
JPA : Collection과 JPA 동작 방식
- Spring / JPA
- 2022. 2. 23.
- 컬렉션
- JPA와 Collection
- 하이버네이트 내장 컬렉션과 특징
- 자바 Interface : Collection, List
- 자바 Interface : Set
- 자바 Interface : List + @OrderColumn
- 자바 Interface : List + @OrderBy
이 게시글은 자바 표준 ORM JPA 프로그래밍을 공부하고 정리한 글입니다.
컬렉션
자바는 Collection이라는 자료구조를 제공한다. JPA는 이 중 Collection, List, Set, Map 컬렉션을 지원한다. JPA는 자바 Collection Type을 영속화 할 때 특별한 기능을 해준다. 그 내용은 아래에서 자세히 살펴보도록 한다. 먼저 자바의 자료구조에 대해 간단히 이해하자.
| 자료 구조 | 중복 허용 | 순서 보장 |
| Collection | O | X(하이버네이트 가정) |
| Set | X | X |
| List | O | O |
| Map | X | X |
JPA와 Collection
JPA의 구현체인 하이버네이트는 엔티티를 영속 상태로 만들 때, 컬렉션 필드를 하이버네이트에서 준비한 Collection으로 한번 감싼 다음 영속화 시킨다. 즉, Collection이 영속화 되었을 때 하이버네이트 내장 Collection으로 감싸져야 JPA가 의도대로 동작한다는 것이다. 이런 이유 때문에 JPA의 Entity에서 Collection을 사용한다면, 아래처럼 즉시 초기화 해야한다.
@OneToMany
private List<Member> myList = new ArrayList<>();
@OneToMany
private Collection<Member> collection = new ArrayList<>();
@OneToMany
private Set<Member> mySet = new HashSet<>();
@OneToMany
@OrderColumn(name = "name")
private List<Member> orderColumnList = new ArrayList<>();즉시 초기화를 하지 않는 상황을 가정해보자. 먼저 엔티티를 생성하고 영속화를 한 다음에 Collection 필드가 생성된다고 해보자. 이럴 경우, Collection 필드는 하이버네이트가 제공하는 내부 Collection으로 감싸지는 것이 보장되지 않는다. 따라서 이상 동작을 할 가능성이 높다. 이런 이유로 Collection 필드는 반드시 위 방식으로 초기화 하는 것이 추천된다.
하이버네이트 내장 컬렉션과 특징
| 컬렉션 인터페이스 | 내장 컬렉션 | 중복 허용 | 순서 보관 |
| Collection, List | PersistenceBag | O | X |
| Set | PersistenceSet | X | X |
| List + @OrderColumn | PersistenceList | O | O |
자바의 어떤 Collection이 필드로 사용되느냐에 따라 JPA는 하이버네이트 내장 컬렉션으로 한번 자바 Collection을 감싼다. 하이버네이트 내장 Collection은 중복 허용, 순서 보관에 대한 허용값이 있다. 이 값은 중요하다. 왜냐하면 이 값의 설정에 따라 의도치 않은 지연로딩이 발생할 수 있기 때문이다.
자바 Interface : Collection, List
@OneToMany
private List<Member> myList = new ArrayList<>();
@OneToMany
private Collection<Member> collection = new ArrayList<>();Collection, List는 중복을 허용한다. 따라서 Colletion, List에 값을 추가할 때 중복된 값이 있는지 확인하지 않아도 된다. 단순 저장만 하면 되기 때문에 Collection / List에 값을 추가해도 지연 로딩된 컬렉션을 초기화하지 않는다.
영속화 전 / 후 패킹 클래스 확인

영속화 전은 자바의 Collection, ArrayList 자료구조를 가진다.

