
카프카 커넥트 Cluster 아키텍쳐
- Kafka eco-system / Kafka Connector
- 2023. 1. 15.
카프카 커넥트의 기동 모드
- connect-distributed
- connect-mirror-maker
- connect-standalone
카프카 커넥트는 세 가지 기동 모드를 제공한다. 그렇지만 실제로 사용자가 사용하는 것은 distributed 모드만을 사용한다. distributed 모드와 standalone은 어떻게 다른 것일까?
The difference is in the class which is started and the configuration parameters which change how the Kafka Connect process decides where to store configurations, how to assign work, and where to store offsets and task statues. In the distributed mode, Kafka Connect stores the offsets, configs and task statuses in Kafka topics.
분산 클러스터 모드를 사용하게 되면 각 카프카 커넥트끼리는 일을 나눠가지면서 일을 하게 된다. 즉, 여러 카프카 커넥트가 협업할 수 있게 되는 것이다. 그리고 이를 위해서 카프카 커넥트의 필수적인 메타 정보들은 모두 카프카 토픽에 저장하게 된다. 위의 내용을 표로 정리하면 다음과 같다.
| 모드 | 메타 정보 | 워커 | 비고 |
| 단일 모드 | 로컬 저장소에 저장 | 1개 | - |
| 분산 모드 | 카프카에 저장 | 1개 이상 | group.id가 같아야 함. fail-over 등에서 자동으로 리밸런싱 제공 |
카프카 커넥트 distributed.properties 파일 살펴보기
카프카 커넥트를 실행할 때는 설정 파일과 함께 실행된다. 이 설정 파일에 카프카 커넥트의 실행에 필요한 여러 정보들이 들어있기 때문이다. 분산 모드에서 살펴볼만한 설정값들은 다음과 같다.
- group.id
- offset.storage.topic
- config.storage.topic
- status.storage.topic
아래 설정에서 각각의 내용을 좀 더 살펴본다. 한글로 번역된 내용은 이곳(Kafka Connect Configuration | 토리맘의 한글라이즈 프로젝트 (godekdls.github.io))에서 살펴볼 수 있다.
group.id
group.id는 카프카 커넥트가 속할 카프카 커넥트 클러스터의 그룹 명을 설정해야 한다. 이 값은 카프카 커넥트 클러스터끼리에서도 유일해야 하고 Consumer Group에서도 유일해야한다. 이것으로 미루어 보건데 카프카 커넥트의 group.id는 카프카 커넥트에서 사용할 컨슈머들의 Consumer Group과도 연결된 것으로 보인다.
아무튼 같은 group.id를 가진 카프카 커넥트들은 하나의 카프카 커넥트 클러스터에서 속해서 함께 일을 하게 된다.
offsets.storage
카프카 커넥트에서 Source Connector는 데이터를 읽어서 카프카로 보내준다. 카프카로 메시지를 보낼 때는 Kafka Producer를 이용해서 메세지를 보내준다. 이 때, Kafka Producer는 특정 Source System을 어디까지 읽어서 데이터를 보냈는지 기록하기 위해서 offfsets.storage를 이용한다. offsets 토픽의 기본 이름은 connect-offsets고, 다음과 같은 메세지가 저장되어 있다.
status.storage
status.storage의 기본 토픽 명은 connect-status다. connect-status에는 현재 카프카 커넥트 클러스터에 등록된 카프카 커넥터의 상태를 기록하는 토픽이다. 카프카 커넥트는 매번 커넥터의 상태를 connect-status에 저장해둔다. 재기동이 필요하다면, 재기동 할 때 connect-status 토픽에서 데이터를 읽어와서 기존의 카프카 커넥트 상태를 유지한다.
