Kafka Broker : Replication
- Kafka eco-system/Kafka
- 2022. 11. 29.
들어가기 전
이 글은 실전 카프카 개발부터 운영까지 4장을 공부하며 정리한 글입니다.
4.1 카프카 리플리케이션
카프카는 초기 설계 단계부터 브로커 몇 대가 죽더라도 안정적으로 서비스 할 수 있도록 설계되었다. 카프카가 안정적으로 서비스 할 수 있는 이유는 바로 Replication 동작을 하기 때문이다. Replication은 복제를 의미한다. 즉, 하나의 브로커가 죽더라도 다른 브로커가 대신할 수 있도록 '복제' 해둔다.
4.1.1 리플리케이션 동작 개요
선요약을 하면 다음과 같다.
- 카프카는 토픽을 생성할 때 replication-factor를 이용해서 복제본을 몇개 생성할 지를 결정한다.
- 이 복제본은 원본이 파손되었을 때, 즉시 원본으로 대체해서 사용하는 녀석이다.
- replication-factor 덕분에 N개의 replication을 생성한다면, N-1개의 브로커가 죽어도 안정적으로 데이터를 공급할 수 있다.
카프카가 리플리케이션 동작을 하기 위해서 토픽을 생성할 때 'replication-factor' 옵션을 줘서 토픽을 생성해야한다. 예를 들면 아래 명령어로 토픽을 생성할 수 있다. 아래 명령어는 리플리케이션 3개로 보호되는 토픽이 생성되는 명령어다. 이 명령어로 토픽을 생성하면 3개의 브로커들에게 각각 토픽이 생성된다. 이 중 1개는 원본, 2개는 복제본으로 볼 수 있다. 복제본은 원본이 파손되었을 때 사용될 녀석이다.
$ kafka-topics --bootstrap-server localhost:9092 --topic my-topic1 \
--create --partitions 1 \
--replication-factor 3생성된 토픽에 메세지를 공급하고 모든 브로커에서 아래 명령어를 이용해서 토픽의 세그먼트 파일(.log)을 읽어볼 수 있다. 이 명령어를 이용하면 시작 오프셋 위치, 메세지 카운트, 어떤 메세지 인지를 알아볼 수 있다. replication-factor를 3으로 했으니 3개의 브로커에서 동일한 토픽 파티션이 있는 것을 볼 수 있다. 하나하나 세그먼트 파일을 읽어보면 모두 동일한 값을 보여주는 것을 알 수 있다 .
$ kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic topic-1
>>>>
Topic: topic-1
TopicId: 9oPfYgAHS4uNUDDThuA-0Q
PartitionCount: 1
ReplicationFactor: 4
Configs:
Topic: topic-1 Partition: 0 Leader: 1 Replicas: 1,4,2,3 Isr: 1,2,3describe 명령어를 이용해서 해당 토픽을 좀 더 살펴볼 수 있다. 여기서 리더 파티션, Rreplicas, ISR이 존재하는 것을 볼 수 있다. 총 4개의 복제본이 있으나, 실제로 리더로 바로 사용할 수 있도록 SYNC 된 녀석은 1,2,3 브로커에 있는 녀석으로 이해할 수 있다.
$ kafka-dump-log --print-data-log \
--files /data/kafka-logs/my-topic1/000000000000000.log
Dumping 00000000000000000000.log
Log starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: 0 lastSequence: 0 producerId: 0 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1669685785081 size: 73 magic: 2 compresscodec: none crc: 579655456 isvalid: true
| offset: 0 CreateTime: 1669685785081 keySize: -1 valueSize: 5 sequence: 0 headerKeys: [] payload: hello
baseOffset: 1 lastOffset: 2 count: 2 baseSequence: 0 lastSequence: 1 producerId: 1 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 73 CreateTime: 1669685860527 size: 90 magic: 2 compresscodec: none crc: 848081722 isvalid: true
| offset: 1 CreateTime: 1669685859561 keySize: -1 valueSize: 7 sequence: 0 headerKeys: [] payload: hello 2
| offset: 2 CreateTime: 1669685860527 keySize: -1 valueSize: 7 sequence: 1 headerKeys: [] payload: hello 3
baseOffset: 3 lastOffset: 4 count: 2 baseSequence: 0 lastSequence: 1 producerId: 2 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 163 CreateTime: 1669685885880 size: 88 magic: 2 compresscodec: none crc: 547481039 isvalid: true
| offset: 3 CreateTime: 1669685885120 keySize: -1 valueSize: 6 sequence: 0 headerKeys: [] payload: hello4
| offset: 4 CreateTime: 1669685885880 keySize: -1 valueSize: 6 sequence: 1 headerKeys: [] payload: hello5
baseOffset: 5 lastOffset: 5 count: 1 baseSequence: 2 lastSequence: 2 producerId: 2 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 251 CreateTime: 1669685886824 size: 74 magic: 2 compresscodec: none crc: 982663134 isvalid: true
| offset: 5 CreateTime: 1669685886824 keySize: -1 valueSize: 6 sequence: 2 headerKeys: [] payload: hello6
baseOffset: 6 lastOffset: 6 count: 1 baseSequence: 3 lastSequence: 3 producerId: 2 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 325 CreateTime: 1669685888801 size: 74 magic: 2 compresscodec: none crc: 604455608 isvalid: true
| offset: 6 CreateTime: 1669685888801 keySize: -1 valueSize: 6 sequence: 3 headerKeys: [] payload: hello7
baseOffset: 7 lastOffset: 7 count: 1 baseSequence: 4 lastSequence: 4 producerId: 2 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 399 CreateTime: 1669685890040 size: 74 magic: 2 compresscodec: none crc: 3722924148 isvalid: true
| offset: 7 CreateTime: 1669685890040 keySize: -1 valueSize: 6 sequence: 4 headerKeys: [] payload: hello위의 명령어를 이용해서 각 로그 파일을 읽어보려면 다음 명령어를 이용해서 읽을 수 있다.
- Log Strating offset : 이것을 통해서 시작 오프셋 위치가 0인 것을 알 수 있다.
