Kafka Consumer에 대한 총 정리 및 코드 분석
- Kafka eco-system/Kafka
- 2022. 9. 29.
Kafka Consumer란 무엇인가?
카프카의 Consumer는 Broker로부터 메세지를 받아오는 객체다
Kafka Consumer의 구성
- 모든 Consumer는 고유한 그룹 ID를 가지는 Consumer Group에 소속되어야 한다.
- 같은 Consumer Group에 속한 파티션들끼리는 협력하면서 메세지를 읽어온다.
- 하나의 Consumer Group 내에서 한 Consumer는 여러 파티션을 읽어올 수 있다. 그렇지만 한 파티션을 여러 Consumer가 읽을 수는 없다.
- 한 파티션을 여러 Consumer가 읽을 경우, 어떤 메세지가 정상인지를 확인할 수 없기 때문이다.
- 따라서 Consumer 갯수 <= Partition으로 하되, Consumer 갯수 == Partition 갯수가 권장된다.
Kafka Consumer의 메세지 읽어오기
Consumer는 세 가지 동작으로 브로커에게서 메세지를 읽어온다
subscribe()
- Consumer는 subscribe()를 호출해서 브로커로부터 읽어오고자 하는 토픽을 설정한다. 브로커는 토픽에 대한 메타 정보를 전달한다.
- subscribe()의 인자는 Collection 타입이다. 한 Consumer는 여러 토픽을 subscribe() 할 수 있다는 의미다.
poll()
- 주기적으로 브로커의 Topic Partition에서 메세지를 가져온다.
- 가장 최초로 하는 poll()은 브로커에게서 메타 정보를 가져오고 Group Coordinator에 Join하는 작업을 한다. 실제로 메세지를 가져오는 것은 두번째 poll() 부터다.
- Batch(엄밀히 말하면 아니지만) 단위로 메세지를 가져온다.
Commit()
- Consumer는 commit()을 이용해서 브로커의 내부 토픽인 __consumer_offset에 이 토픽 + 파티션이 다음에 읽을 offset의 위치를 기록한다.
- Consumer가 어디까지 읽었는지를 기록하는 것이 아니라, 해당 토픽 + 파티션이 어떤 offset까지 읽혔는지를 기록해준다.
Kafka Consumer의 구성
- Fetcher
- ConsumerNetworkClient
- ConsumerCoordinator
- Heart Beat Thread
- SubscriptionState
카프카의 컨슈머는 크게 다음 구성 요소로 이루어져 있다. 각각의 역할을 살펴보면 다음과 같다.
Fetcher
public class Fetcher<K, V> implements Closeable {
...
private final ConsumerNetworkClient client;
private final int minBytes;
private final int maxBytes;
private final int maxWaitMs;
private final int fetchSize;
private final long retryBackoffMs;
private final long requestTimeoutMs;
private final int maxPollRecords;
private final ConsumerMetadata metadata;
private final SubscriptionState subscriptions;
private final ConcurrentLinkedQueue<CompletedFetch> completedFetches;
private final BufferSupplier decompressionBufferSupplier = BufferSupplier.create();
private final Deserializer<K> keyDeserializer;
private final Deserializer<V> valueDeserializer;
private final IsolationLevel isolationLevel;
...
}Consumer는 poll() 메서드를 이용해서 브로커로부터 메세지를 받아온다. poll() 메서드를 실행하면 Fetcher와 ConsumerNetworkClient 객체가 상호 협력하며 값을 불러온다. Fetcher는 내부적으로 ConsumerNetworkClient를 참조한다. Fetcher는 ConsumerNetworkClient의 Linked Que를 가지고 있는데, 이곳에서 데이터를 읽어서 Parsing 한 후, 본인의 completedFetches에 저장한다.
Fetch는 필요할 때 ConsumerNetworkClient를 호출하기 위해서 내부에 ConsumerNetworkClient를 참조하고 있다. 필요한 경우, 직접 ConsumerNetworkClient를 통해 Fetch API를 보내기도 한다.
ConsumerNetworkClient
public class ConsumerNetworkClient implements Closeable {
private static final int MAX_POLL_TIMEOUT_MS = 5000;
private final KafkaClient client;
private final Metadata metadata;
private final long retryBackoffMs;
private final int maxPollTimeoutMs;
private final int requestTimeoutMs;
private final AtomicBoolean wakeupDisabled = new AtomicBoolean();
private final ReentrantLock lock = new ReentrantLock(true);
private final ConcurrentLinkedQueue<RequestFutureCompletionHandler> pendingCompletion = new ConcurrentLinkedQueue<>();
private final ConcurrentLinkedQueue<Node> pendingDisconnects = new ConcurrentLinkedQueue<>();
...
}ConsumerNetworkClient는 백그라운드로 동작하며 Broker에게서 메세지를 받아와 Linked Que에 넣어주는 동작을 한다. 또한 클라이언트에서 데이터를 가져오기 때문에 Client 정보를 가지고 있기도 하고, 동시성 문제를 위해 Lock을 가지고 있다. 또한 읽어온 데이터를 넣기 위해 내부적으로 Que도 가지고 있다.
Heartbeat Thread
HeartBeat Thread는 백그라운드로 동작하며 끊임없이 Broker에게 Consumer의 상태를 알려준다. 만약 특정 파티션을 구독하고 있는 컨슈머가 죽게 되면 그 파티션의 데이터는 누구도 읽어가지 않게 된다. 따라서 이 상황을 방지하기 위해 Broker는 Consumer가 죽었다고 판단될 경우 리밸런싱을 한다. 이 리밸런싱에 도움을 주기 위해 Consumer의 Heart Beat Thread는 끊임없이 자신의 상태를 알려준다.
Heartbeat Thread는 Consumer가 첫번째 poll()을 수행했을 때 생성된다.
ConsumerCoordinator
public final class ConsumerCoordinator extends AbstractCoordinator {
private final GroupRebalanceConfig rebalanceConfig;
private final Logger log;
private final List<ConsumerPartitionAssignor> assignors;
private final ConsumerMetadata metadata;
private final ConsumerCoordinatorMetrics sensors;
private final SubscriptionState subscriptions;
private final OffsetCommitCallback defaultOffsetCommitCallback;
private final boolean autoCommitEnabled;
private final int autoCommitIntervalMs;
private final ConsumerInterceptors<?, ?> interceptors;
private final AtomicInteger pendingAsyncCommits;
private final ConcurrentLinkedQueue<OffsetCommitCompletion> completedOffsetCommits;
private boolean isLeader = false;
private Set<String> joinedSubscription;
private MetadataSnapshot metadataSnapshot;
private MetadataSnapshot assignmentSnapshot;
private Timer nextAutoCommitTimer;
private AtomicBoolean asyncCommitFenced;
private ConsumerGroupMetadata groupMetadata;
private final boolean throwOnFetchStableOffsetsUnsupported;
...
}ConsumderCoordinator는 Consumer Group의 상태를 관리하기 위해 사용된다. 카프카 Consumer는 Consumer Group으로 묶여서, 그룹으로 묶인 녀석들끼리 상호 협력하면서 동작한다. 이를 위해서 Consumer Coordinator가 사용된다.
ConsumerCoordinator는 Consumer Group의 상태를 관리하기 위한 상태값들을 가지고 있는데, 이 Consumer가 리더인지를 확인할 수도 있고, Consumer 실패 시 리밸런스 설정값들을 가지고 있다.
SubscriptionState
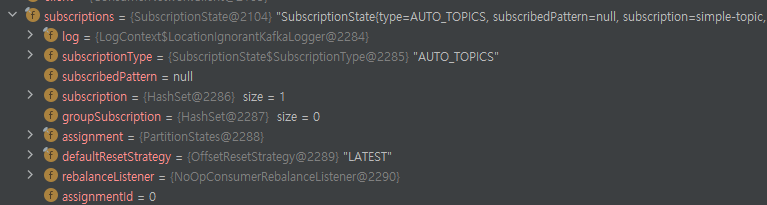
SubscriptionState는 현재 Consumer가 구독하고 있는 토픽의 상태를 전반적으로 알려주는 객체다.
kafkaConsumer의 poll() 메서드의 동작방식
kafkaConsumer.poll(1000)을 호출했을 때 동작을 살펴보면 다음과 같다.
- 첫번째 poll(1000) : 브로커에게 Find Coordinator API를 쏘고, Broker에서 Consumer Group ID로 클러스터링 하도록 한다. 이 때, Broker에는 GroupCoordinator 객체가 생기고 consumer는 join 요청을 한다.
- 두번째 poll(1000) : 가져올 데이터가 있는 경우, 바로 데이터를 읽어서 반환한다.
- 세번째 poll(1000) : 가져올 데이터가 없는 경우, 1000ms만큼 loop를 돌면서 Fetcher에 데이터가 적재되는 것을 계속 확인한다. 또한, ConsumerNetworkClient는 끊임없이 Broker에게 메세지를 가져오도록 요청한다. 결국 반환할 데이터가 없으면 세번째 poll() 완료
- 네번째 poll(1000) : 가져갈 데이터가 없어서 루프를 돌면서 감시한다. 브로커에서 메세지가 들어오면, ConusmerNetworkClient는 Linked que에 데이터를 넣어주고, Fetcher는 이 값을 Parsing해서 Consumer에게 반환해준다.