아래는 connect-status 토픽의 일부 메세지를 읽어왔다. key에는 Connector의 이름과 관련된 내용이 기록되어 있고, payload에는 현재 상태를 기록하고 싶은 내용들이 적혀져 있다. 한 가지 주의해서 살펴봐야 할 부분은 key의 이름에 여러 Prefix가 들어올 수 있다는 점이다.
status-topic-<커넥터 이름>
status-task-<커넥터 이름>
status-connector-<커넥터 이름>
다음과 같이 다양한 prefix가 커넥터 이름 앞에 붙은 Key를 볼 수 있는데 이것을 이용해서 다양하게 메세지를 관리하고 있는 것으로 보인다.
{
"topic": "connect-status",
"partition": 4,
"offset": 0,
"tstype": "create",
"ts": 1673759700293,
"key": "status-connector-postgres_jdbc_ops_sink_customers_avro_01",
"payload": "{\"state\":\"RUNNING\",\"trace\":null,\"worker_id\":\"127.0.1.1:8083\",\"generation\":8}"
}
{
"topic": "connect-status",
"partition": 4,
"offset": 1,
"tstype": "create",
"ts": 1673759701006,
"key": "status-task-postgres_jdbc_ops_sink_order_items_avro_01-0",
"payload": "{\"state\":\"RUNNING\",\"trace\":null,\"worker_id\":\"127.0.1.1:8083\",\"generation\":11}"
}
config.storage
default로 사용되는 config.storage의 토픽명은 connect-configs다. 이 토픽은 카프카 커넥터를 실행할 때 등록한 Config 메타 정보가 저장되는 곳이다. 커넥터가 등록될 때 이 토픽에 저장한다. 카프카 커넥트가 재기동 될 때 이 토픽에서 설정 정보를 읽어와서 처리한다.
아래는 connect-configs 메세지 중 일부 메세지다. key에는 커넥터의 이름이 들어가고 payload에는 해당 커넥터의 상세한 사항에 대해서 작성되어 있는 것을 볼 수 있다.
{
"topic": "connect-configs",
"partition": 0,
"offset": 22,
"tstype": "create",
"ts": 1673760549097,
"key": "task-mysql_cdc_ops_source_avro_01-0",
"payload": "{\"properties\":{\"connector.class\":\"io.debezium.connector.mysql.MySqlConnector\",\"transforms.rename_topic.regex\":\"(.*)\\\\.(.*)\\\\.(.*)\",\"tasks.max\":\"1\",\"database.history.kafka.topic\":\"schema-changes.mysql.oc\",\"transforms\":\"rename_topic, unwrap\",\"transforms.unwrap.drop.tombstones\":\"false\",\"transforms.unwrap.type\":\"io.debezium.transforms.ExtractNewRecordState\",\"value.converter\":\"io.confluent.connect.avro.AvroConverter\",\"key.converter\":\"io.confluent.connect.avro.AvroConverter\",\"database.connectionTimezone\":\"Asia/Seoul\",\"database.user\":\"connect_dev\",\"transforms.rename_topic.type\":\"org.apache.kafka.connect.transforms.RegexRouter\",\"database.server.id\":\"30001\",\"database.history.kafka.bootstrap.servers\":\"localhost:9092\",\"time.precision.mode\":\"connect\",\"database.server.name\":\"mysqlavro\",\"database.port\":\"3306\",\"value.converter.schema.registry.url\":\"http://localhost:8081\",\"task.class\":\"io.debezium.connector.mysql.MySqlConnectorTask\",\"database.hostname\":\"localhost\",\"database.password\":\"connect_dev\",\"name\":\"mysql_cdc_ops_source_avro_01\",\"table.include.list\":\"ops.customers, ops.products, ops.orders, ops.order_items, ops.boards\",\"key.converter.schema.registry.url\":\"http://localhost:8081\",\"database.include.list\":\"ops\",\"transforms.rename_topic.replacement\":\"$1-$2-$3\"}}"
}
카프카 커넥트 및 카프카 커넥터 구조
그렇다면 카프카 커넥트와 카프카 커넥터에서 각 구조는 어떻게 이루어져서 서로 상호작용을 할까? 아래에서 간략한 그림으로 설명을 해보고자 한다.
