Kafka Connect 개념
- Kafka eco-system/Kafka Connector
- 2023. 1. 15.
Kafka Connect란?
카프카는 단순한 메세지 큐 이상으로 하나의 DB의 형태로 자리 매김을 하고 있다. 특히 실시간 데이터 처리가 중요한 스트림 처리의 경우 카프카에서 데이터를 읽어와서 처리하는 형식이 많이 이루어지고 있다. 그런데 최근에 나온 녀석들은 카프카를 대상으로 데이터를 공급하고 읽어오는 형태를 지원한다. 그렇지만 전통적으로 사용하고 있던 RDBMS는 카프카와 연동되는 기능이 제공되고 있지는 않다.
카프카 커넥트는 카프카 메세지 시스템(Broker / Producer / Consumer)를 기반으로 다양한 데이터 소스 시스템에서 발생한 데이터를 타겟 시스템으로 전달하기 위해 만들어진 Component다. 주요한 특징 중 하나는 Kafka와 관련된 코딩 없이 설정만으로 데이터를 Source에서 불러와서 타겟으로 넣어준다는 점이다.
카프카와 관련된 코딩을 해서 데이터를 생성 및 읽어오는 것은 Kafka Consumer / Kafka Producer를 직접 코딩해서 데이터를 공급하고 읽어오는 작업을 하는 것을 의미한다. 그렇지만 카프카 커넥트를 이용하게 되면 이런 부분을 전혀 고려하지 않아도 된다.

위 그림은 카프카 커넥트를 손쉽게 설명해주는 직관적인 그림이다. 예를 들어 카프카 커넥트는 JDBC, MongoDB, MySQL의 Source로부터 데이터를 읽어와서 카프카에 저장해둔다. 카프카 커넥트는 카프카에 저장된 메세지를 읽어와서 Elastic Search, Cassandra, HDFS와 같은 Target(Sink)에 데이터를 저장해준다. 즉, 카프카 커넥트는 다음과 같은 형태로 데이터를 읽어와서 전달해준다.
Source System → Source Connector → Kafka → Sink Connector → Sink System
가장 큰 흐름은 위와 같은 형태가 된다.
카프카 커넥트의 주요 구성 요소
카프카 커넥트는 프레임워크의 범주로 이해할 수 있다. 카프카 커넥트라는 프레임 워크를 여러 가지의 구성 요소가 함께 구성하고 있고, 이 구성 요소를 자유롭게 설정 및 사용할 수 있다. 카프카 커넥트를 구성하는 주요 구성 요소는 다음과 같다.
- Connector
- Task
- Worker
- Dead Letter Que
- SMT (Single Message Transformation)
- Converter
- Config
여기서 항상 필요한 것은 Connector, Config, Converter이고 SMT의 경우 필요할 경우에 추가해서 사용하면 된다. 아래에서 각 구성 요소에 대해서 좀 더 살펴보고자 한다.
Connector
카프카 커넥터를 간단히 요약하면 다음과 같다.
- 커넥터는 Source System에서 메세지를 읽어와서 카프카로 넣거나, 카프카에서 읽어온 데이터를 Sink System에 넣어주는 역할을 한다.
- 커넥터는 Task를 관리하여 데이터 스트리밍을 조정하는 고수준 추상화 객체다.
우선 카프카 커넥터와 카프카 커넥트는 서로 다른 녀석인 것을 먼저 이야기 해야한다. 우리가 카프카 커넥트라는 프레임워크를 띄우면 카프카 커넥트에서 필요한 카프카 커넥터를 로딩해서 사용하는 형태다. 카프카 커넥터는 Source 시스템에서 메세지를 읽어오고, Target 시스템에 메세지를 넣어주는 역할을 한다.
바꿔 이야기하면 Source Connector는 Source System에서 카프카 메세지를 생성해서 카프카 메세지로 넣어주는 역할을 한다. Sink Connector는 Sink System에서 카프카 메세지를 읽어와서 Sink System에 적합한 형태로 넣어주는 역할을 한다.