KafkaConsumer의 HeartBeat Thread
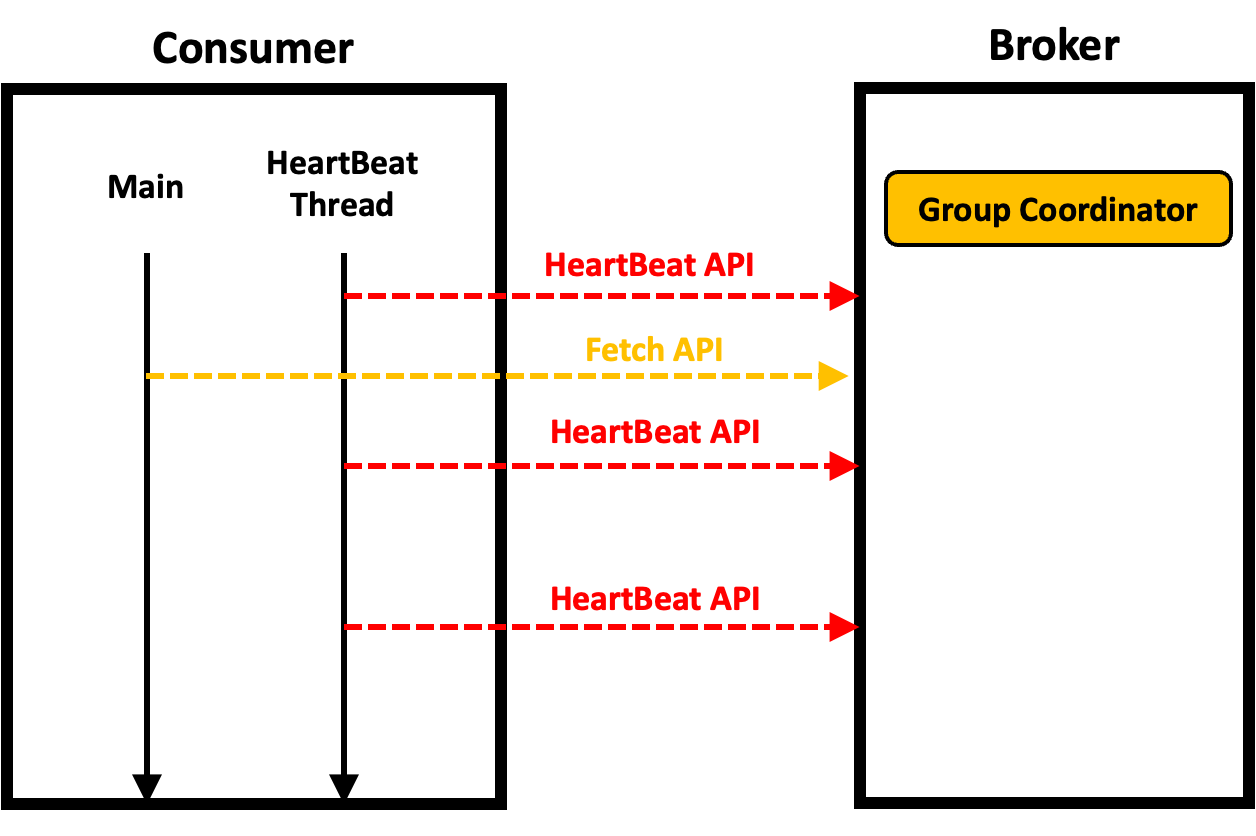
- KafkaConsumer는 자식 쓰레드로 HeartBeat Thread를 가진다.
- HeartBeat Thread는 Main 쓰레드와 상관없이 주기적으로 Broker의 GroupCordinator 객체에 HeartBeat API를 보낸다.
- 만약 GroupCoordinator가 일정 시간 이상이 되도록 Heartbeat Thread의 요청을 받지 못하면, 정상적인 상태가 아니라 판단하고 Consumer를 Consumer Group에서 제외한다.
- HeartBeat Thread는 kafkaConsumer의 첫번째 poll()에서 생성된다.
- HeartBeat Thread는 다음과 같은 경우에 도움이 될 수 있다.
- Consumer 프로세스는 떠있긴 하지만 먹통인 경우가 있다. 이 때, Consumer는 해당 파티션을 점유하고 있기 때문에 이 파티션의 메세지는 누구도 가져갈 수 없는 상태다.
- 이 때, Heartbeat 쓰레드를 통해서 건강하지 않다는 것을 알려주면 해당 Consumer는 리밸런싱 대상이 된다.
| 파라미터명 | 기본값(ms) | 설명 |
| heartbeat.interval.ms | 3000 | Heartbeat Thread가 Heatrbeat API를 보내는 간격. session.timeout.ms보다 낮게 설정되어야 함. |
| session.timeout.ms | 45000 | 브로커가 Heartbeat을 기다리는 최대 시간. 브로커는 이 시간동안 HeartBeat를 받지 못하면 해당 Consumer를 그룹에서 제외하도록 리밸런싱 명령 날림. |
| max.poll.interval.ms | 300000 | 이전 poll() 호출 후, 다음 poll() 호출까지 Broker가 기다리는 시간. 이 시간동안 poll() 호출이 이루어지지 않으면 해당 Consumer는 리밸런싱 대상이 되어, 리밸런싱 됨. |
max.poll.interval.ms는 main 쓰레드와 관련이 있다. 만약 main 쓰레드에서 데이터를 처리하는 작업이 오래 걸린다면, max.poll.interval.ms 시간이 지나게 되면서 리밸런싱 대상이 될 수 있다. 예를 들면 대량의 데이터를 RDBMS에 Insert 하는 작업이 있을 수 있다. 이런 것들을 충분히 감안해서 사용해야한다.
Consumer Fetcher의 동작 방식
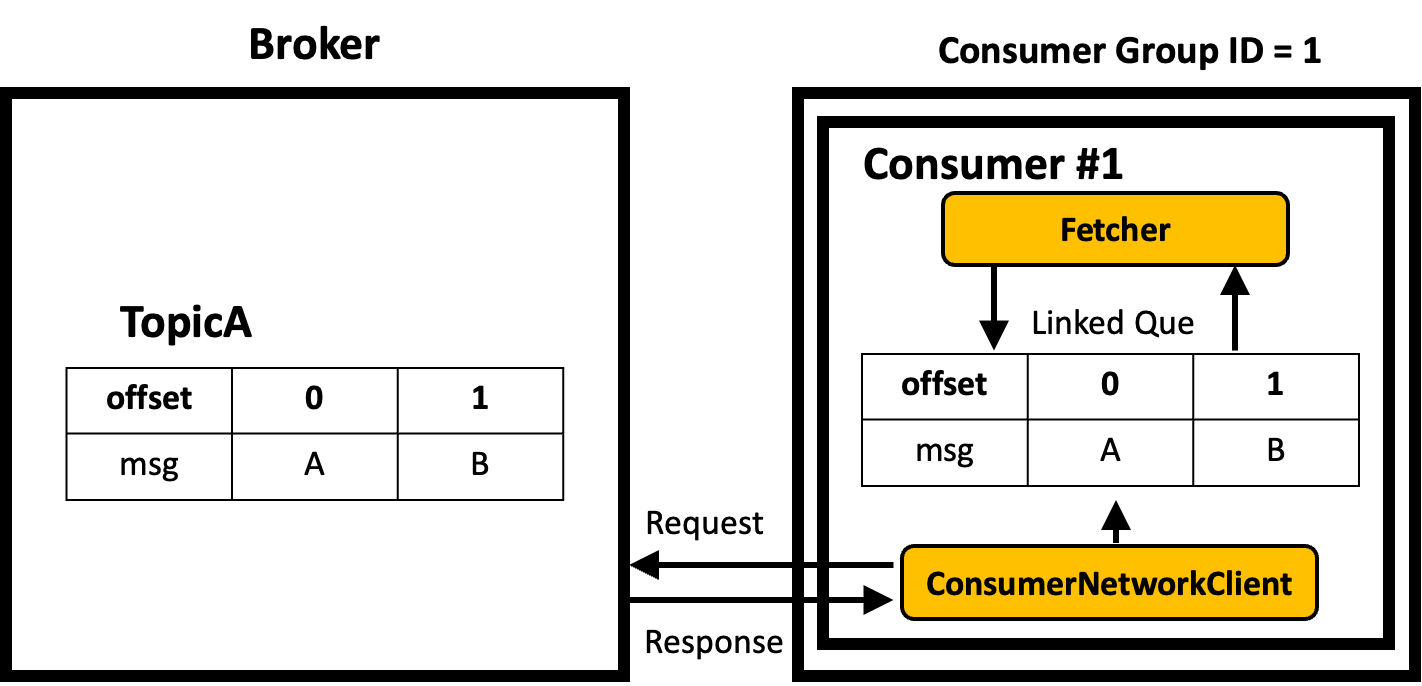
- Consumer의 ConsumerNetworkClient 객체는 비동기로 Broker에 메세지를 요청하고 응답을 받는다. 그리고 자신이 가지고 있는 LinkedQue에 데이터를 넣어준다. 이 때, 응답 받은 Byte Buffer 형태로 넣어줌.
- Fetcher는 LinkedQue에서 데이터를 읽어서 Byte Buffer를 Parsing 및 역직렬화를 한 후 토픽 파티션별로 레코드를 만든 후에 그것을 자신이 가지고 있는 LinkedQue에 넣어준다.
Consumer Fetcher는 몇몇 Parameter를 받고, 그 Parameter 값으로 동작한다.
| 설정 | 설명 |
| fetch.min.bytes | Fetcher가 레코드를 읽어들이는 최소 bytes. 브로커는 fetch.min.bytes 이상의 새로운 메세지가 쌓일 때까지는 전송하지 않음. |
| fetch.max.wait.ms | 브로커에 fetch.min.bytes 이상의 메세지가 쌓일 때까지 최대 대기 시간. 만약 이 시간이 넘어도 fetch.min.bytes를 만족시키지 못하면, 바로 데이터를 가져옴. |
| fetch.max.bytes | Fetcher가 한번에 가져올 수 있는 최대 데이터 bytes. default는 50MB. |
| max.partition.fetch.bytes | Fetcher가 파티션 별로 한번에 가져올 수 있는 최대 bytes. 예시 ) 파티션이 100개이고, max.parition.fetch.bytes가 1MB인 경우 100MB를 가져온다. 그런데 이 때 fetch.max.bytes가 50MB이기 때문에 이것에 대한 제약을 받음. |
| max.poll.records | Fetcher가 Linked Que에서 한번에 가져올 수 있는 레코드 수. 기본은 500 |
이 때 주의해야 할 점은 poll wait time과 fetch.max.wait.ms의 차이점은 존재한다는 것이다. poll wait time은 fetcher의 linked que에 레코드가 없을 때 이 시간만큼 계속 시도 한다는 의미다. 반면 fetch.max.wait.ms는 브로커에 일정 수준의 새로운 데이터가 쌓일 때까지 기다린다는 의미다.