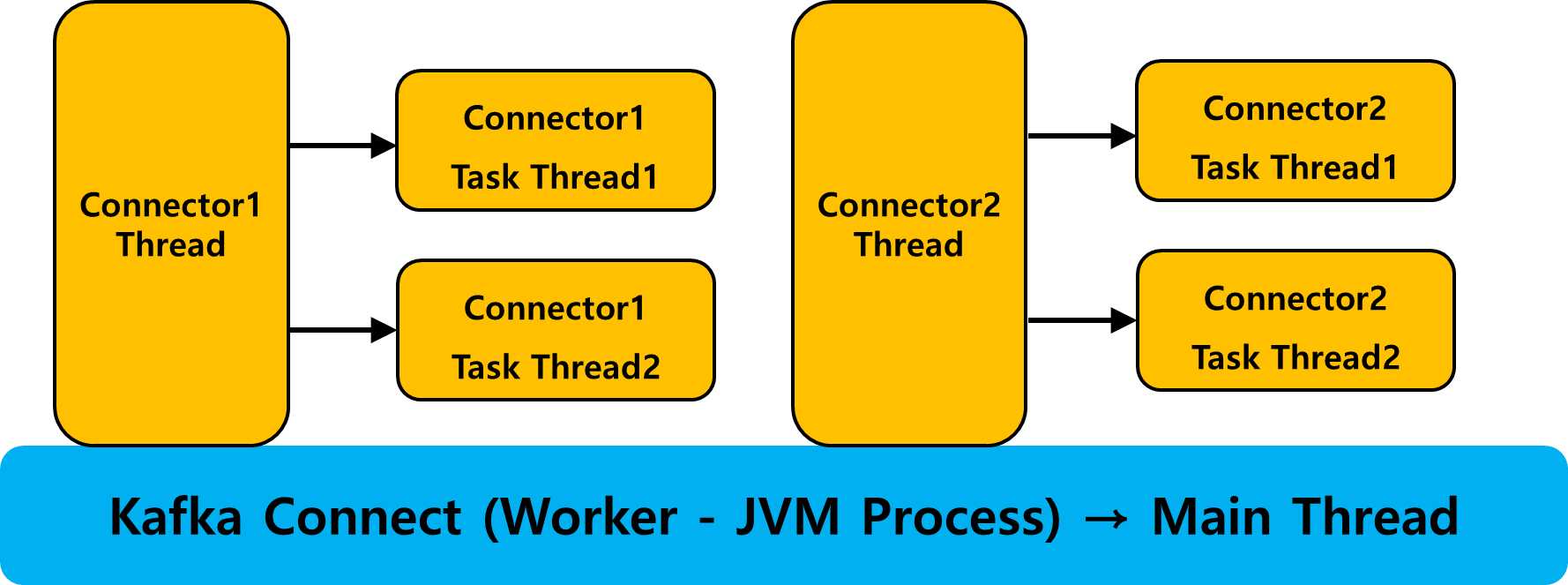
카프카 커넥트 실행
카프카 커넥트가 실행되면 Worker가 하나 실행된다. Worker는 흔히 알고 있는 JVM Process다. 리눅스의 ps 명령어를 이용해서 java Process가 떠있는 것을 확인할 수 있다. 이 때 카프카 커넥트는 JVM Process의 Main Thread를 주로 담당하게 된다. 즉, 카프카 커넥트 프레임워크의 JVM Process에 전반적인 자원이 관리되는 것을 알 수 있다.
카프카 커넥터 실행
카프카 커넥트가 실행되면 REST API를 이용해서 카프카 커넥터를 카프카 커넥트에 올릴 수 있다. REST API를 이용해서 카프카 커넥터를 등록하면, 카프카 커넥트 프로세스의 쓰레드에 커넥터 쓰레드가 추가된다. 커넥터 쓰레드는 실제로 일을 하는 주체는 아니다. 커넥트 위에 올라간 커넥터는 Task 단위로 일한다. Task는 쓰레드 단위로 분배가 된다. 즉, 커넥터를 하나 등록하게 되면 다음 쓰레드들이 카프카 커넥트 JVM 프로세스의 쓰레드로 등록된다.