커넥터는 데이터를 직접 읽어오거나 하는 역할을 하지는 않는다. 실제로 데이터를 읽어오는 역할은 커넥터 아래에 생성될 Task 쓰레드들이 직접한다. 커넥터는 Task를 관리하는 역할을 한다. 예를 들면 다음 작업 같은 내용일 것이다
- 어떤 Task에게 어떤 작업을 분배할지
- Task가 죽은 경우, 새로운 Task를 생성하며 리밸런싱
사용 가능한 카프카 커넥터는 이곳(Home | Confluent Hub)에서 확인할 수 있다. 내가 실습에서 많이 사용해본 카프카 커넥터는 다음과 같다.
- Jdbc Source / Sink Connector
- debezium CDC source Connector
- Elasticsearch Sink Connector
- File Connector
- MongoDB source / Sink Connector
Task
Task는 데이터를 직접 가져오고 넣어주는 역할을 한다. 각각의 커넥터는 데이터를 복사하기 위해서 여러 Task들을 생성해서 관리한다. 이 때 커넥터는 해야하는 일을 작은 단위의 일로 쪼개서 Task들에게 분배할 수도 있는데, 이 경우 Task들은 병렬적으로 일을 할 수 있게 된다.
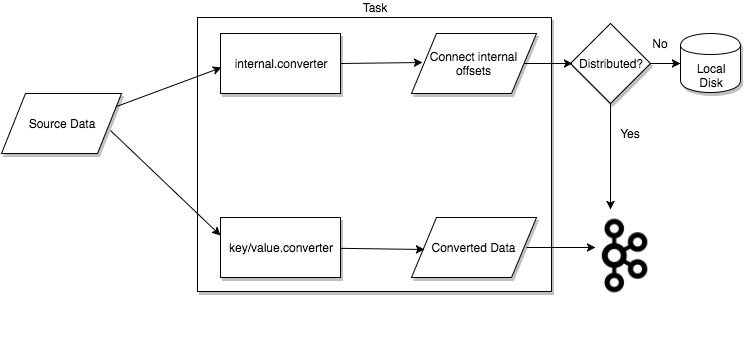
Task는 자신의 상태를 저장하지 않는다. Task의 상태는 단일 모드라면 로컬 저장소에 저장된다. 반면 분산 모드라면 config.storage.topic / status.storage.topic에 저장된다. 이처럼 Task의 상태가 카프카에 저장되기 때문에 커넥트 노드에 문제가 발생했을 때, 손쉽게 다른 커넥트 노드에서 Task, Connector가 생성될 수 있게 된다.
Task 리밸런싱
Consumer가 동일한 양을 가져가기 위해서 리밸런싱 되는 것처럼 커넥트의 Task 역시 리밸런싱 된다. 경우를 나눠서 살펴보면 다음과 같다.
- 처음 커넥터가 REST API로 제출되었다면, 모든 Worker(커넥트)는 현재 커넥트 클러스터 전체에 존재하는 커넥터와 커넥터의 Task의 양을 확인해서 각 커넥트에 공평히 분산될 수 있도록 리밸런싱을 한다.
- 커넥트 노드가 줄어들고 증가할 때는 Task, Connector는 자동으로 리밸런싱 된다.
- Task가 실패했을 때는 예외적인 경우로 간주해서 리밸런싱이 발생하지 않는다. 실패한 Tasks는 프레임워크가 관리해주지 않고, REST API를 이용해서 수동으로 재시작해야한다.

위의 이미지를 살펴보면 좀 더 이해가 쉽다. 건강한 상태에서 Worker2가 실패한 경우, 자동으로 리밸런싱이 트리거된다. 따라서 Worker2에 있던 Task2, Task3은 Worker1 / Worker3으로 각각 리밸런싱 된다.
Workers
커넥터와 Task는 논리적인 작업의 단위다. 논리적인 작업들은 프로세스 위에서 실행되어야 하는데, 이 논리적인 작업들을 실행시켜주는 프로세스를 Worker라고 한다. Worker는 쉽게 말해서 카프카 커넥트 프로세스를 의미한다. 커넥트는 Standalone / Distriubted 모드가 존재한다. 각각의 장단점이 존재한다.