- Producer ID : 카프카 브로커는 프로듀서가 메세지를 보내려고 요청할 때 PID를 생성해서 전달해준다. 0,1,2로 되어있는데 세번에 걸쳐서 서로 다른 프로듀서로 보낸 것을 알 수 있다.
- baseSequence, lastSequence : Idempotence에서 이용하는 메세지 Sequence다. PID가 바뀔 떄 마다 이 Sequence 값이 바뀌는 것을 볼 수 있다.
- Payload : 실제 메세지가 적재되는 곳이다.
4.1.2 리더와 팔로워
선요약을 하면 다음과 같다.
- replication을 하면 각 토픽의 파티션은 리더 파티션 / 팔로워 파티션으로 나누어진다.
- 프로듀서와 컨슈머는 리더 파티션에만 데이터를 읽고 쓴다.
아래 명령어를 이용해서 토픽을 살펴보면 파티션 리더 / ISR이 존재하는 것을 알 수 있다. 이것은 어떤 것을 의미하는 것일까? 먼저 리더라는 것부터 알아보자.
$ kafka-topics --bootstrap-server localhost:9092 --topic my-topic --describe카프카는 Replication을 리더와 팔로워로 구분한다. 리더 파티션은 Replication 중에 하나가 선정되는 것이고, Producer / Consumer는 오로지 리더 파티션에만 접근한다. 그리고 팔로워 파티션은 리더 파티션에게 메세지 데이터를 요청해서 데이터를 복제하는 역할을 한다. 이들의 관계도를 그림으로 살펴보면 아래와 같다.

프로듀서 / 컨슈머는 오로지 파티션 리더에게만 데이터를 전달하고 읽어온다. 파티션 팔로워들은 리더 파티션에게 메세지를 요청해서 데이터를 복제한 뒤 저장해두는 역할을 한다.
4.1.3 복제 유지와 커밋
선요약을 하면 다음과 같다.
- 리더 / 팔로워 파티션은 ISR로 관리된다.
- 리더 파티션은 팔로워 파티션이 ISR에 있을 수 있는지 모니터링, 관리하는 역할을 한다.
- 리더 파티션은 replication에 모두 복제된 녀석들만 commit해서 commit offset으로 관리하고, Consumer는 commit offset까지의 메세지만 읽을 수 있다.
- Replication의 마지막 커밋 오프셋 위치를 High Water Mark라고 한다.
리더, 팔로워 파티션은 ISR(In-Sync-Replica)라는 논리적 그룹으로 묶여져있다. ISR 그룹은 정상적으로 데이터를 복제하고 있는 파티션의 모임으로 이해를 하면 되는데, ISR에 포함되어있는 파티션들만 리더 파티션이 될 자격이 있다. ISR 내의 팔로워 파티션은 리더 파티션의 메세지를 지속적으로 복제한다. 리더 파티션은 ISR 내의 팔로워 파티션들이 정상적으로 동작하는지를 감시한다. 리더 파티션은 ISR 내의 팔로워 파티션이 일정 시간 이상 데이터 복제를 요청하지 않으면 문제가 발생한 것으로 판단하고 ISR에서 해당 팔로워 파티션을 제외시킨다.

IRS 내의 모든 팔로워의 메세지가 복제되면 리더 파티션은 내부적으로 커밋되었다는 표시를 하게 되고 이 값은 replication-offset-checkpoint라는 파일에 남겨지게 된다. 그리고 마지막 커밋 Offset의 위치를 High Water Mark라고 부르고, Consumer는 High Water Mark까지만 메세지를 읽어갈 수 있게 된다. 그 이유는 메세지의 일관성을 보장하기 위해서다.
아래 명령어를 이용해서 현재 replication의 커밋 오프셋을 토픽마다 살펴볼 수 있다. 다시 한번 정리하면 replication-offset-checkpoint에 기록된 커밋 오프셋까지만 각 컨슈머들은 읽어갈 수 있다.
$ cat /data/kafka-logs/replication-offset-checkpoint
>>> 출력 결과
### 토픽명-파티션-커밋 오프셋
my-test 0 5
왜 브로커에서 커밋된 메세지만 읽어야할까?
아래 조건을 먼저 가정하고 시작해보자.
- 커밋된 메세지는 Test Message 1만 존재함.
- ConsuemerA, ConsumerB는 해당 토픽을 구독함.
- 리더 파티션은 다시 선출됨.
커밋되지 않은 메세지를 모두 읽는 경우를 한번 살펴보자. 아래 상황에서 ConsumerA가 리더 파티션으로부터 메세지 1,2,3을 읽어왔다. 그런데 이 때 ConsuemerB도 메세지를 읽고 있는데, Consumer B가 메세지를 읽어오려고 할 때 공교롭게도 리터 파티션이 새롭게 선출되었다고 해보자.

ConsumerB는 새롭게 선정된 리터 파티션으로부터 메세지를 읽어온다. 그런데 이 리더 파티션이 가지고 있는 메세지는 Test Message1 밖에 없다. 결론을 다시 정리하면, 커밋되지 않은 메세지를 Consumer들이 읽어갈 수 있게 되면 리더 파티션이 새롭게 선정되는 과정에서 서로 다른 메세지를 읽어가게 되면서 정합성이 맞지 않게 된다.

4.1.4 리더와 팔로워의 단계별 리플리케이션 동작
선요약은 다음과 같다.
- 팔로워 파티션은 리더 파티션에게 offset을 넣은 fetch 요청을 보내서 메세지를 가져온다.
- 리더 파티션은 팔로워 파티션에게서 fetch 요청을 받으면 이전 offset을 커밋한다.
- 왜냐하면 이전 Offset까지 잘 받았다는 것을 의미하기 때문이다.
- 리더 파티션은 fetch 요청에 대한 응답으로 최근에 커밋된 offset과 메세지를 함께 내려준다.
- 팔로워 파티션은 커밋된 offset을 받으면, 본인에게도 커밋된 offset을 업데이트한다.