- 커넥터 Instance 쓰레드
- 커넥터의 Task를 수행하는 쓰레드
- Task는 Source System / Sink System가 인터페이스 역할을 한다.
최소 2개의 쓰레드가 등록되고, 만약 커넥터가 Multi Task를 지원한다면 커넥터에는 Task 쓰레드가 여러 개가 등록된다는 것을 의미한다.
Jstack으로 살펴보기
Jstack을 이용하면 위의 내용을 실제로 확인해 볼 수 있다. 카프카 커넥트 프로세스를 Jstack으로 찍어봤을 때, 아래 쓰레드가 있는 것을 확인할 수 있다. 여러 쓰레드 쌍이 존재하지만, 하나만 살펴보면 다음과 같다.
- connector-thread-postgres
- task-thread-postgres
커넥터 인스턴스 쓰레드 하나와 테스크 쓰레드가 사이좋게 하나씩 있는 것을 볼 수 있다. 만약 connector-thread-postgres 인스턴스 쓰레드가 여러 개의 task 쓰레드를 지원한다면 task-thread-postgres는 여러 개가 생길 수 있다.
"connector-thread-postgres_jdbc_ops_sink_boards_avro_01" #60 prio=5 os_prio=0 cpu=16.86ms elapsed=81.47s tid=0x00007f2a044bb800 nid=0x3a227 in Object.wait() [0x00007f29c7ffe000]
"connector-thread-postgres_jdbc_ops_sink_order_items_avro_01" #61 prio=5 os_prio=0 cpu=19.52ms elapsed=81.44s tid=0x00007f29f800e000 nid=0x3a228 in Object.wait() [0x00007f29c7efd000]
"connector-thread-postgres_jdbc_ops_sink_products_avro_01" #63 prio=5 os_prio=0 cpu=12.52ms elapsed=81.27s tid=0x00007f29f400b000 nid=0x3a229 in Object.wait() [0x00007f29c7dfc000]
"connector-thread-postgres_jdbc_ops_sink_customers_avro_01" #62 prio=5 os_prio=0 cpu=3.62ms elapsed=81.25s tid=0x00007f29f000a000 nid=0x3a22a in Object.wait() [0x00007f29c7cfb000]
"connector-thread-postgres_jdbc_ops_sink_orders_avro_01" #64 prio=5 os_prio=0 cpu=5.01ms elapsed=81.24s tid=0x00007f29fc004800 nid=0x3a22b in Object.wait() [0x00007f29c7bfa000]
"task-thread-postgres_jdbc_ops_sink_order_items_avro_01-0" #66 prio=5 os_prio=0 cpu=287.96ms elapsed=78.90s tid=0x00007f29f8019800 nid=0x3a22f runnable [0x00007f29c75f7000]
"task-thread-postgres_jdbc_ops_sink_products_avro_01-0" #70 prio=5 os_prio=0 cpu=246.04ms elapsed=78.89s tid=0x00005639067bf000 nid=0x3a230 runnable [0x00007f29c74f6000]
"task-thread-postgres_jdbc_ops_sink_customers_avro_01-0" #69 prio=5 os_prio=0 cpu=220.45ms elapsed=78.89s tid=0x00007f2a040db000 nid=0x3a231 runnable [0x00007f29c73f5000]
"task-thread-postgres_jdbc_ops_sink_orders_avro_01-0" #68 prio=5 os_prio=0 cpu=240.99ms elapsed=78.89s tid=0x00007f29f4026800 nid=0x3a232 runnable [0x00007f29c72f4000]
"task-thread-postgres_jdbc_ops_sink_boards_avro_01-0" #67 prio=5 os_prio=0 cpu=199.66ms elapsed=78.89s tid=0x00007f29f0021800 nid=0x3a233 runnable [0x00007f29c71f3000]
카프카 커넥트 클러스터
카프카 커넥트는 distrbiuted mode를 지원하고, 이 모드는 여러 노드에 있는 카프카 커넥트 인스턴스를 하나의 클러스터로 속하게 해서 상호 협력해서 일을 하도록 도와준다. 카프카 커넥트가 distriubted.mode로 실행되어서 같은 클러스터에 존재하기 위해서는 카프카 커넥트가 실행될 때 같은 group.id를 가지도록 설정해야한다. 실제 상호 작용은 아래 그림처럼 하게 된다.