영속화 후에는 JPA가 제공하는 PersistenceBag 자료구조로 패킹된다.
테스트 코드 → Collection / List에 값을 추가
@Test
void test2() {
// given
Team team = new Team();
Member member = new Member();
member.addTeam(team);
em.persist(team);
em.flush();
em.clear();
// when
Team findTeam = em.find(Team.class, team.getId());
Member member1 = new Member();
// Collection에 값을 추가
member1.addTeam(findTeam);
em.persist(member1);
em.flush();
em.clear();
}- Team을 불러온다. 이 때 Team은 Member와 OneToMany 관계다(1팀에 여러 Member가 있는 구조)
- 이 때, Team은 Member를 Collection / List 형식으로 가진다.
- 따라서 JPA는 PersistenceBag로 패킹한다. Persistence Bag은 Collection에 엔티티가 추가되더라도 다시 초기화 되는 일은 발생하지 않는다.
실행 쿼리 확인
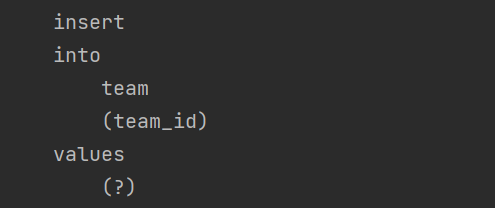
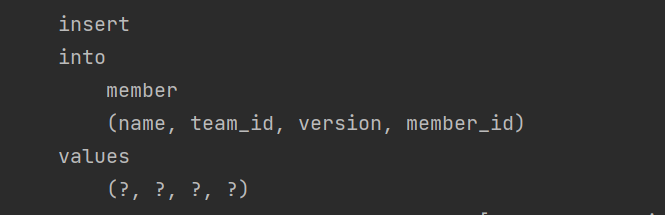


Team은 Member를 Collection / List로 가지고, JPA는 이 Collection을 Persistenc Bag로 패킹해준다. Persistence Bag은 중복을 허용하는 자료구조이기 때문에 내부적으로 중복이 있는지 체크하지 않아도 된다. 따라서 중복 체크에 필요한 지연로딩을 하지 않아도 된다. 그래서 총 4회의 쿼리만으로 Collection이 추가된다.
자바 Interface : Set
@OneToMany(mappedBy = "team", cascade = CascadeType.ALL)
private Set<Member> mySet = new HashSet<>();Set은 중복을 허용하지 않는다. 따라서 Set에 값을 추가할 경우, 같은 객체가 이미 존재하는지를 확인해야한다. 따라서 엔티티를 추가 할 때 마다 중복된 엔티티가 있는지를 비교해야한다. 이런 이유로 엔티티를 추가할 때마다 지연 로딩된 컬렉션을 다시 초기화해야한다.
좀 더 자세히 정리하면 이렇다. 중복을 비교하기 위해서는 Equals를 비교를 해야한다. 기본적으로 지연로딩 전략으로 불러와진 Set 객체는 모두 프록시다. 따라서 이 엔티티가 추가하고자 하는 엔티티와 동일한지 비교를 할 수 없다. 따라서 지연로딩을 실행해서 엔티티를 가져와서 서로 비교를 해야하는 것이다.
영속화 전/후 클래스 패킹 확인

영속화 전 Set는 자바의 HashSet 자료구조를 가진다.

영속화 후 Set는 JPA가 제공하는 PersistenceSet을 가진다.
테스트 코드 → Set에 값을 추가.
@Test
void test2() {
// given
Team team = new Team();
Member member = new Member();
member.addTeam(team);
em.persist(team);
em.flush();
em.clear();
// when
Team findTeam = em.find(Team.class, team.getId());
Member member1 = new Member();
// Set 값을 추가
member1.addTeam(findTeam);
em.persist(member1);
em.flush();
em.clear();
}- Team을 불러온다. 이 때 Team은 Member와 OneToMany 관계다(1팀에 여러 Member가 있는 구조)
- 이 때, Team은 Member를 Set 형식으로 가진다.
- 따라서 JPA는 PersistenceSet로 패킹한다. Persistence Set은 중복을 허용하지 않는다. 엔티티를 추가할 때, 중복 검사를 해야한다 → 추가 지연로딩이 발생한다.
실행 쿼리 확인