Consumer Fetcher 설정 파라미터의 예시
- kafkaConsumer.poll(1000) 명령어 수행
- Fetcher 파라메터 설정
- fetch.min.bytes = 16384
- fetch.max.wait.ms = 500
- fetch.max.bytes = 52428800
- max.partition.fetch.bytes = 1024168
- max.poll.records = 500
그렇다면 다음과 같이 동작한다.
- 먼저 가져와야 할 레코드가 LinkedQue에 없다면 poll(1000)에서 1000ms만큼 대기 후 return 한다.
- 가져와야 할 데이터가 많은 경우 fetch.max.bytes로 배치 크기가 설정된다. 가져와야 할 데이터가 적은 경우 fetch.min.bytes 값이 만족할 때까지 기다린다. 그렇지만 끝까지 기다리지는 않고 fetch.max.wait.ms가 지나면 fetch.min.bytes를 만족하지 못했더라도 브로커에게서 메세지를 가져온다.
- 최신의 메세지를 가져온다면 주로 fetch.min.bytes 만큼의 데이터를 한번에 가져오고, 예전의 메세지를 가져온다면 fetch.max.bytes만큼의 메세지를 가져온다.
- 토픽에 파티션이 많아도 가져오는 데이터량은 fetch.max.bytes로 제한된다.
- Fetcher가 Linked Que에서 가져오는 레코드의 갯수는 max.poll.records로 제한됨.
Consumer의 __consumer_offsets
- 브로커에는 __consumer_offsets이라는 파티션이 저장되어있다.
- __consumer_offsets은 브로커 내부에서 사용하는 내부 토픽이다.
- 이 값은 Consumer를 리밸런싱할 때 주로 사용된다.
- __consumer_offsets에는 Consuemer Group / Topic / Partition 별로 다음에 전달해야 할 offset이 저장되어있다.
- Broker는 __consumer_offsets을 확인하고, __consumer_offsets에 기록된 offset부터 메세지를 Consumer에게 전달해준다.
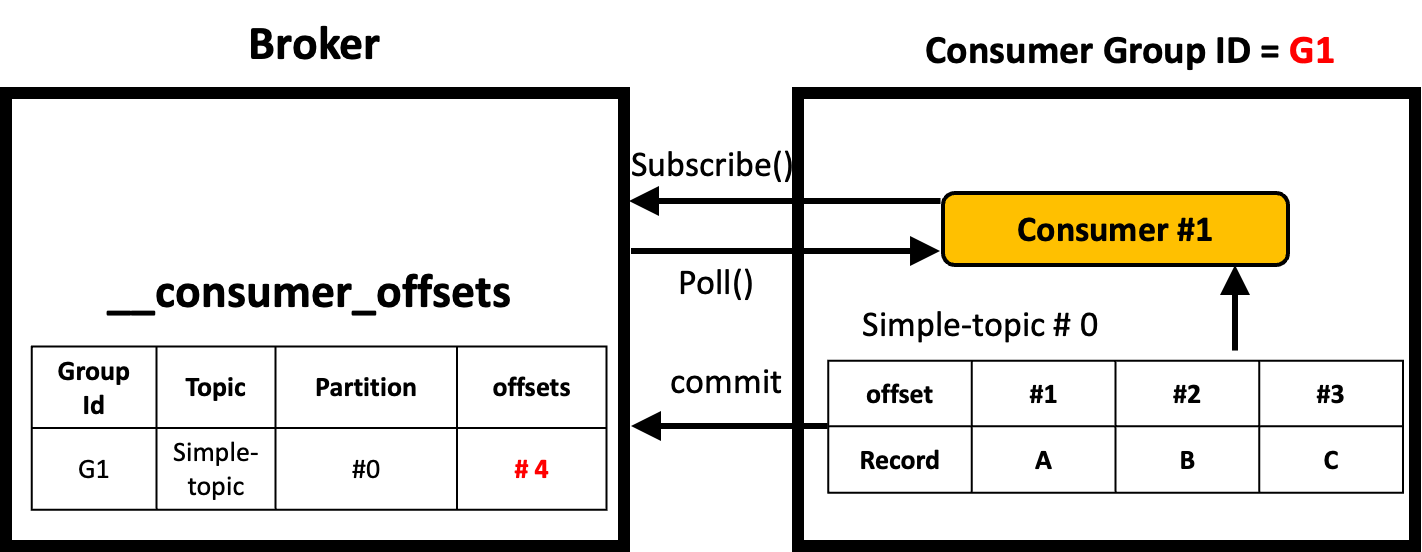
- Consumer는 특정 메세지를 모두 읽고 나면 어디까지 읽었는지 offset을 commit API를 이용해서 Broker에게 보낸다.
- Broker는 받은 값을 __consumer_offsets에 컨슈머 그룹 / 토픽 / 파티션 단위로 저장해둔다.
- 어떤 컨슈머가 받았는지를 저장하지 않는 이유는 컨슈머는 언제든지 죽을 수 있고, 대체될 수 있고, 리밸런싱 될 수 있기 때문이다.

- 위는 __consumer_offsets 파티션의 로그 파일을 일부만 확인한 것이다. 앞에서부터 Consumer Group / Topic / Partition이 되어있고, 뒷쪽에는 읽은 offset이 기록된 것을 볼 수 있다.
Consumer의 auto.offset.reset
- auto.offset.reset는 Consumer의 파라메터다.
- __consumer_offsets에 해당 Consumer group의 Topic Partition을 offset 정보가 없는 경우, 어디서부터 값을 가져올지를 결정한다.
- earliest : 처음부터 읽는다.
- latest : 마지막부터 읽는다.
- __consumer_offsets에 정보가 있는 경우, auto.offset.reset은 무시된다.
KafkaConsumer의 Commit
- Consumer는 메세지를 읽어온 후, 어디까지 읽었는지를 브로커에게 Commit 한다. Commit되면 컨슈머 그룹 + 토픽 + 파티션에 해당되는 __consumer_offsets에 그 값이 기록되게 된다.
- KafkaConsumer는 Consumer Group에 조인할 때만 __consumer_offsets 참고해서 값을 읽어온다. 이후에는 Consumer는 요청해야 할 Offset 상태값을 가지고 있고, 이 값을 바탕으로 Fetch API를 요청해서 받아온다.
아무튼 Consumer는 자신이 메세지를 어디까지 읽고 처리했는지에 대한 정보를 Commit을 통해 Broker에게 알려준다!
Commit의 방식
- Auto Commit : enable.auto.commit=true
- Manual Commit
- 동기 : enable.auto.commit=false + consumer.commitSync()
- 비동기 : enable.auto.commit=false + consumer.commitAsync()
Commit에는 위와 같이 두 가지 방식이 존재한다. 각 방식에 따라 설정값이라든지 실행하는 방법이 다르다.
Auto Commit
props.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, 'true');- AutoCommit은 poll() 할 때와, consumer.close() 할 때 호출됨.
- auto.enable.commit=true인 경우, Consumer는 Auto Commit을 함.
- poll()을 호출할 때, auto.commit.interval.ms에 정해진 주기마다 Consumer가 자동으로 Commit을 수행함.
- 이전 poll()에서 마지막으로 가져온 메세지의 offsets을 commit 하는 것을 의미함.
- Commit은 Batch 단위로 처리된다.
- Consumer의 장애 / 재기동 및 리밸런싱 후 브로커에서 이미 읽어온 메세지를 다시 읽어와서 중복 처리가 될 수 있음.
- 34~40번까지 읽어온 후, 다음 poll()에서 40번을 Commit 하려는 순간 Consumer 장애가 발생.
- 이 때, __consumer_offsets은 Commit 받지 않았기 때문에 여전히 34를 가리키기 때문에 다시 34~40을 읽음.
Manual Commit
consumer.commitSync();
consumer.commitAsync((offsets, exception) -> {
System.out.println("this is callback");
});manual Commit에는 동기 방식 / 비동기 방식이 존재한다. 각각 commitSync() / commitAsync()로 실행할 수 있음.
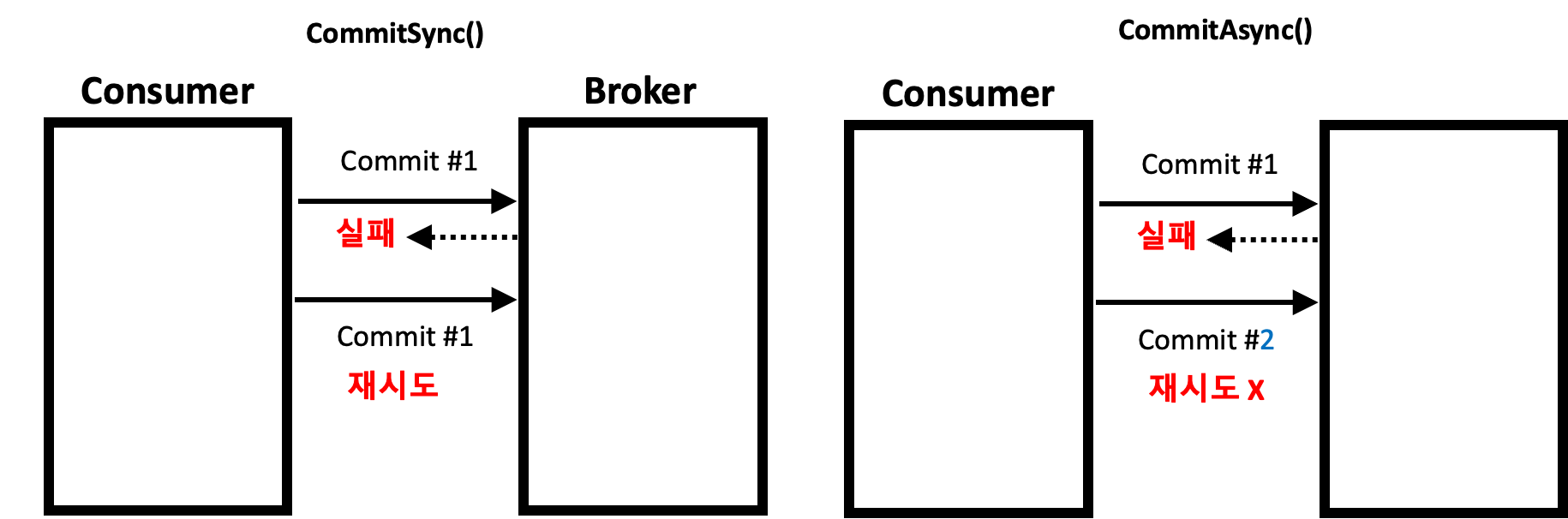
동기방식 : CommitSync()
- CommitSync()를 할 경우, 해당 라인에서 Main Thread가 Blocking 됨.