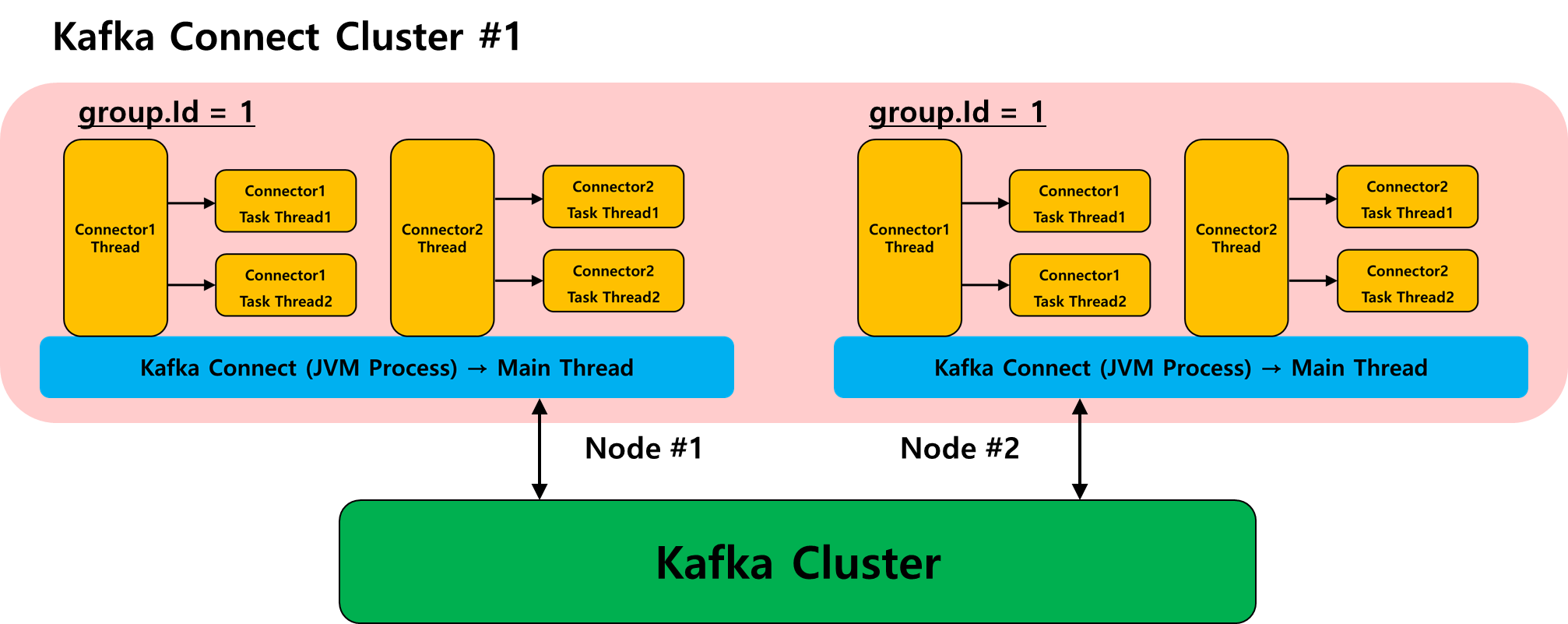
'Kafka eco-system > Kafka Connector' 카테고리의 다른 글
| 카프카 커넥트 : 커넥트의 파티셔닝 (0) | 2023.01.17 |
|---|---|
| Kafka Connect : 카프카 커넥트 내부 토픽 이해 (0) | 2023.01.15 |
| Kafka Connect 개념 (0) | 2023.01.15 |