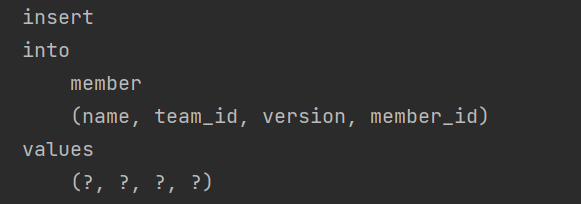

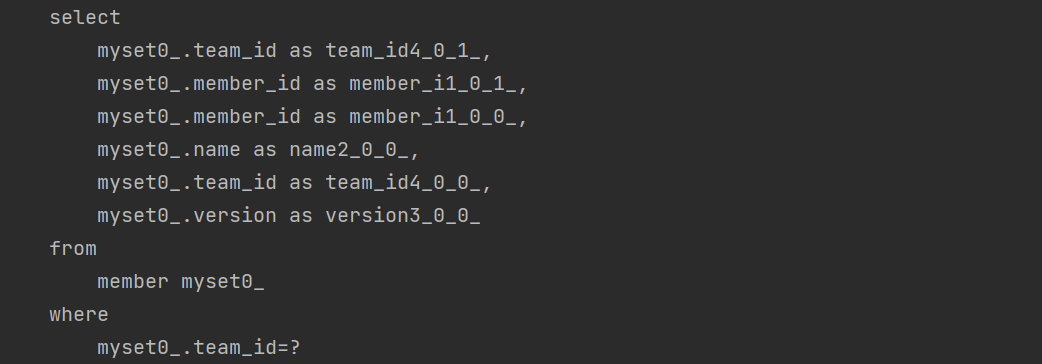

Team은 Member를 Set Collection으로 가진다. JPA는 이 Collection을 PersistenceSet으로 패킹한다. PersistenceSet은 중복을 허용하지 않는다. 따라서 엔티티가 추가될 경우, 중복 검사를 위해 지연 로딩이 발생한다. 따라서 mySet에 대한 Select 쿼리가 1회 더 나가게 된다.
자바 Interface : List + @OrderColumn
Collection에 @OrderColumn 어노테이션을 달아 DB에 순번 Column을 추가해서 관리할 수 있다. 이렇게 저장된 Collection은 JPA가 제공하는 PersistenceList로 패킹된다. 그렇지만 @OrderColumn은 실무에서 사용되지 않는다고 한다. 이런 저런 이유가 있지만 한 단어로 요약하면 시간복잡도가 너무 안 좋다는 것이다.
@OrderColumn의 단점
1. Team / Member 관계에서 Member의 Position(@OrderColumn)은 Team(연관관계 주인) 맵핑된다. 따라서 Member는 Insert 하는 시점에 Position의 값은 Member는 알 수 없다. 왜냐하면 Position은 Team.members의 위치값이기 때문이다. 결국 Team.member의 위치값을 Member의 Position에 업데이트 하기 위한 업데이트 쿼리가 한번 더 나가야 한다.
2. List를 변경하면 연관된 많은 위치의 값을 변경해야 한다. 예를 들어 1억개의 Row가 있다고 가정했을 때, 1번째 Position을 고치면 1억개의 Row를 모두 갱신해줘야한다. 어마어마한 리소스가 발생한다.
3. 중간에 Position 값이 없으면 조회한 List에는 null이 보관된다. 예를 들어 Member의 Position 2번을 DB에서 강제로 삭제하고 DB에 따로 업데이트를 해주지 않았다고 가정해보자. 그럼 DB에는[0,null,2,3]이 된다. 이 때, List를 조회하면 Team.members[1]에는 Null 값이 저장된다. 따라서 NullPointerException이 발생한다.
위와 같은 단점 때문에 @OrderColumn은 실무에서 사용되지 않는다고 한다.
자바 Interface : List + @OrderBy
기존 List에 @OrderBy 어노테이션을 달아준다. @OrderBy 어노테이션은 SQL 쿼리 시점에 자동으로 ORDER BY SQL이 나가게 된다.(Collection 객체에 대한 지연 로딩 시) 테스트 코드를 다음과 같이 작성해서 한번 확인해본다.
팀 도메인 코드
@Entity
@Getter
public class Team {
@Id
@GeneratedValue