- Commit에 실패하면, 성공할 때까지 Commit을 요청함. 더 이상 Commit을 시도할 수 없는 경우 CommitFailedException이 발생함.
- 이 때, NetworkClient를 통해서 메세지는 Batch에 적재되지만, commitSync()에 Block 되어서 다음 메세지를 가져오지 못한다.
비동기방식 : CommitAsync()
- 메세지 배치를 poll()을 통해 읽어오고 해당 메세지의 마지막 offset을 브로커에 commit 요청함.
- 브로커에 Commit 적용이 성공적으로 되었음을 기다리지 않고 (Non Blocking) 계속 다음 메세지를 읽어옴.
- 브로커에 Commit 적용이 실패해도 다시 Commit을 시도하지 않는다.
- 200까지 읽고 201을 Commit 했으나 비동기로 실패함.
- 이 때 240까지 읽고 241을 Commit하면 __consumer_offsets는 241이 됨. 즉, 이전에 읽어온 값이 Commit에 실패했어도 문제 없는 상황이 된다.
- 에러가 발생하면 CallBack() 함수를 통해서 데이터를 받아와서 로그를 찍어줄 수 있다.
- 동기 방식 대비 더 빠른 수행시간
KafkaConsumer의 읽기 Offset Commit / 중복 읽기 및 누락 상황 이해
카프카는 분산 처리 시스템이고 Consumer / Producer / Broker가 Loose하게 연결되어있다. 왜냐하면 Producer -> Broker -> Consumer로 메세지가 전달되는 구조가 하나의 트랜잭션처럼 작용하지 않기 때문이다. 따라서 장애가 발생하면 중복 읽기 및 누락 상황이 발생할 수 있다는 것을 인지해야한다.
이 상황을 인지하고, 장애가 발생하지 않도록 설계하고 구조를 최대한 심플하게 가져가서 데이터 정합성을 맞추는 것이 중요하다.
중복 읽기 상황
- Consumer #1이 파티션 #0의 4~10을 읽고 데이터를 처리했다. 이 때 처리한 데이터를 RDBMS에 넣었다.
- Consumer #1이 Commit을 하려는 순간 장애가 발생해서 offset 11을 Broker에 전송하지 못했다.
- Consumer #1은 죽고 리밸런싱이 일어난다.
- 새롭게 파티션을 배정받은 Consumer #2는 __consumer_offsets를 참고해서 첫 데이터를 fetch한다. 이 때, __consumer_offsets은 4가 되어있기 때문에 4~10을 다시 읽어온다.
- 여기서 중복이 발생함.
읽기 누락 상황
- Consumer #1이 파티션 #0의 4~10을 읽고 Broker에 Commit을 먼저했다. __consumer_offsets은 11이 됨.
- 이후 Fetch한 데이터를 RDBMS에 넣으려고 하는 순간 Consumer #1에게는 장애가 발생했다.
- Consumer #1은 죽고 리밸런싱이 일어난다. Consumer #2가 파티션 #0을 배정받았다.
- Consumer #2는 __consumer_offsets를 참고해서 첫 데이터를 fetch한다. 이 때 11이기 때문에 11번 offset부터 읽어온다.
- 여기서 데이터 4~10의 데이터 누락이 발생함.
Kafka Consumer의 리밸런싱
Consumer는 Consumer Group 내에서 협력해서 동작한다. 그런데 새로운 Consumer가 Consumer Group에 생성되거나 없어지게 되면 되면 기존 Consumer가 하던 일을 나눠서 해야한다. 따라서 이렇게 일을 분배하는 과정을 해야하는데, 이것을 Kafka Consumer의 리밸런싱이라고 한다.
- 파티션이 추가되었을 때
- Consumer가 생기거나 없어졌을 때
리밸런싱은 다음과 같은 경우에 일어난다. 그런데 리밸런싱이 발생했을 때의 한 가지 문제점이 생긴다. Consumer는 리밸런싱을 하기 위해서 메세지 Consume을 멈춘다는 것이다. 따라서 이 기간동안 메세지의 Lag가 발생한다. 따라서 리밸런싱은 최소화 하는 것이 좋다.
- Group Coordinator는 토픽이 추가되거나, Consumer Group의 Consumer에 변동이 생겼을 때 리더 Consumer에게 리밸런싱 명령을 내린다.
- 리더 Consumer는 파티션 분배 전략에 따라 파티션을 분배하고, 분배 결과를 Group Coordinator에게 알려준다.
리밸런싱 과정은 Broker의 Group Coordinator와 Consumer Group의 Leader Consumer의 상호 작용의 결과다. 이 부분은 위와 같이 동작한다.
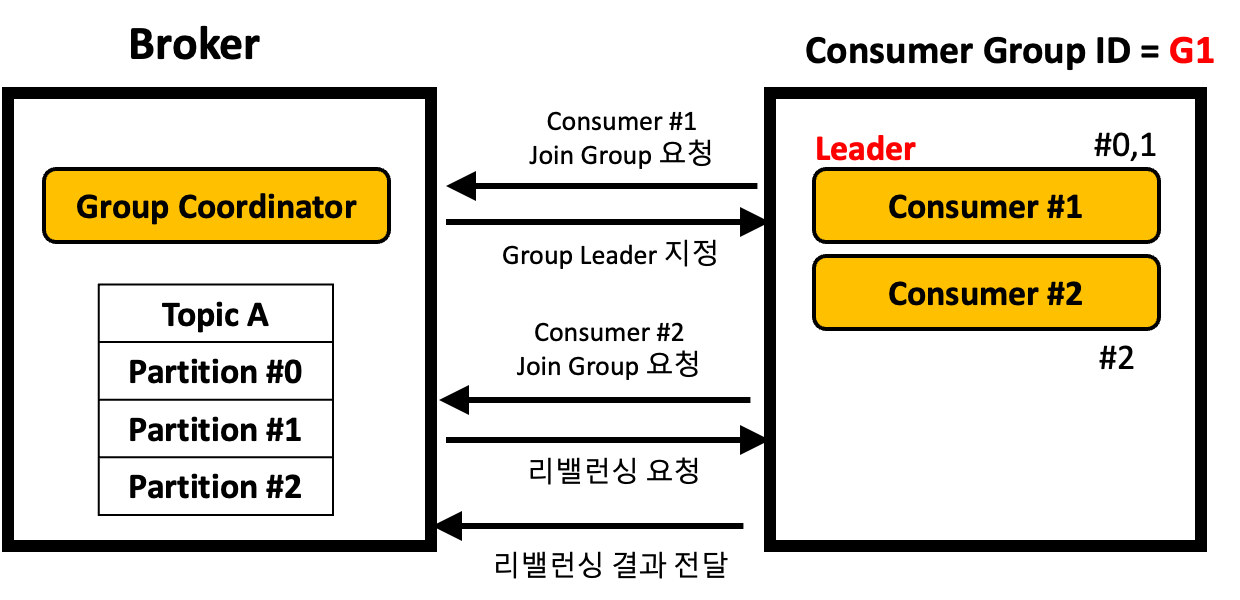
상세한 동작은 다음과 같이 일어난다.
- Consumer Group 내에 새로운 Consumer가 브로커에게 최초 접속 요청할 때, 브로커에는 Group Coordinator 객체가 생성됨.
- Group Coordinator 객체가 생성되면, Consumer는 Join Group을 요청한다.
- 가장 처음에 Join Group을 요청한 Consumer가 Leader Consumer가 된다.
- Group Coordinator는 Leader Consumer에게 구독하는 토픽의 파티션 정보를 전달한다.
- Leader Consumer는 Consumer Group 내의 Consumer를 확인하고, 파티션 할당 전략에 따라 파티션을 할당한다.
- Leader Consumer 는 파티션 할당 결과를 Group Coordinator에게 전달한다.
- Group Coordinator에게 정보 전달이 성공하면, Consumer Group의 Consumer는 할당된 파티션에서 메세지를 읽어온다.
Consumer Group Status
- empty : Consumer Group에 어떠한 Consumer도 없는 경우
- rebalance : 리밸런싱을 하고 있는 상태
- stable : 리밸런스가 완료되어 메세지가 Consume 되고 있는 상태
Consumer Group의 group Coordinator는 리밸런싱을 관리하기 위해서 세 가지 상태값을 가진다.
KafkaConsumer의 Static Group Membership
Consumer는 Consumer에 변동이 있거나, 토픽이 새로 생기는 경우 Leader Consumer에 의해 리밸런싱이 일어난다. 그런데 이 리밸런싱을 하는 과정에서는 메세지 Consume이 되지 않기 때문에 리밸런싱을 너무 자주하는 것은 좋지 않다. 리밸런싱을 적게 하는 방법 중 하나로 Static Group MemberShip을 사용할 수도 있다.