팔로워 파티션은 리더 파티션에게 fetch 요청을 하면서 메세지를 replication한다. 팔로워 파티션은 fetch 요청을 할 때 가져와야 할 Offset 번호를 넣는다. 한편 리더 파티션은 fetch 요청을 받으면 어떤 offset에 대한 메세지를 줘야하는지를 확인할 수 있다. 리더 파티션은 이 offset에 대한 메세지를 팔로워 파티션에게 전달해준다.
한편 리더 파티션은 fetch 요청으로 팔로워 파티션이 어떤 offset을 원하는지를 안다. 이것은 팔로워 파티션이 어떤 offset까지 잘 받았는지를 의미한다. 따라서 리더 파티션은 팔로워 파티션에게 메세지를 전달했을 때, 팔로워 파티션이 메세지를 잘 받았는지를 더 확인할 필요가 없어진다. 카프카 브로커는 이 로직을 이용해서 통신 횟수를 줄이면서 좀 더 빠르고 안정적으로 동작할 수 있게 되었다.
리더 파티션은 모든 파티션이 메세지를 받은 경우 해당 오프셋을 커밋한다. 즉, 하이워터마크를 생성한다. 그리고 이 커밋 오프셋(하이 워터 마크)를 팔로워 파티션에게 함께 전달해준다. 팔로워 파티션은 이 메세지를 전달받으면 자신도 거기까지 정상적으로 받은 것으로 인지하고 동일하게 오프셋을 커밋하는 동작을 한다. 아래 그림에서 동작을 자세히 살펴볼 수 있다.
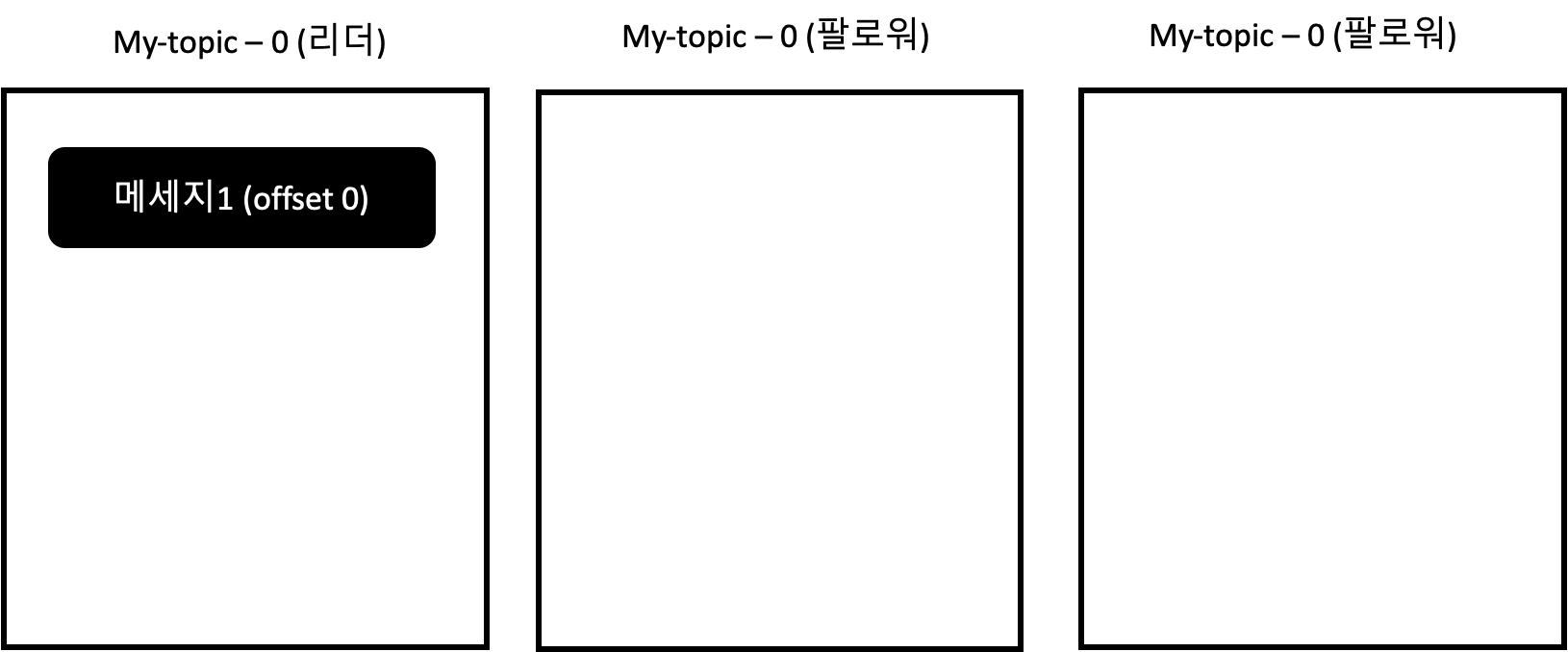
리더 파티션이 메세지를 전달받았다. 팔로워 파티션은 아직 리플리케이션을 하지 못한 상태다.