@Column(name = "team_id")
private Long id;
@OneToMany(mappedBy = "team", cascade = CascadeType.ALL)
@OrderBy("name desc")
private List<Member> myList = new ArrayList<>();
}
테스트 코드
@Test
@DisplayName("@OrderByTest")
void test3() {
// given
Team team = new Team();
em.persist(team);
for (int i = 0; i < 100; i++) {
Member member = new Member();
member.setName(String.valueOf(i));
member.addTeam(team);
em.persist(member);
}
em.flush();
em.clear();
// when
Team findTeam = em.find(Team.class, team.getId());
findTeam.getMyList().forEach(member -> log.info("member Name = {}", member.getName()));
}- Member의 이름을 0 ~ 99까지 저장하고, Team에 이 Member를 모두 추가한다.
- Team을 불러와서, Team의 Members가 Member의 이름 내림차순으로 잘 정렬되었는지 확인한다.
테스트 결과 확인
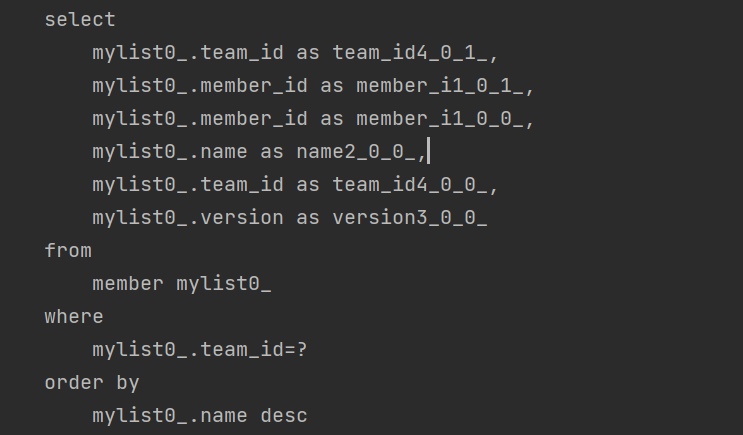
Member의 정보를 출력할 때, 지연로딩으로 myList에 저장된 Member를 모두 불러온다. 이 때, 가장 아래 쿼리를 보면 "order by myList name desc" 쿼리가 나간 것을 확인할 수 있다.
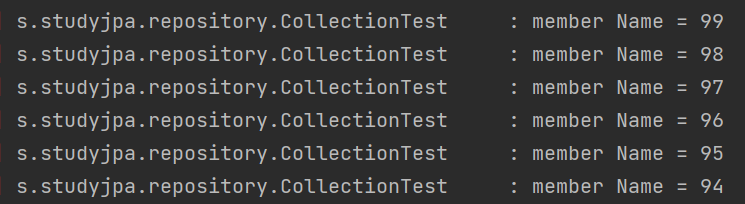
순서대로 출력 시, 다음과 같이 Member의 이름이 역순으로 잘 정렬되어 출력되는 것을 볼 수 있다. 약간 헷갈릴 수 있는 부분은 이거다. TEAM 엔티티 자체를 SELECT 할 때는 OrderBy가 들어가지 않는다. TEAM 엔티티를 불러와서 Member Collection이 필요한 경우 지연로딩을 하게 되는데, 이 때 Member Collection에 대한 Order By 쿼리가 나가게 된다.
'Spring > JPA' 카테고리의 다른 글
| JPA : JPQL과 영속성 컨텍스트 (0) | 2022.02.23 |
|---|---|
| JPA : Bulk 연산의 주의할 점 (0) | 2022.02.23 |
| JPA : 2차 캐시 (0) | 2022.02.23 |
| JPA : 트랜잭션 격리 수준과 JPA의 락 (0) | 2022.02.23 |
| JPA : Batch 처리하기 (0) | 2022.02.21 |



