT t from Team t where t.id =: id", Team.class)
.setParameter("id", team.getId())
.getSingleResult();
// 삭제 쿼리 직접 작성
em.createQuery("DELETE Member m where m.team.id =: id")
.setParameter("id", team.getId())
.executeUpdate();
em.remove(findTeam);
em.flush();
em.clear();
}이렇게 작성했을 때, 실행 쿼리를 살펴보면 다음과 같다. 이전 결과와 살펴보면 다음과 같다. 다음과 같이 Query 최적화를 할 수 있게 된다.
- Delete 쿼리 총 6회 발생(Team 1회, Member 5회) → Delete 쿼리 총 2회 발생(Team 1회, Member 1회)
- MemberList에 대한 SELECT 쿼리 1회 → MemberList에 대한 SELECT 쿼리 0회
: insert into team (id) values (?)
: insert into member (name, team, id) values (?, ?, ?)
: insert into member (name, team, id) values (?, ?, ?)
: insert into member (name, team, id) values (?, ?, ?)
: insert into member (name, team, id) values (?, ?, ?)
: insert into member (name, team, id) values (?, ?, ?)
: select team0_.id as id1_1_ from team team0_ where team0_.id=?
: delete from member where team=?
: delete from team where id=?
orphanRemoval=True라면?
orphanRemoval = True를 하고, Cascade를 모두 꺼두었을 때는 어떨까? 코드는 아래를 참고하면 된다. 결론은 N+1 쿼리도 그대로 있고, 불필요한 SELECT 쿼리도 나간다.
// Team.java
@OneToMany(mappedBy = "team", fetch = FetchType.LAZY, orphanRemoval = true)
private List<Member> memberList = new ArrayList<>();
// TestCode
@Test
void test4() {
Team team = new Team();
em.persist(team);
for (int i = 0; i < 5; i++) {
createNewMember(team);
}
em.flush();
em.clear();
Team findTeam = em.createQuery("SELECT t from Team t where t.id =: id", Team.class)
.setParameter("id", team.getId())
.getSingleResult();
em.remove(findTeam);
em.flush();
em.clear();
}쿼리를 살펴보면 다음과 같다.
: insert into team (id) values (?)
: insert into member (name, team, id) values (?, ?, ?)
: insert into member (name, team, id) values (?, ?, ?)
: insert into member (name, team, id) values (?, ?, ?)
: insert into member (name, team, id) values (?, ?, ?)
: insert into member (name, team, id) values (?, ?, ?)
: select team0_.id as id1_1_ from team team0_ where team0_.id=?
// 불필요 SELECT 쿼리 1회
: select memberlist0_.team as team3_0_1_, memberlist0_.id as id1_0_1_, memberlist0_.id as id1_0_0_, memberlist0_.name as name2_0_0_, memberlist0_.team as team3_0_0_ from member memberlist0_ where memberlist0_.team=?
// DELETE N+1
: delete from member where id=?
: delete from member where id=?
: delete from member where id=?
: delete from member where id=?
: delete from member where id=?
: delete from team where id=?
CascadeType.ALL, orphanRemoval = True를 안 쓴다면?
이 녀석들의 장점은 부모 엔티티와 자식 엔티티의 생명 주기를 동일하게 가져가준다. 어떤 의미로 보면 '삭제'에 대한 캡슐화가 되어있는 셈이다. CascadeType.ALL, orphanRemoval = True를 사용하지 않는다면 상대적으로 캡슐화가 되지 않은 상태로 전이된다는 것을 의미한다.
개발하고 있는 어플리케이션의 데이터베이스 각 테이블에 능통한 사람이라면 엔티티를 삭제할 때 연관관계의 엔티티를 모두 삭제해 줄 것이다. 그렇지만 누군가와 협업하거나, 간만에 개발을 한다면 이 엔티티를 삭제했을 때 어떤 엔티티까지 삭제해야하는지 파악하는데 꽤 오래 걸릴 것이다. 따라서 초기 단계부터 연관관계 엔티티의 삭제를 캡슐화 하는 것이 좋을 것 같다.
캡슐화 하는 방법은 추천받은 방법과 생각해 본 방법을 정리하면 현재는 두 가지가 존재하는 것 같다.
- Repository Layer에서의 캡슐화
- Aggregator를 이용한 Event 구조
Aggregator는 살펴보니 사용하기 위해서는 또 많은 부분을 공부해야하는 것 같다. 이후에 공부를 한 후에 적용할만한 기술적 부채로 남겨두면 좋을 것 같다. 남은 방법은 Repository Layer에서 캡슐화 하는 방법이다. 내가 생각하는 Repository Layer에서 캡슐화 하는 것의 당위성은 다음과 같다.
- Repository Layer는 DB와의 통신 역할을 하지만, Entity Mapping의 역할도 한다. 즉, DB 통신 외에 다른 역할을 하는 것도 가능하다.
- Repository끼리 서로 의존해서 필요한 엔티티를 한꺼번에 삭제하는 캡슐화는 단방향 의존도 지켜지기 때문에 순환 참조의 문제도 존재하지 않는다. 또한, Layer도 침범하지 않는다.
위와 같은 것들을 고려한다면, 다음과 Service / Repository Layer를 작성하는 것도 하나의 좋은 방법이 될 수 있을 것이라 판단한다.
@Service
@Transactional
@RequiredArgsConstructor
public class TeamService {
private final EntityManager em;
private final TeamRepository teamRepository;
public void removeTeam(Long teamId) {
teamRepository.removeTeam(teamId);
}
}TeamService는 TeamRepository를 통해서 Team을 삭제하는 명령어를 호출한다.
@Repository
@RequiredArgsConstructor
public class TeamRepository {
private final JPAQueryFactory queryFactory;
private final MemberRepository memberRepository;
public void removeTeam(Long teamId) {
memberRepository.removeMemberByTeamIdQuery(teamId);
removeTeamByTeamIdQuery(teamId);
}
public void removeTeamByTeamIdQuery(Long teamId) {
queryFactory
.delete(member)
.where(member.team.id.eq(teamId))
.execute();
}
}TeamRepository에는 Query Suffix를 가지는 메서드가 있고, 실제로 execute를 하는 메서드가 존재한다. Service 계층은 execute하는 메서드만 호출하고, Query Suffix 메서드는 Repository 내부에서만 호출하도록 한다. 이를 통해서 연관관계 엔티티 삭제의 캡슐화를 도모한다.
참고
'Spring > JPA' 카테고리의 다른 글
| JPA : PK 생성 전략 (0) | 2022.05.23 |
|---|---|
| JPA : JPQL과 영속성 컨텍스트 (0) | 2022.02.23 |
| JPA : Bulk 연산의 주의할 점 (0) | 2022.02.23 |
| JPA : Collection과 JPA 동작 방식 (1) | 2022.02.23 |
| JPA : 2차 캐시 (0) | 2022.02.23 |