Stand-alone은 싱글 커넥트 프로세스이기 때문에 설정이 최소화 된다. 따라서 쉽게 시작할 수 있어서 간단히 개발을 해보거나 테스트를 해볼 때 유용하게 사용할 수 있다. 그렇지만 작업을 위한 메타 정보가 로컬에 저장되기 때문에 확장성, 고가용성을 제공하지 않는다.
Distributed 모드는 작업에 필요한 상태 메타 정보를 카프카 토픽에 저장한다. 따라서 확장이 자유롭고 고가용성을 제공한다. Distrbiuted 모드는 설정 파일의 group.id가 같은 값을 가지는 커넥트 Worker들끼리 하나의 클러스터처럼 동작하게 한다. 분산 모드에서 커넥트가 추가되고, 삭제되고, 문제가 발생하면 나머지 커넥트 워커들이 이 상황을 인지하고 connector, task를 다시 재분산해주는 작업을 한다.
Dead Letter Que
Sink Connector에 때로는 잘못된 메세지가 전달될 수 있다. 한 가지 예로는 Sink Connector는 Avro Type을 원하지만, Json Type으로 포멧팅 되어서 온 메세지인 경우다. 이렇게 Sink Connector에 잘못된 메세지가 전달된 경우 Sink Connector는 두 가지 중 하나를 선택할 수 있다.
- errors.tolerance = None (default)
- errors.tolerance = ALL
만약 errors.tolerance를 None으로 선택하면 잘못된 메세지가 전달되었을 때, 카프카 커넥터는 즉시 '실패 상태'로 바뀐다. 커넥트에는 실패 상태와 관련된 로그가 남겨지고, 이 로그를 분석해서 잘못된 부분을 해결해서 커넥터를 재시작해야한다.
만약 errors.tolerance를 ALL로 선택하면 모든 에러와 잘못된 메세지는 무시된다. 즉, 에러가 발생해도 Sink Connector는 계속 일을 한다. 그리고 커넥트에는 어떤 에러 로그도 남지 않는다. 이 때 얼마만큼의 메세지가 실패했는지를 알고 싶다면 internal metric(https://docs.confluent.io/platform/current/kafka/monitoring.html#kafka-monitoring)을 이용해서 Source에서 제공된 메세지의 갯수와 Sink에서 처리한 메세지의 갯수를 비교하는 작업을 해야한다.
또한 error.tolerance를 ALL로 선택한다면 실패한 메세지들을 특정 토픽으로 라우팅하는 작업을 할 수 있다. 이처럼 실패한 메세지들을 담아두는 토픽을 Dead Letter Que라고 한다. Dead Letter Que를 사용하고 싶다면 Sink Connector의 Config 파일에 다음 두 가지 내용을 추가해두면 된다.
errors.tolerance = all
errors.deadletterqueue.topic.name = <dead-letter-topic-name>
// 에러 메세지가 왜 발생했는지에 대한 이유도 함께 저장됨.
errors.deadletterqueue.context.headers.enable = true위의 설정값을 커넥터 config 값에 추가해주면 에러 메세지가 발생했을 때 자동으로 dead letter queue 토픽으로 라우팅 된다. 또한 헤더에 에러 메세지가 왜 발생했는지도 추가할 수 있는데, 메세지의 기존 헤더와 구별하기 위해 헤더의 키는 _connect.errors로 나온다.
SMT(Single Formation Translation)
SMT에 대한 간단한 요약은 다음과 같다.
- SMT는 Source에서 메세지를 읽어온 후, Sink에 메세지를 넣기 전에 메세지를 간단하게 Transformation 하는 역할을 한다.
- SMT는 체이닝된다.
Source 시스템에서 읽어온 데이터를 카프카로 보내기 전에 변형을 해야하는 경우, 카프카에서 불러온 메세지를 Sink 시스템에 넣어주기 전에 메세지를 변형해야하는 경우가 있을 수 있다. 이런 경우에는 SMT를 이용해서 간단히 메세지를 변형할 수 있다.