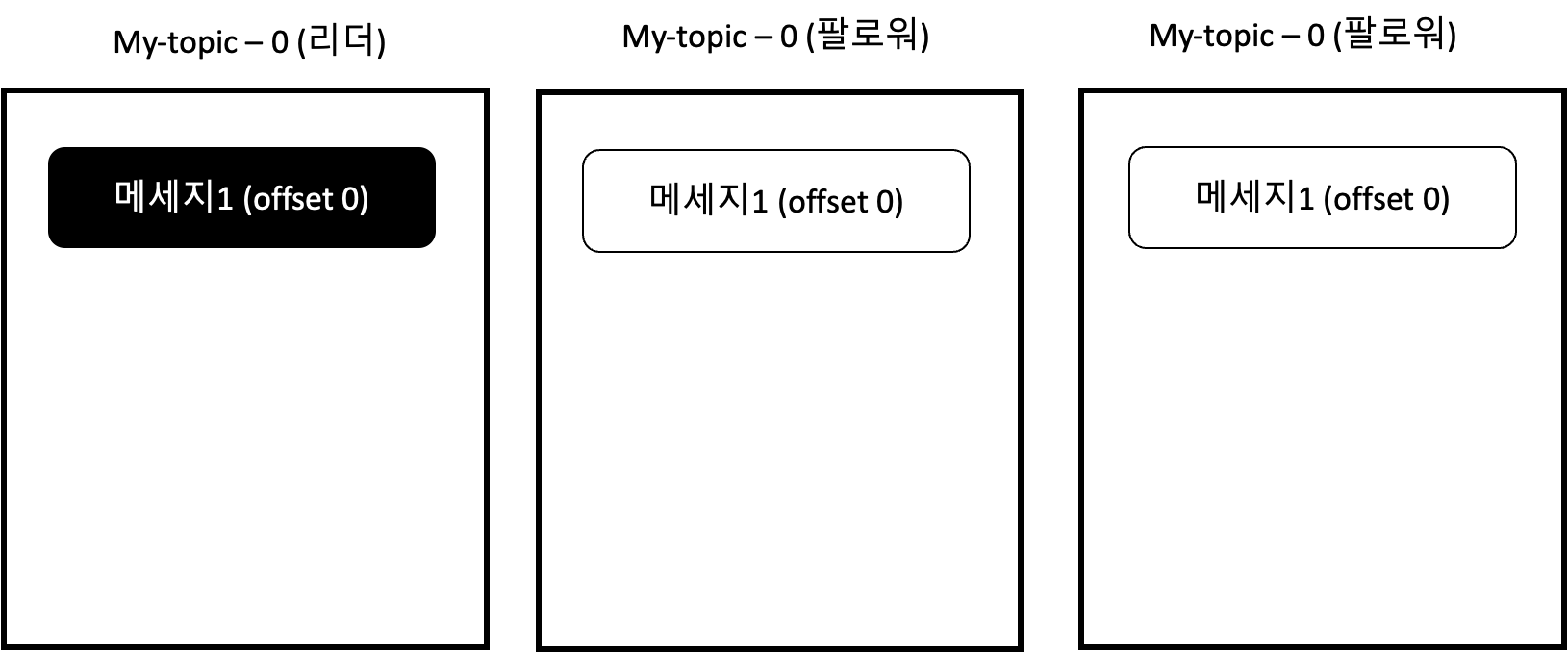
팔로워 파티션은 리더 파티션에게 offset0이 있다는 사실을 알고, offset0을 fetch 요청보낸다. 리더 파티션은 팔로워 파티션에게 offset0에 대한 메세지를 각각 전달해준다. 그리고 팔로워 파티션은 replication에 성공한다.

리더 파티션은 offset1 메세지를 받았다. 팔로워 파티션은 리더 파티션에게 offset1 메세지가 있는 것을 확인하고 offset1에 대한 fetch를 요청한다. 리더 파티션은 offset1에 대한 fetch 요청을 받으면서, 각 팔로워 파티션이 offset0을 정상적으로 수신한 것을 확인한다. 따라서 리더 파티션은 offset0을 커밋한다. 리더 파티션은 팔로워 파티션에게 응답할 때, offset1 메세지와 offset0이 커밋된 사실을 함께 내려준다.

한편 팔로워 파티션은 리더 파티션에게서 요청한 메세지를 전달받는다. 이 때, 리더 파티션에서 offset0이 커밋된 사실을 확인한다. 이후 팔로워 파티션은 offset0을 함께 커밋한다. 그리고 전달받은 offset1 메세지는 잘 저장한다.
4.1.5 리더 에포크와 복구
선요약을 하면 다음과 같다.
- 팔로워 파티션은 복구할 때, 가장 먼저 리더 에포크 요청을 통해서 자신의 하이워터마크를 업데이트한다. 자신이 가지고 있는 메세지가 정확한 메세지인지, 확신할 수 있는 메세지인지를 확인한 후 하이워터마크가 업데이트 된다.
- 팔로워 파티션은 복구할 때, 자신이 가지고 있는 하이워터마크보다 높은 오프셋은 모두 삭제한다.
- 리더 에포크는 각 토픽 파티션별로 관리되고 있고, 리더 에포크는 새로운 리더가 선출될 때 마다 버전이 업그레이드 된다.
- 리더 에포크는 각 버전별로 몇번째까지 정상인지를 의미한다.
리더 에포크(Leader Epoch)는 카프카의 Replication 파티션들이 복구 동작을 할 때 메세지의 일관성을 유지하기 위한 용도로 이용된다. 리더 에포크는 컨트롤러에 의해 관리되는 32비트의 숫자로 표현된다. 리더에포크는 복구 동작 시 하이워터마크를 대체하는 수단으로도 사용된다.
리더에포크는 왜 필요할까?
먼저 리더에포크가 없는 상태에서 장애 후 복원을 진행할 때, 발생할 수 있는 일을 살펴보면 왜 리더에포크가 필요한지 알 수 있다.

- 리더는 프로듀서로부터 메세지0을 받았고, 0번 오프셋에 저장했다. 팔로워는 리더에게 0번 오프셋 가져오기를 요청한다.
- 가져오기 요청으로 팔로워는 메세지0을 리더로부터 리플레케이션한다.
- 리더는 하이워터마크를 0으로 올림.
- 리더는 메세지1를 받고, 1번 오프셋에 저장했다.
- 팔로워는 메시지1를 가져오는 것을 요청하고, 리더는 응답으로 메세지1 + 하이워터마크 0을 내려준다. 팔로워는 이 응답을 받고 자신의 하이워터마크를 0으로 올리고, 메세지를 오프셋 1에 저장한다.
- 리더는 하이워터마크를 1으로 올림.
- 이 때, 하이워터마크를 살펴보면 리더는 1, 팔로워는 0이 된다. 그리고 메세지 오프셋은 리더는 1, 팔로워는 1이 된다.
이 상태에서 예상하지 못한 장애로 팔로워가 다운되었다고 가정해보자. 그럼 어떻게 동작할까?

- 팔로워는 자신이 갖고 있는 메세지들 중에서 자신의 하이워터마크보다 높은 메세지들은 신뢰할 수 없는 메세지로 판단하고 삭제한다. 따라서 1번 오프셋의 메세지1은 삭제된다.
- 팔로워는 리더에게 1번 오프셋의 새로운 메시지에 대해서 가져오기 요청을 보낸다.