개념
- Consumer Group내의 Consumer들에게 고정된 Id를 부여한다.
- Consumer가 shotdown 된 후, session.timeout.ms(Max Wait Heartbeat) 이내에 재기동한다면 파티션은 리밸런싱 되지 않고 기존 파티션을 그대로 사용한다.
- Consumer가 session.timeout.ms 이내에 재기동하지 못하면 리밸런싱이 발생한다.
사용방법
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "group-01-static");
props.setProperty(ConsumerConfig.GROUP_INSTANCE_ID_CONFIG, "1");
props.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");Consumer를 생성할 때 설정값을 다음과 같이 전달해줄 수 있다. 이 때, group_instance_id_config에 값을 주면 이 Consumer는 Consumer Group에서 고정된 Consumer ID를 가지고 동작한다.

Consumer Group을 살펴보면 Client-ID에서 Static 그룹을 확인할 수 있다. 뒷쪽에 1,2,3과 같은 값이 존재하는데 이 값이 Static Membership에 의해 할당된 이름이다.
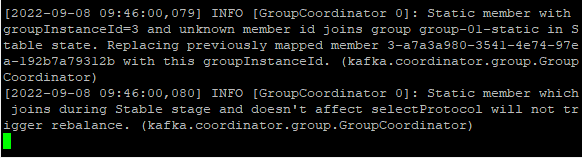
session.timeout.ms 이내에 재기동을 하게 된다면 리밸런싱은 일어나지 않는다. Join이 완료되면 다음 메세지가 보여지는데, Stable Stage 기간동안 Static Member가 Join 했기때문에 리밸런싱을 하지 않는다고 한다.
Consumer Rebalance의 Eager / Cooperative 모드
- Eager(default) : 전체 Stop -> 리밸런스 -> 수행
- Cooperative : (일부 stop -> 일부 리밸런스) 반복
Consumer가 리밸런스 될 때는 두 가지 모드 중 하나를 선택해서 리밸런스를 하게 된다. 기본적으로 Eager 방식이 default로 설정되어있지만, 리밸런스 기간이 길어진다면 Cooperative 사용을 고려해볼만하다.
Eager 모드

- 리밸런싱이 일어나면 모든 파티션의 분배를 취소하고, 다시 파티션을 재할당한다. 따라서 리밸런싱은 딱 한번만 일어난다.
- 모든 파티션 분배가 취소 되기 때문에 메세지 Lag가 발생함.
- 파티션 분배전략은 다음이 존재한다.
- Range(Default) / RoundRobin / Sticky
Cooperative 모드

- 리밸런스 수행 시, 리밸런스 대상이 되는 Consumer들만 선택해서 점진적으로 리밸런싱을 수행함.
- 점진적으로 리밸런싱 한다는 것은 작은 리밸런싱을 여러 번 반복한다는 것이다.
- 이 때, 리밸런스 대상이 아닌 기존 Consumer는 메세지를 계속 Consume 한다.
Consumer의 파티션 분배 전략
| 리밸런스 모드 | 파티션 분배 전략 | 내용 |
| Eager | Range(default) | 서로 다른 2개 이상의 토픽을 Consume 하는 경우, 토픽별로 동일한 파티션을 특정 Consumer에게 할당함. 해당 Consumer가 여러 토픽의 동일 키 값으로 데이터 처리를 용이하게 할 수 있음. |
| Eager | Round Robin | 파티션 별로 Consumer들이 균등하게 부하를 분배함. 여러 토픽들의 파티션들을 Consumer들에게 순차적으로 RR로 분배함 |
| Eager | Sticky | 최초에 할당된 파티션과 Consumer의 매핑을 리밸런스가 수행되어도 가급적 유지함. 어떻게 맵핑되었는지 기억한 후 리밸런스 시, 모든 파티션이 해제되었다가 다시 맵핑됨. |
| Cooperative | Cooperative Sticky | 최초에 할당된 파티션과 Consumer 맵핑을 리밸런스 되어도 가급적 유지함. 리밸런스 시, 일부 파티션만 점진적으로 재 맵핑됨. |
Consumer는 리밸런스 될 때 파티션이 다시 재분배 된다. 이 때 파티션 분배는 파티션 분배 전략을 바탕으로 이루어진다. Eager 모드에서 진행되는 리밸런스는 기본적으로 파티션의 할당을 전부 끊고 다시 맵핑하는 형태다. Cooperative 모드에서 진행되는 리밸런스는 기존 파티션 분배는 그대로 유지하며 필요한 파티션만 점진적으로 리밸런싱 하는 역할을 한다.
Range와 RoundRobin 분배 전략의 비교
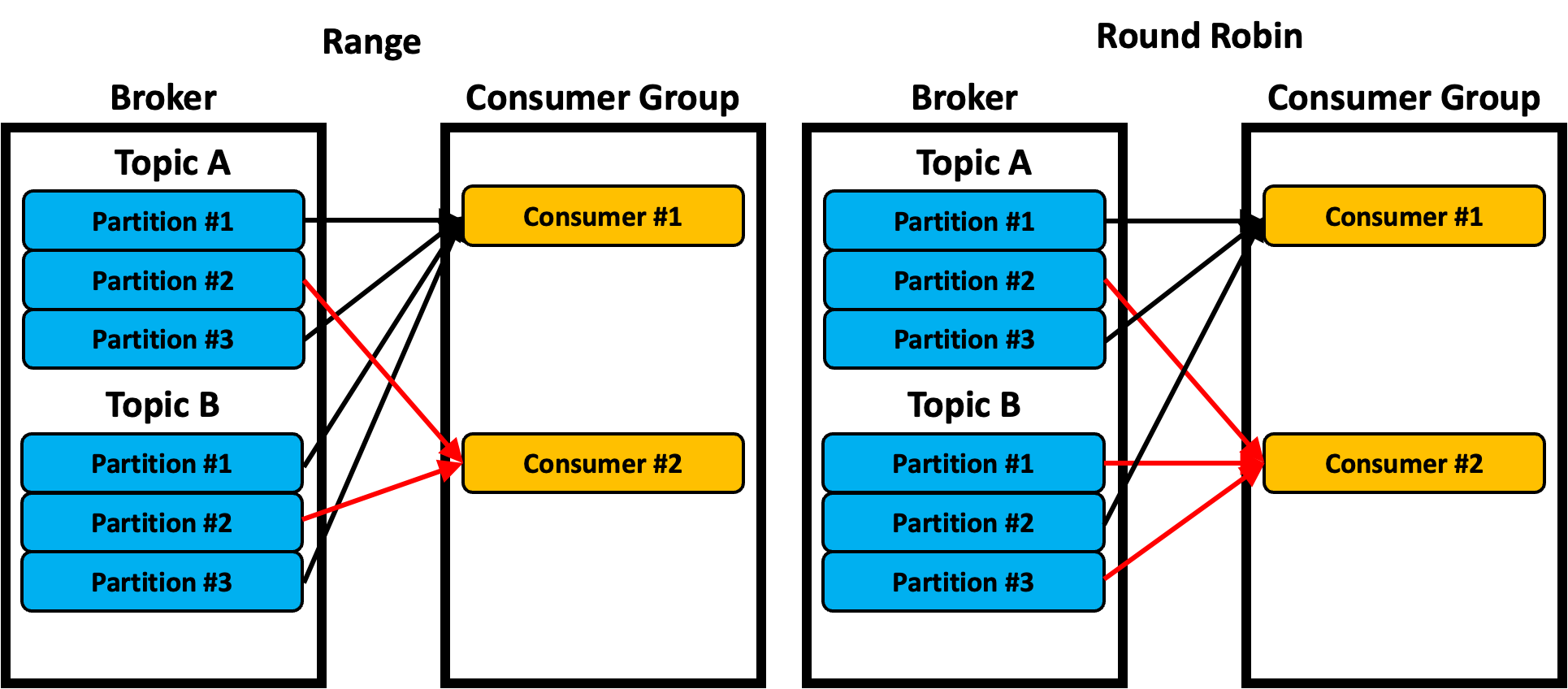
- Range는 한 Consumer가 여러 토픽을 구독하고 있을 경우, 각 토픽의 파티션 번호가 같은 Consumer에게 전달되는 형태다.
- 예를 들어 Consumer#1은 TopicA,B의 Partition #1,3으로부터 데이터를 받는다.
- Producer는 Key 값에 따라 Hash 알고리즘으로 파티셔닝 해주기 때문에 같은 Key 값을 가지는 메시지끼리 데이터 처리하기가 용이하다.
- Round Robin은 Consumer에게 Topic의 Partition을 공평하게 뿌려주는 역할을 한다.
- 따라서 서로 다른 토픽을 구독하더라도, 각 토픽별로 다른 파티션의 데이터를 받을 수 있다.
두 파티션 분배전략은 리밸런싱이 일어나고 나면 상황에 따라서 기존에 Consumer가 구독하던 토픽 + 파티션을 그대로 유지 못할 수도 있다.