SMT는 카프카 커넥트가 자체적으로 지원하는 클래스들이 존재하고 이곳(Get started with Single Message Transforms for Managed Connectors | Confluent Documentation)에서 사용법과 종류를 확인할 수 있다.

SMT가 동작하는 부분은 위의 그림에서 확인할 수 있다.
Source System → Source Connector → SMT1 → SMT2 ... → SMT10 → Converter → Broker
Broker → Converter → SMT1 → SMT2 ... → SMT10 → Converter → Sink System
그림에서 볼 수 있듯이 SMT는 체이닝 형태로 동작한다. 체이닝 형태로 동작을 한다고 해서 카프카 커넥트를 사용할 사람이 직접 코딩을 해야하는 것은 아니다. 설정 파일을 적절히 설정해서 SMT가 체이닝 형태로 동작하게 할 수 있다.
Converter
간단히 Converter를 요약하면 다음과 같다.
- 카프카 메세지의 직렬화 / 역직렬화를 해준다.
- 필요한 경우 스키마 레지스트리와 통신한다.
- 메세지를 보낼 때 포멧팅 역할을 한다.
- AvroConverter, JSON Converter가 제공되고 Config 파일에서 어떤 컨버터를 사용할 지 설정할 수 있다.
Converter는 카프카 커넥트 프레임워크의 구성 요소 중 하나다. Converter는 AvroConverter, JSON Converter가 존재한다. 종류만 봐도 알 수 있겠지만, 메세지의 직렬화 / 역직렬화를 해주는 역할을 한다. 또한 스키마 레지스트리를 이용하는 경우 Converter에서는 현재 메세지의 스키마를 등록하거나 읽어오는 역할까지 해준다.

Converter는 역직렬화 / 직렬화를 해서 데이터를 보내주거나 읽어오는 역할을 하는데, 이것은 바꿔 이야기하면 Converter는 특정한 직렬화/역직렬화 객체를 가진 Consumer / Proudcer인 것을 의미한다.
Config
카프카 커넥터는 카프카 커넥트 위에서 각자의 설정값을 바탕으로 기동된다. 하나의 Connector에는 하나의 Config가 있어야 한다고 봐도 무방하다. 카프카 Config는 다음과 같은 형태를 가진다.
// mysql_debezium_connector.json
{
"name": "mysql_debezium_connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "localhost",
"database.port": "3306",
"database.user": "connect_dev",
"database.password": "connect_dev",
"database.server.id": "30001",
"database.server.name": "mysqlavro",
"database.include.list": "ops",
"table.include.list": "ops.customers, ops.products, ops.orders, ops.order_items, ops.boards",
"database.history.kafka.bootstrap.servers": "localhost:9092",
"database.history.kafka.topic": "schema-changes.mysql.oc",
"time.precision.mode": "connect",
"database.connectionTimezone": "Asia/Seoul",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://localhost:8081",
"value.converter.schema.registry.url": "http://localhost:8081",
"transforms": "rename_topic, unwrap",
"transforms.rename_topic.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.rename_topic.regex": "(.*)\\.(.*)\\.(.*)",
"transforms.rename_topic.replacement": "$1-$2-$3",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false"
}
}Kafka Connect의 REST API
카프카 커넥트는 REST API를 지원한다. REST API를 이용해서 현재 커넥터를 등록하거나, 커넥터의 상태 등을 확인하는 등 다양한 작업을 할 수 있다.
Confluent REST APIs | Confluent Documentation
참고
'Kafka eco-system > Kafka Connector' 카테고리의 다른 글
| 카프카 커넥트 : 커넥트의 파티셔닝 (0) | 2023.01.17 |
|---|---|
| Kafka Connect : 카프카 커넥트 내부 토픽 이해 (0) | 2023.01.15 |
| 카프카 커넥트 Cluster 아키텍쳐 (0) | 2023.01.15 |