- 이 때 리더 브로커가 장애가 발생하면서, 팔로워가 리더로 승격된다.
1번 상황에서 팔로워가 가지고 있는 메세지는 오프셋 0번까지가 된다. 이 때, 리더가 죽고 팔로워가 새로운 리더로 선출된다면 오프셋 1번 데이터는 영구적으로 유실되게 된다.
리더에포크가 있으면 어떻게 바뀔까?
앞서와 동일한 상태를 가정해보자. 하이워터마크는 리더1, 팔로워는0이다. 그리고 가지고 있는 메세지의 오프셋은 동일하게 1이다. 이 때 리더 에포크를 사용하면 어떻게 될까? 리더 에포크를 사용하는 경우에는 하이워터마크보다 앞에 있는 메시지를 무조건 삭제하는 것이 아니라 리더에게 리더 에포크 요청을 보낸다.

- 팔로워는 복구 동작을 하면서 리더에게 리더 에포크 요청을 보낸다.
- 요청을 받은 리더는 리더 에포크의 응답으로 하이워터마크 1번까지라는 메세지를 내려준다.
- 팔로워는 리더의 응답으로 받은 하이워터마크를 참고해서 자신의 하이워터마크를 올린다.
- 팔로워는 자신의 하이워터마크보다 높은 오프셋을 가진 메세지를 삭제한다.
리더 에포크를 사용하는 경우, 브로커는 복구 하는 과정에서 먼저 리더에게 리더 에포크 요청을 보내서 현재 어떤 하이워터마크까지 받았는지를 확인한다. 그리고 응답을 받아서, 자신의 하이워터마크에도 반영하는 작업을 함께 한다. 이후에 자신의 하이워터마크와 자신이 가지고 있는 메세지의 오프셋을 비교해서 삭제처리하는 작업을 진행한다. 이 작업을 통해서 자신의 메세지가 사라지는 것을 방지할 수 있다.
물론 이런 경우도 있을 것 같다. 자신의 하이워터마크는 1번, 오프셋은 2번, 리더 에포크의 하이워터마크는 3번인 경우가 있을 것 같다. 코드를 아직 보진 못했지만, 이런 경우에는 자신의 오프셋 2번에 맞춰서 하이워터마크를 올려주지 않을까 생각된다. 그리고 하이워터마크가 2가 되었으니, 자신은 다음부터는 3번 메세지를 가져올 것을 요청하면서 동작하지 않을까 싶다. (뇌피셜)
리더 에포크의 필요성 또 다른 예제
하이워터마크는 리더가 1, 팔로워가 0이다. 메세지는 리더가 1, 팔로워가 0인 상태를 가정해보자. 이 때, 다음과 같은 상황이 발생했다고 가정해보자.

- 리더에 장애가 발생함. 팔로워가 새로운 리더로 승급하게 됨.
- 새로운 리더에게 메세지 2가 오프셋 1로 들어옴. 그리고 하이워터마크가 1이 된다.
이 때 이전의 리더가 다시 살아나는 구조를 한번 생각해보자. 리더가 다시 살아나게 된다면 다시 복구 작업을 진행하게 될 것이다.
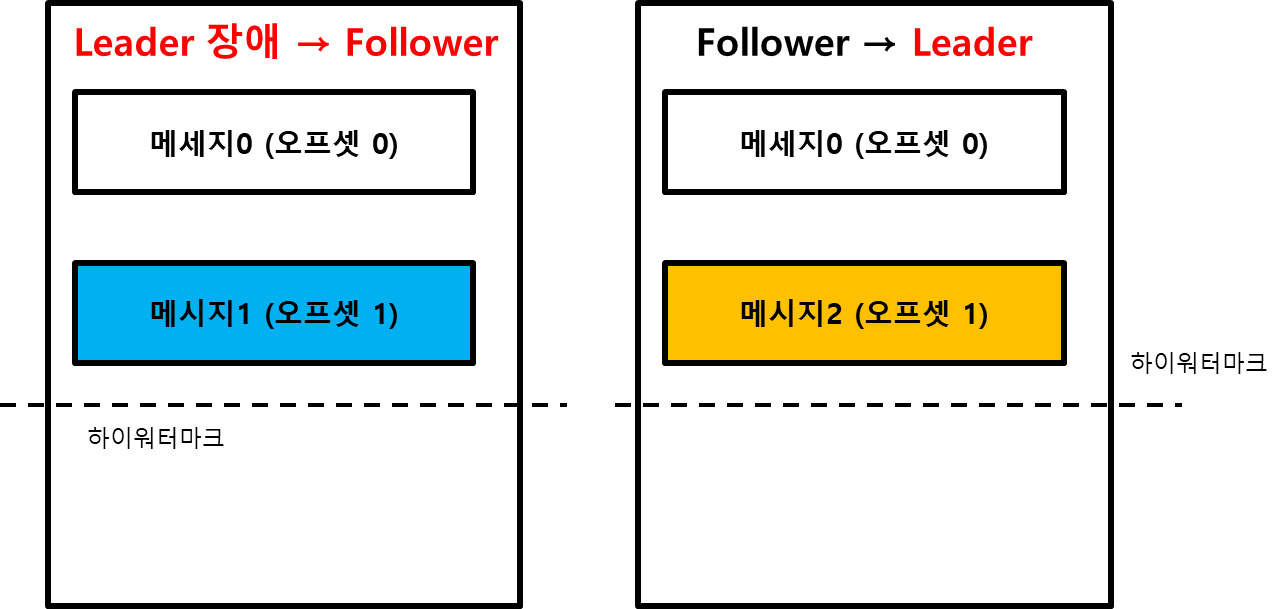
- 이전의 리더가 살아난다. 그렇지만 이미 리더가 있기 때문에 이 녀석은 팔로워가 된다.
- 이전의 리더는 새로운 리더에게 하이워터마크를 요청한다. 비교해보니 하이워터마크가 동일하게 1인 상태다. 따라서 이전 리더는 자신이 가지고 있는 메세지를 삭제하지 않는다.