Sticky 전략
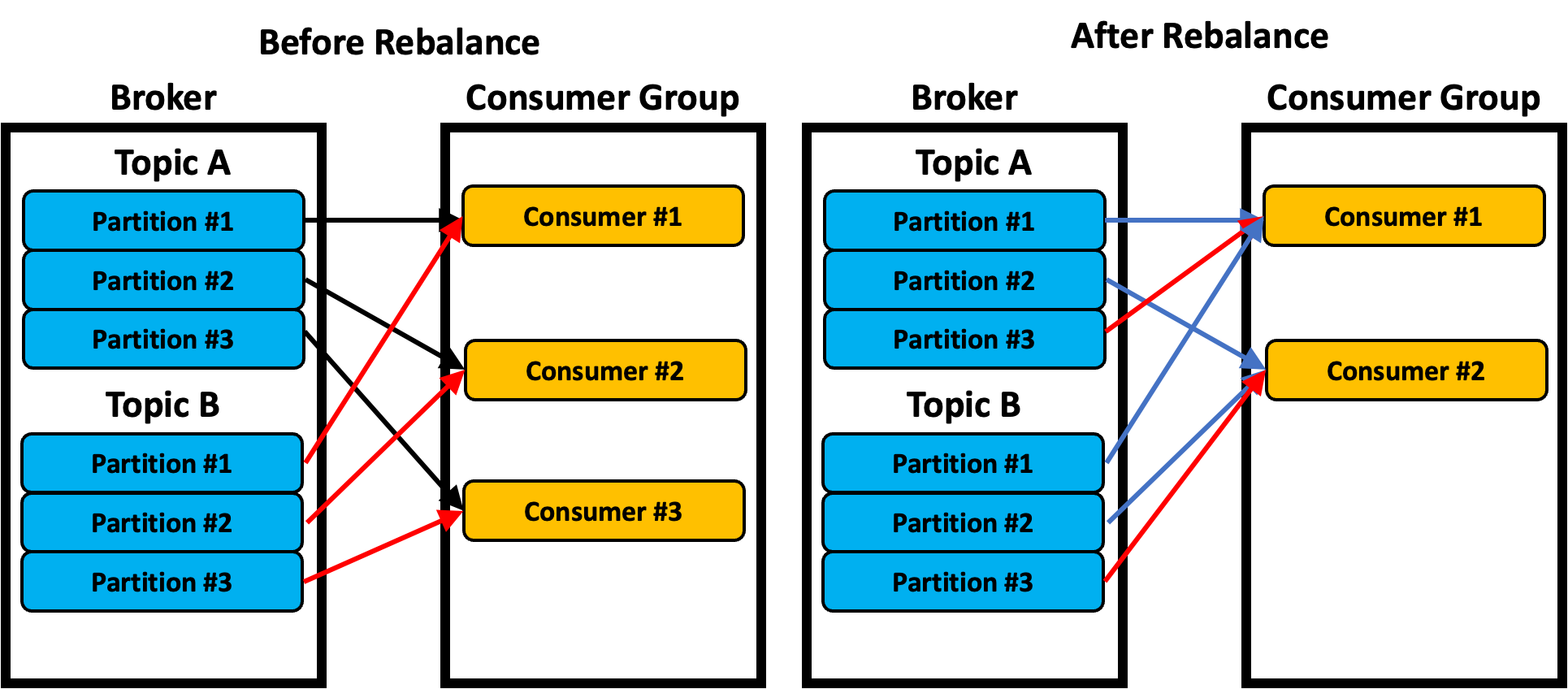
- Range / RoundRobin 분배전략은 리밸런싱이 일어나고 나면 상황에 따라서 기존에 Consumer가 구독하던 토픽 + 파티션을 그대로 유지 못할 수도 있다. 이왕이면 파티션을 유지하면 좋을 것이다. 이것을 해주는 것이 Sticky 전략이다.
- Sticky 전략의 최초 할당은 Round Robin과 유사하게 분배된다.
- Sticky 전략은 모든 파티션 맵핑을 일시적으로 취소하지만 어떻게 분배되었는지를 기억해둔다. 그리고 가급적 기억해둔 상태를 유지하면서 나머지 파티션을 분배한다. (물론 100% 일치하지는 않음.)
- 위의 이미지에서 파란색 선은 리밸런스 이전에 할당된 파티션이 그대로 유지되는 것을 보여준다.
Cooperative Sticky 전략
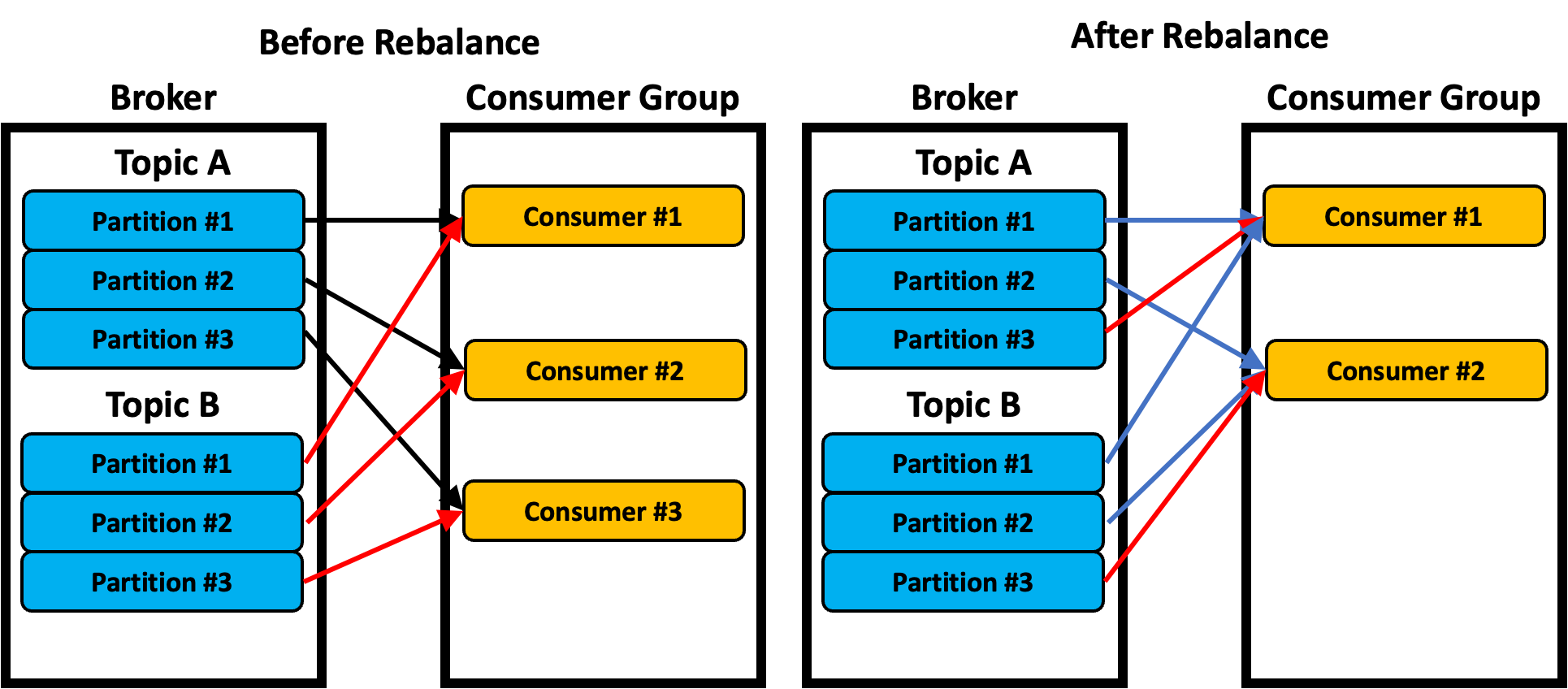
- 리밸런스가 Cooperative인 경우, Cooperative Sticky 전략으로 파티션이 분배된다.
- 최초 파티션 분배는 Round Robin과 유사하게 동작한다. 리밸런싱 될 때는 기존의 분배는 유지하고, 필요한 파티션만 리밸런싱된다. (점진적으로). 아무튼 최대한 기존의 파티션 분배를 유지하는 방식으로 진행된다.
- 그림 참고
- 위의 그림에서 오른쪽을 참고하면 파란색은 리밸런스 과정에서 파티션 배정이 그대로 유지되었다.
- 빨간색은 리밸런스 과정에서 파티션 분배가 취소된 후, 이것만 리밸런스를 시작했다.
- Sticky는 결국 비슷하게 동작하는데 모든 파티션 분배가 취소되고 재배정 되는지, 일부만 재배정 되는지에 따라 Eager / Cooperative가 바뀐다.
Consumer의 assign() / seek()
특정 Partition의 데이터를 Consume 하는 과정에서 누락이 발생했고, 이것을 알아챈 경우 유지 보수 차원에서 다음과 같은 일을 하고 싶은 경우가 있다.
- 특정 Consumer를 만들어 파티션에서만 데이터를 읽어온다.
- 특정 offset부터 데이터를 읽어온다.
Kafka Consumer는 위 기능을 제공한다. 단, 유지보수용으로만 사용하는 것이 좋다고 한다.
assign
TopicPartition topicPartition = new TopicPartition(topicName, 0);
consumer.assign(List.of(topicPartition));- 위의 코드를 작성하면, 해당 Consumer에게는 topicPartition의 값만 고정되서 메세지를 읽어온다.
- 일반적으로 특정 Key를 가진 메세지만 처리하는 Consumer를 만들고 싶을 때 사용한다.
- Producer는 파티션을 분배할 때, Key 값이 존재하면 Hash 알고리즘에 의해 분배한다. 따라서 동일한 Key는 항상 같은 파티션으로 온다.

실제 동작은 다음과 같은 형태로 한다.
assign + seek
TopicPartition topicPartition = new TopicPartition(topicName, 0);
consumer.assign(List.of(topicPartition));
consumer.seek(topicPartition, 100L);- assign() + seek()를 하면 특정 토픽 파티션의 특정 offset부터 읽어올 수 있다.
- 이런 경우는 주로 유지보수를 할 때 많이 사용한다. 예를 들어 Consumer는 특정 값을 읽어서 Commit을 해서 __consumer_offset에 반영이 되어있는데, DB에서는 이 값을 못 받은 경우가 있을 수 있음.
- assign() + seek()를 하더라도, 읽어온 메세지에 대해 Commit을 하면 __consumer_offsets에 반영된다. 따라서 이런 경우는 일반적으로 원하지 않는 경우이기 때문에 두 가지 방법으로 처리할 수 있다.
- ConsumerGroup으로 새로 만든다. 이 때는 Commit을 해도 상관없음.