이런 상태를 살펴보면 두 리플리케이션은 같은 오프셋을 가지고 있지만, 실제로 오프셋1에 저장된 메세지는 서로 다른 값을 가지고 있는 것을 볼 수 있다. 데이터의 정합성에 문제가 발생한다는 것이다. 이 부분을 리더 에포크를 이용하면 해결할 수 있게 된다.
요약하면 같은 하이워터마크 오프셋을 나타내는 것이 데이터의 정합성을 보장해주지는 않는다는 것이다. 위치만으로 복구하는 것은 정합성에 문제가 발생할 수 있다.
리더 에포크로 해결하는 방법
리더 에포크는 하이워터마크를 리더 에포크의 버전별로 관리한다. 리더가 바뀔 때마다 리더 에포크의 버전이 올라가고, 그 버전에 맞는 하이워터마크가 각각 기록되게 된다. 그리고 팔로워가 새로 복구를 하기 시작할 때는 각 리더 에포크의 버전에 대한 비교를 통해서 복구한다. 위의 예제를 살펴보면 새로운 리더는 자신이 팔로워 일 때의 하이워터마크, 그리고 새로운 리더일 대의 하이워터마크를 각각 기억한다는 점이다. 자세한 내용은 실습에서 알아볼 꺼지만 대략적인 느낌은 다음과 같다.
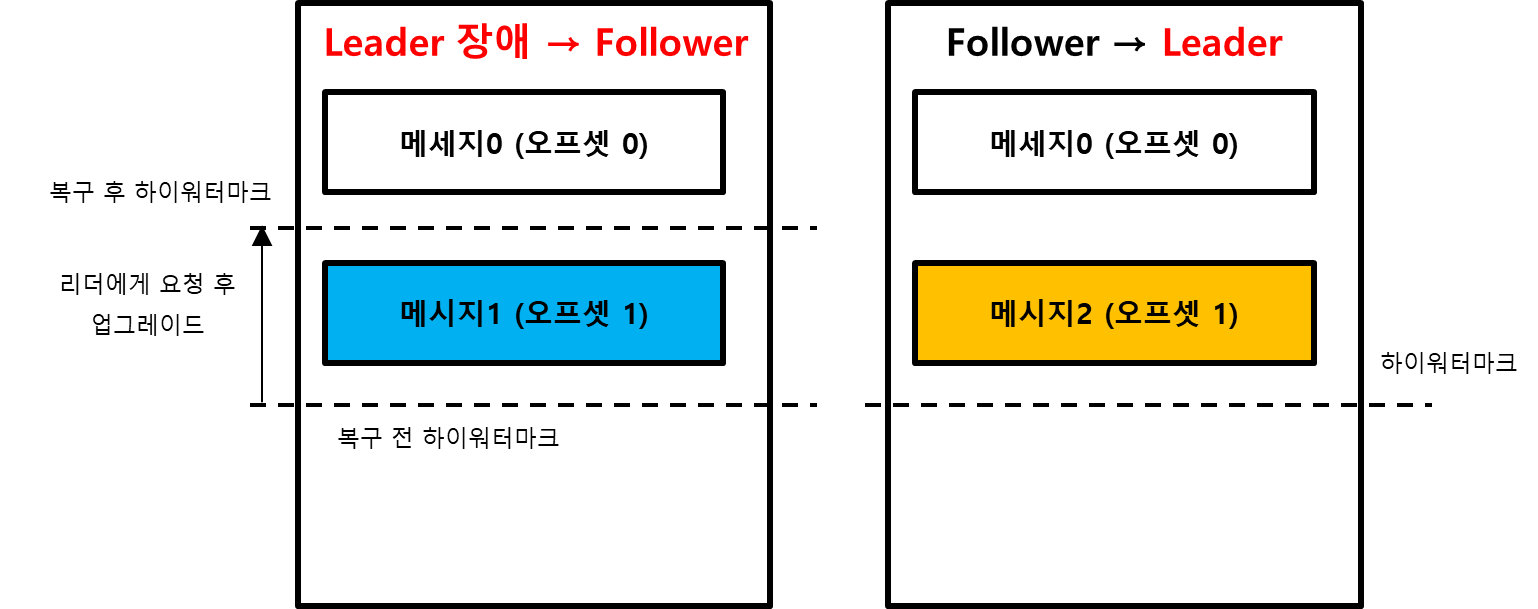
- 구 리더였던 브로커가 장애에서 복구된다. 이미 새로운 리더가 있기 때문에 이 녀석은 팔로워가 된다.
- 팔로워는 새로운 리더에게 리더 에포크 요청을 보낸다.
- 새로운 리더는 0번 오프셋까지 유효하다고 응답한다.
- 팔로워는 메세지 일관성을 위해서 로컬 파일에서 1번 오프셋인 메세지1을 삭제한다. (팔로워는 쓰기 권한이 없으므로 리더에게 메세지1을 추가할 수 없음)
- 팔로워는 리더로부터 1번 오프셋인 메세지 2를 리플리케이션할 준비를 한다.
리더 에포크 실습과정
STEP1. 토픽 생성
아래 명령어를 이용해 토픽을 생성하고 어떤 브로커에 토픽이 생성되었는지를 확인한다.
$ kafka-topics.sh --bootstrap-server localhost:9092 --topic topic-2 --create --replication-factor 2
$ kafka-topics.sh --bootstrap-server localhost:9092 --topic topic-2 --describe
>> 생성 결과
Topic: topic-2 TopicId: YFWx0zD1QSKUuTmwvbMSpA PartitionCount: 1 ReplicationFactor: 2 Configs:
Topic: topic-2 Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2생성 결과를 확인하면 브로커 1,2에 토픽 + 파티션이 생성된 것을 볼 수 있다.
STEP2. 리더 에포크 확인하기
현재 리더는 1번이기 때문에 1번 브로커에 접속해서 리더 에포크를 확인한다. 확인하면 아래 녀석이 생성된 것을 볼 수 있다.
$ cat leader-epoch-checkpoint
>>>
0
1 // 현재 리더 에포크 번호
0 0 // 리더 에포크 번호 + 최종 커밋 후 새로운 메세지를 전송받게 될 오프셋 번호
STEP3. 메세지 전송하기
아래 명령어를 이용해서 2개의 메세지를 보낸다.
$ kafka-console-producer.sh --bootstrap-server localhost:9092 --topic topic-2
>>
message1
message2
STEP4. 리더 에포크 확인하기
다시 리더 파티션으로 가서 리더 에포크를 확인한다. 아직까지는 변한 것이 없다. 왜냐하면 리더 에포크는 새로운 리더가 선출될 때 마다 업데이트 되는 것이기 때문이다.
$ cat leader-epoch-checkpoint
>>
0
1 // 현재의 리더 에포크 번호
0 0 // 리더 에포크 번호 + 커밋하면 받게 될 오프셋 번호
STEP5. 카프카 브로커 끄기 + 리더 에포크 번호 확인하기
1번 브로커가 죽었기 때문에 새로운 리더가 선출된다. 2번 브로커가 리더로 선출되었고, 새로운 리더가 선출되었기 때문에 리더 에포크가 업데이트 된다.
$ cat leader-epoch-checkpoint
>>
0
2 // 현재의 리더 에포크 번호
0 0 // 리더 에포크 번호 + 커밋하면 받게 될 오프셋 번호
1 2 // 리더 에포크 번호 + 커밋하면 받게 될 오프셋 번호1번 브로커가 죽기 전에 2개의 메세지를 받았고, 이 녀석들이 커밋되어 하이워터마크를 만들었기 때문에 리더 에포크는 다음과 같이 업데이트 된다.
현재의 리더 에포크 번호
리더 브로커 1번이 다운되면서 리더 에포크 번호는 1에서 2로 증가한다. 리더 에포크 번호는 하나씩 증가하고, 이 번호는 새로운 리더 파티션이 선출될 때 마다 일어난다.
새로 기록된 리더 에포크 번호
리더 에포크 번호가 1이었을 때를 기준으로 가장 마지막에 커밋된 후 새로 메세지를 받게 될 오프셋 번호를 기록한다. 2개의 메세지를 보냈고, 각각 0~1번 오프셋에 저장되었다. 커밋하면 2번 오프셋을 가리키게 된다. 따라서 1 2의 의미는 1번 리더 에포크 일 때는 0~1번 오프셋까지 진행되었다는 것을 의미한다.
STEP6. 카프카 브로커 켜기
1번 브로커를 다시 켠다. 이 녀석은 이전에는 리더였지만 다시 팔로워로 등장하게 된다. 이 녀석은 리더 에포크가 1번이었을 때 죽었다. 따라서 이 녀석은 새로운 리더에게 리더 에포크 1번에 대한 요청을 보내고, 새로운 리더는 이 녀석에게 리더 에포크 1번에 대한 커밋 오프셋은 2라는 응답을 내려준다. 응답을 받은 1번 브로커는 자신의 하이워터마크를 업데이트하고 메세지를 복원한다.
정리
리더 에포크는 리더 에포크 번호 / 리더 에포크의 커밋 오프셋으로 관리된다. 리더 에포크는 새로운 리더 파티션이 선출될 때 마다 리더 에포크가 업데이트 되는데, 이 때 리더 에포크는 새롭게 선출된 리더 파티션의 하이워터마크를 기준으로 업데이트 된다.
예를 들어 다음 상황을 가정해보자. 현재 리더 에포크 번호는 1일 때, 1번 리더의 하이워터마크는 3, 2번 팔로워의 하이워터마크가 1이라고 가정해보자. 이 때, 1번 브로커가 죽게 되면 2번이 리더로 선출되면서 리더 에포크가 업데이트 된다. 이 때 리더 에포크에는 다음과 같이 업데이트 될 것이다.
- 리더 에포크 번호 : 1
- 커밋 오프셋 : 1
이 상태에서 새롭게 리더로 선출된 2번 브로커는 리더 에포크 번호가 2번이 된다. 이 때 메세지 50개를 받아서, 브로커2의 하이워터마크가 51이 되었다고 해보자. 이 때 브로커 1이 다시 복구되면서, 브로커2에게 리더 에포크 번호 1에 대한 오프셋을 요청할 것이다. 브로커1은 하이워터마크가 3이었으나, 리더 에포크를 요청하면서 하이워터마크가 1이 된다. 그래서 브로커1은 하이워터마크가 1보다 큰 메세지들을 모두 삭제하고, 데이터를 다시 요청하는 방식이 될 것이다.
4.2 컨트롤러
선요약을 하면 다음과 같다.
- ISR 리스트는 고가용성을 위해 주키퍼에 저장된다.
- 컨트롤러는 카프카 클러스터 중 하나의 브로커가 맡아서 한다.
- 컨트롤러는 주키퍼의 정보를 감시하며, 브로커 실패를 감지한다.
- 컨트롤러는 브로커 실패가 감지되면 세 가지 작업을 한다.
- 새로운 리더를 선출한다.
- 선출한 리더에 대한 정보를 모든 브로커에게 전달한다.
- 선출한 리더에 대한 정보를 주키퍼에 기록한다.
- 예기치 않은 종료보다, 예정된 종료가 복구 시간 및 다운 타임이 더 적다.
- 예정된 종료는 리더 파티션이 활성화 된 상태에서 새로운 리더가 선출되기 때문에 그 시간까지 정상적으로 동작함.
- 예정된 종료는 종료 직전 자신이 가지고 있던 캐시를 모두 하드디스크에 저장함.
- 리더 파티션이 죽었다는 것은 데이터를 아무도 받지 못한다는 것을 의미한다. (프로듀서 / 컨슈머는 리더에만 접근 가능함)
카프카 클러스터는 리플리케이션을 이용해서 고가용성을 유지하고 있다. 그리고 이 고가용성을 유지해주는 녀석은 '컨트롤러'라는 녀석이다. 이 녀석은 브로커가 죽으면, 새로운 리더 파티션을 선출해서 카프카 클러스터와 주키퍼에게 알려주는 역할을 하고 있다. 이 녀석에 대한 자세한 동작을 살펴보면 아래와 같다.