- 기존 ConsumerGroup을 사용하고, Commit을 절대로 하지 않는다.
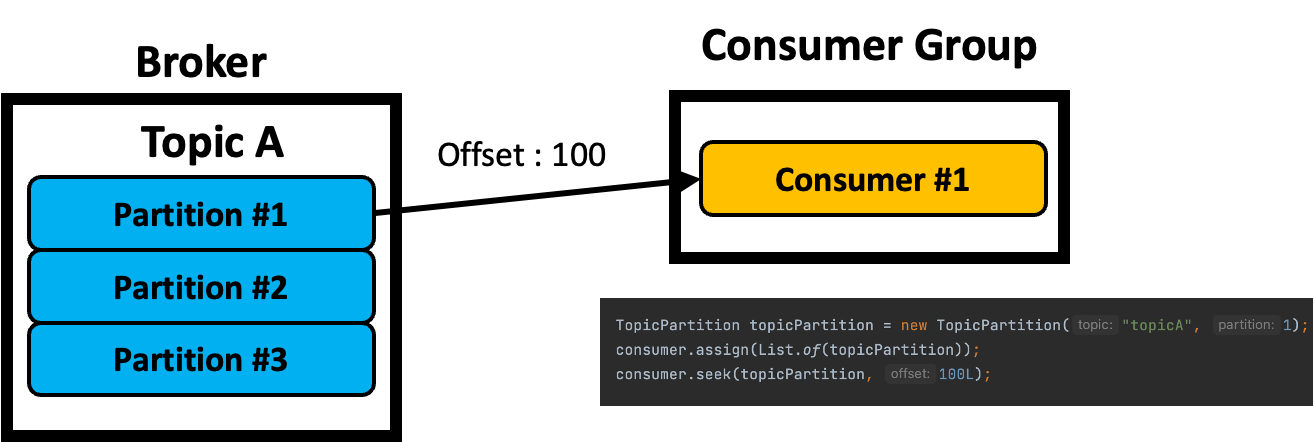
- 실제 동작은 다음과 같은 형태로 한다.
여러 개의 Topic 읽기
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>();
consumer.subscribe(List.of("topicA", "topicB"));
ConsumerRecords<String, String> records = consumer.poll();
for (ConsumerRecord<String, String> record : records) {
log.info("Records = {}", record);
}여러 개의 Topic을 읽으려면 다음과 같이 subscribe를 할 때 여러 토픽을 넣어주면 된다.
private final Map<TopicPartition, List<ConsumerRecord<K, V>>> records;- 이 경우, 읽어온 메세지는 다음과 같은 형태로 저장되어있다. 이 값을 Iteratable 인터페이스를 구현해서 반복문으로 가져오는 형태로 되어있다.
- 이 때, TopicPartition별로 메세지 덩어리가 나누어진 것을 볼 수 있다.
public Iterable<ConsumerRecord<K, V>> records(String topic) {
if (topic == null)
throw new IllegalArgumentException("Topic must be non-null.");
List<List<ConsumerRecord<K, V>>> recs = new ArrayList<>();
for (Map.Entry<TopicPartition, List<ConsumerRecord<K, V>>> entry : records.entrySet()) {
if (entry.getKey().topic().equals(topic))
recs.add(entry.getValue());
}
return new ConcatenatedIterable<>(recs);
}- 그리고 이 TopicPartition Map에서 Key / Value를 각각 가지고 와서 각 토픽 파티션 / 레코드를 하나씩 포장해서 넘겨주는 것을 알 수 있음.
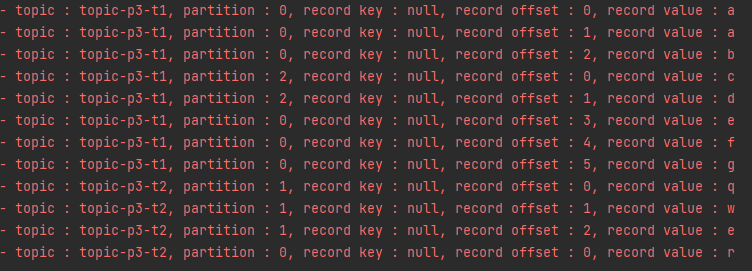
- 하나의 Records를 Iterator를 돌리면 여러 토픽 + 파티션에서의 값이 나오는 것을 볼 수 있다. (p3-t1 / p3-t2)
kafkaConsumer.poll() 메서드의 동작방식
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
acquireAndEnsureOpen();
try {
this.kafkaConsumerMetrics.recordPollStart(timer.currentTimeMs());
if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) {
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
}
do {
client.maybeTriggerWakeup();
if (includeMetadataInTimeout) {
// try to update assignment metadata BUT do not need to block on the timer for join group
updateAssignmentMetadataIfNeeded(timer, false);
}
...
}- acquireAndEnsureOpen()은 카프카 컨슈머가 현재 멀티 쓰레드 환경에서 안전한지를 확인하고 있는 메서드다. 만약 여기서 이미 동작하고 있는 쓰레드가 있다면, "KafkaConsumer is not safe for multi-threaded accedss"라는 로그를 띄운 후 정지한다.
- this.kafkaConsumerMetrics.recordPollStart()는 KafkaConsumerMetric에 현재 poll과 관련된 정보를 전달해주는 역할을 한다. 주로 걸린 시간등을 계산해서 Metrics에 저장해두고, 그 값을 Metric으로 뽑아내주는 역할을 하는 듯 하다.
- this.subscriptions.hasNoSubscriptionOrUserAssigment()는 현재 SubscriptionState에 기록된 토픽이 있는지를 확인한다. 구독하고 있는 토픽이 없다면 여기서 에러가 발생한다.
- client.maybeTriggerWakeUp()은 ConsumerNetworkClient에 wakeUpException을 보낼 수 있는지를 확인하고, 보낼 수 있는 경우 wakeUpException을 보내는 역할을 한다.
- updateAssignmentMetadataIfNeeded() KafkaConsumer의 Meatadata의 값을 업데이트 할 필요가 있는 경우에 업데이트를 한다. 또한 이곳에서는 ConsumerCoordinator가 준비되었는지를 확인하고, 준비가 되지 않은 경우에는 준비가 될 수 있도록 브로커와 통신을 한다.
protected synchronized boolean ensureCoordinatorReady(final Timer timer) {
...
do {
...
client.poll(future, timer);
if (!future.isDone()) {
// ran out of time
break;
}
...
} while (coordinatorUnknown() && timer.notExpired());
return !coordinatorUnknown();
}- updateAssignmentMetadataIfNeeded() 메서드로 들어오게 되면 ConsumerCoordinator의 ensureCoordinatorReady()를 호출한다.이 메서드에서는 client.poll()을 호출한다.
- ConsumerNetworkClient는 내부적으로 Selector를 가지고 있고, 이 Selector는 내부적으로 nioSelector를 가지고 있다. 첫번째 poll() 에서는 가장 먼저 nioselector를 통해서 Broker와 연결되도록 요청을 한다.
@Override
public boolean ready(Node node, long now) {
if (node.isEmpty())
throw new IllegalArgumentException("Cannot connect to empty node " + node);
if (isReady(node, now))
return true;
if (connectionStates.canConnect(node.idString(), now))
// if we are interested in sending to a node and we don't have a connection to it, initiate one
initiateConnect(node, now);
return false;
}- 브로커에게 요청을 보내기 전에 먼저 브로커 노드가 준비가 되었는지를 확인한다. 준비가 되지 않은 경우 initateConnect()를 호출해서 연결을 초기화 한다.
public void poll(Timer timer, PollCondition pollCondition, boolean disableWakeup) {
...
lock.lock();
try {
...
long pollDelayMs = trySend(timer.currentTimeMs());
...
if (pendingCompletion.isEmpty() && (pollCondition == null || pollCondition.shouldBlock())) {
...
client.poll(pollTimeout, timer.currentTimeMs());
} else {
client.poll(0, timer.currentTimeMs());
}
...
} finally {
lock.unlock();
}
...
}- 연결을 요청하는 것도 당연히 ConsumerNetworkClient를 통해서 처리해야한다. 따라서 KafkaConsumer는 ConsumerNetworkClient의 poll() 메서드를 요청한다.
- poll() 메서드에 진입하기 전에 Lock을 획득한다. 이것은 Main 쓰레드 뿐만이 아니라 HeartBeatThread 역시 이 함수를 호출하기 때문에 RaceCondition 문제를 해결하기 위함이다.
- poll() 메서드에서는 가장 먼저 trySend() 라는 메서드를 사용한다.
long trySend(long now) {
...
for (Node node : unsent.nodes()) {
Iterator<ClientRequest> iterator = unsent.requestIterator(node);
...
while (iterator.hasNext()) {
...
if (client.ready(node, now)) {
client.send(request, now);
iterator.remove();
} else {
// try next node when current node is not ready
break;
}
}
}
return pollDelayMs;
}- trySend는 ConsumerNetworkClient에 있는 unsent에 저장된 값들을 가져온다. unsent는 Broker에 요청해야하지만, 아직 보내지 못한 요청을 의미한다.
- 이 때, Client의 ready를 통해서 Node에 메세지를 보낼 준비가 되었는지를 확인하고, unsent된 메세지를 보낸다.
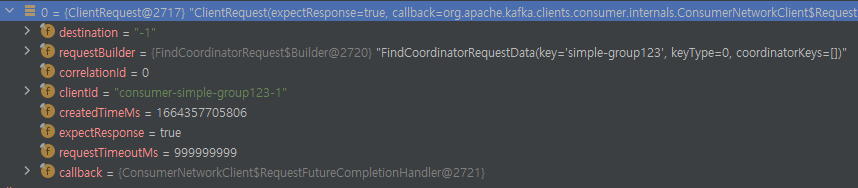
- 가장 처음에 보내고자 하는 요청은 "FindCoordinatorRequestData"이다. Consumer는 처음 생성했을 때, 특정 Consumer Group에 속해서 동작해야한다. 이것은 ConsumerCoordinator가 해주기 때문에 이것을 얻어와야한다.