예기치 못한 종료
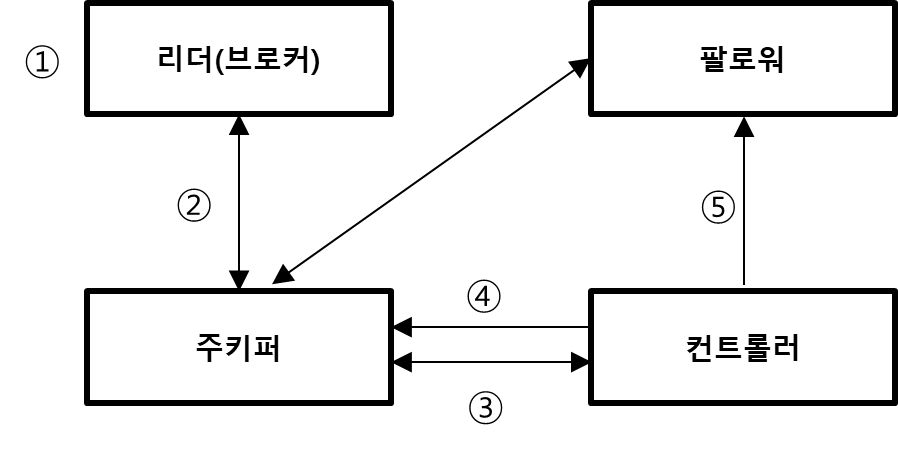
- 리더 파티션에 갑작스럽게 장애가 발생해서 종료되었다.
- 주키퍼는 리더 브로커와 연결이 끊어진 후, ISR에서 변화가 있음을 감지한다.
- 컨트롤러는 주키퍼 워치를 통해 ISR 변화가 있는 것을 확인하고, 해당 파티션의 ISR 중 하나를 새로운 리더로 선출한다.
- 컨트롤러는 새로운 리더를 선출한 정보를 주키퍼에 기록한다.
- 컨트롤러는 새로운 리더에 대한 정보를 모든 카프카 클러스터에게 알려준다.
리더 선출 과정은 컨트롤러에 의해서 진행된다. 그리고 예기치 못한 종료일 경우에 컨트롤러는 리더 선출을 파티션마다 하나씩 처리한다. 예를 들어 죽은 브로커가 가지고 있던 리더 파티션이 1000개라면, 1000개에 대한 리더 선출을 하나씩 처리해준다. 순차적으로 진행이 되기 때문에 카프카 클러스터가 정상이 되는데 오랜 시간이 걸릴 수도 있다. 그리고 프로듀서 / 컨슈머는 리더 파티션에게만 읽기 / 쓰기를 하기 때문에 이 다운 시간동안 해당 토픽 / 파티션은 정지되는 것을 의미한다.
통제된 종료
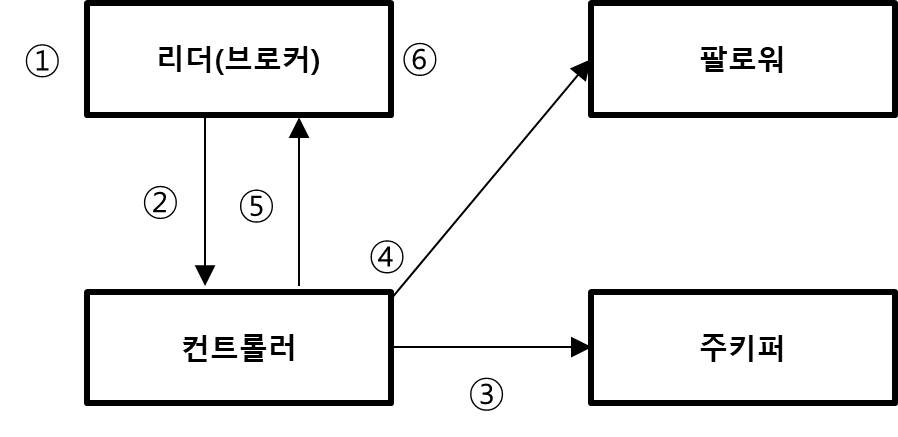
- 관리자가 브로커 종료 명령어를 실행하고, SIG_TERM 신호가 브로커에게 전달된다.
- 브로커는 이 사실을 컨트롤러에게 알린다.
- 컨트롤러는 리더 선출 작업을 진행하고, 해당 정보를 주키퍼에 기록한다.
- 컨트롤러는 새로운 리더 정보를 다른 브로커들에게 전송한다.
- 컨트롤러는 종료 요청을 보낸 브로커에게 정상 종료한다는 응답을 보낸다.
- 응답을 받은 브로커는 캐시에 있는 내용을 디스크에 저장하고 종료한다.
제어된 종료를 사용하면 카프카 내부 클러스터의 다운 타임을 최소화할 수 있다. 제어된 종료를 하게 되면, 리더가 아직은 활성화 된 상태에서 순차적으로 새로운 리더를 선출한다. 이런 때문에 제어된 종료라도 일시적인 다운 타임은 발생하지만, 예기치 못한 종료에 비하면 각 파티션의 다운 타임은 최소화할 수 있다. 제어된 종료를 사용하면 마지막에 캐시에 있는 내용을 디스크에 동기화한다. 따라서 브로커가 다시 재시작할 때, 로그 복구시간도 짧게 가져갈 수 있다.
예기치 못한 종료는 이미 해당 리더 파티션이 모두 종료가 되어있는 상태다. 따라서 어떠한 데이터도 받을 수 없는 상태에서 부랴부랴 리더를 선출해야한다. 컨트롤러는 순차적으로 리더를 선출하기 때문에 첫번째 파티션은 빠르게 동작할지라도, 마지막 파티션은 오랜 시간이 필요한다.
'Kafka eco-system > Kafka' 카테고리의 다른 글
| Kafka : 프로듀서의 전송 방법 (idempotence, at least once, at most once, exactly once) (0) | 2022.11.23 |
|---|---|
| Kafka Consumer에 대한 총 정리 및 코드 분석 (1) | 2022.09.29 |
| kafka-dump-log 명령어로 로그 파일의 메세지 내용 확인 (0) | 2022.09.05 |