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest request) {
String destination = clientRequest.destination();
RequestHeader header = clientRequest.makeHeader(request.version());
if (log.isDebugEnabled()) {
log.debug("Sending {} request with header {} and timeout {} to node {}: {}",
clientRequest.apiKey(), header, clientRequest.requestTimeoutMs(), destination, request);
}
Send send = request.toSend(header);
InFlightRequest inFlightRequest = new InFlightRequest(
clientRequest,
header,
isInternalRequest,
request,
send,
now);
this.inFlightRequests.add(inFlightRequest);
selector.send(new NetworkSend(clientRequest.destination(), send));
}- send는 doSend() 메서드를 호출하게 된다.
- 이 때 ConsumerNetworkClient가 가지고 있는 selector를 이용해서 브로커에게 요청을 보내게 된다.
- 또한, 보낸 요청을 ConsumerNetworkClient에 inFlightRequest에 추가해서 기록하는 것을 알 수 있다.
public void poll(Timer timer, PollCondition pollCondition, boolean disableWakeup) {
...
try {
...
long pollDelayMs = trySend(timer.currentTimeMs());
...
client.poll(0, timer.currentTimeMs());
...
}
}- NetworkClient에 보내지 못한(unsent) 요청을 모두 trySend()를 통해서 보냈다. 이제는 응답을 받아야 한다.
- 응답은 client.poll()을 통해서 받을 수 있다. 이것은 클라이언트의 네트워크 상황에 따라 다를 수 있지만, 아무튼 client.poll()을 통해서 받는다.
public List<ClientResponse> poll(long timeout, long now) {
...
try {
this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));
} catch (IOException e) {
...
}
...
List<ClientResponse> responses = new ArrayList<>();
handleCompletedSends(responses, updatedNow);
handleCompletedReceives(responses, updatedNow);
handleDisconnections(responses, updatedNow);
handleConnections();
handleInitiateApiVersionRequests(updatedNow);
handleTimedOutConnections(responses, updatedNow);
handleTimedOutRequests(responses, updatedNow);
completeResponses(responses);
return responses;
}- client.poll()을 하면 selector.poll()을 이용해서 응답을 받아온다. 이것은 NetworkClient가 가지고 있는 nioSelector가 받은 값을 가져온다.
- 가져온 후 handle 메서드들을 이용해서 필요한 마무리 작업들을 처리한다.
- handleCompletedReceives()를 이용해서 받아온 응답을 처리한다.
- nioSelector는 내부적으로 완료된 응답을 저장하는 자료구조가 있는데, 이 자료구조에서 완료된 응답을 받아와서 응답을 Parsing한다.
- 그리고 이 값을 응답에 추가하는 형태가 된다.
- 받아온 응답이 있는 경우 completeResponse()를 호출한다.
private void completeResponses(List<ClientResponse> responses) {
for (ClientResponse response : responses) {
try {
response.onComplete();
} catch (Exception e) {
log.error("Uncaught error in request completion:", e);
}
}
}
-------
public void onComplete() {
if (callback != null)
callback.onComplete(this);
}
--------
@Override
public void onComplete(ClientResponse response) {
this.response = response;
pendingCompletion.add(this);
}- completeResponse()를 호출하면 받아온 response()를 for문을 돌면서 하나씩 실행시켜준다.
- 이 때, onComplete()를 호출해주는데 onComplete()는 response 객체가 가지는 callBack 함수를 각각 호출해주는 역할을 한다.
- 이 때 response 객체는 여러 형태가 있을 수 있기 때문에 그 callBack도 제각각이다. (HeartBeat / Find Coordinator / Fetch / OffsetCommit 등등)
- callBack() 함수는 자기 자신을 pendingCompletion이라는 LinkedQue에 추가하는 함수가 된다. 이 때, 자기 자신은 CompletionHandler이고, pendingCompletion은 ConsumerNetworkClient가 가지고 있다.
public void poll(Timer timer, PollCondition pollCondition, boolean disableWakeup) {
...
lock.lock();
try {
...
client.poll(pollTimeout, timer.currentTimeMs());
...
} finally {
lock.unlock();
}
firePendingCompletedRequests();
...
}- 아무튼 client.poll()(엄밀히 말하면 NetworkClient)가 완료되면 다시 ConsumerNetworkClient로 돌아오게 된다.
- 이 때, 획득했던 Lock을 Release 해준다.
- firePendingCompletedRequests()를 이용해서 ConsumerNetworkClient가 다 처리하지 못한 pendingCompletion을 하나씩 처리해준다.
private void firePendingCompletedRequests() {
boolean completedRequestsFired = false;
for (;;) {
RequestFutureCompletionHandler completionHandler = pendingCompletion.poll();
if (completionHandler == null)
break;
completionHandler.fireCompletion();
completedRequestsFired = true;
}
// wakeup the client in case it is blocking in poll for this future's completion
if (completedRequestsFired)
client.wakeup();
}firePendingCompletedRequests()에서는 ConsumerNetworkClient가 가지고 있는 완료가 되었지만 밀린 응답을 처리하는 작업을 한다.
pendingCompletion.poll()을 하면 pendingCompletion LinkedQue에서 가장 앞에 있는 것이 하나 나온다. 이것은 CompletionHandler다.
public void fireCompletion() {
if (e != null) {
future.raise(e);
} else if (response.authenticationException() != null) {
future.raise(response.authenticationException());
} else if (response.wasDisconnected()) {
log.debug("Cancelled request with header {} due to node {} being disconnected",
response.requestHeader(), response.destination());
future.raise(DisconnectException.INSTANCE);
} else if (response.versionMismatch() != null) {
future.raise(response.versionMismatch());
} else {
future.complete(response);
}
}fireCompletion은 다음과 같이 여러 경우로 나누어지게 된다.
에러가 있는 경우 에러를 만들어 주고, 별 일이 없는 경우 future.complete()를 통해서 완료 처리를 해준다.
public void complete(T value) {
try {
if (value instanceof RuntimeException)
throw new IllegalArgumentException("The argument to complete can not be an instance of RuntimeException");
if (!result.compareAndSet(INCOMPLETE_SENTINEL, value))
throw new IllegalStateException("Invalid attempt to complete a request future which is already complete");
fireSuccess();
} finally {
completedLatch.countDown();
}
}- 이 때 fireSuccess()를 통해서 완료 처리를 해준다.
- 또한 이 Future 객체는 내부적으로 카운트다운 Latch를 가지고 있고, 이것으로 멀티 쓰레드와 관련된 작업을 처리해주는 것을 볼 수 있다.
private void fireSuccess() {
T value = value();
while (true) {
RequestFutureListener<T> listener = listeners.poll();
if (listener == null)
break;
listener.onSuccess(value);
}
}- fireSuccess()는 Fetcher가 가지고 있는 리스너 중에서 가장 앞에 있는 것을 가져와서 onSuccess() 메서드에 응답 결과를 던지면서 처리되는 것을 볼 수 있다.
@Override
public void onSuccess(ClientResponse resp) {
synchronized (Fetcher.this) {
try {
...
Map<TopicPartition, FetchResponseData.PartitionData> responseData = response.responseData(handler.sessionTopicNames(), resp.requestHeader().apiVersion());
Set<TopicPartition> partitions = new HashSet<>(responseData.keySet());
FetchResponseMetricAggregator metricAggregator = new FetchResponseMetricAggregator(sensors, partitions);
for (Map.Entry<TopicPartition, FetchResponseData.PartitionData> entry : responseData.entrySet()) {
TopicPartition partition = entry.getKey();
FetchRequest.PartitionData requestData = data.sessionPartitions().get(partition);
if (requestData == null) {
...
} else {
long fetchOffset = requestData.fetchOffset;
FetchResponseData.PartitionData partitionData = entry.getValue();
...
Iterator<? extends RecordBatch> batches = FetchResponse.recordsOrFail(partitionData).batches().iterator();
...
completedFetches.add(new CompletedFetch(partition, partitionData,
metricAggregator, batches, fetchOffset, responseVersion));
}
}
...
} finally {
...
}
}
}- 리스너는 응답 결과를 받아서, 응답 객체 안에 있는 Key / Value 값을 Topic의 Partition 단위로 Parsing한다.
- entry.getKey()를 이용해서 Partition 값을 가져온다.
- entry.getValue()를 이용해서 레코드를 가져오고, 이 레코드를 FetchResponse.recordsOrFail() 메서드를 이용해서 batchs 형태로 만들어준다.
- 완성된 Batch는 completedFetches에 추가된다. 이 compltedFetches는 Fetcher가 가지고 있는 LinkedQue다.
private void firePendingCompletedRequests() {
boolean completedRequestsFired = false;
for (;;) {
RequestFutureCompletionHandler completionHandler = pendingCompletion.poll();
if (completionHandler == null)
break;
completionHandler.fireCompletion();
completedRequestsFired = true;
}
// wakeup the client in case it is blocking in poll for this future's completion
if (completedRequestsFired)
client.wakeup();
}- 다시 firePendingCompletedRequests()로 돌아온다. 결국 완료 Handler를 다 처리해주게 되면, Client.WakeUp()을 해준다.
- Client.wakeUp()을 이용해서 Selector()를 깨워서 다시 한번 메세지를 보낼 수 있는 형태로 변경해준다.
- 또한, 이 때 첫번째 호출이라면 Kafka-Coordinator-HeartBeat-Thread가 생성된다.
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
...
try {
...
updateAssignmentMetadataIfNeeded(timer, false);
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
if (!records.isEmpty()) {
...
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
...
}
}- KafkaConsumer는 updateAssignmentMeataDataIfNeeded 메서드 호출에서 돌아오면 pollFoirFetches()를 통해서 브로커에게서 받아온 값을 하나씩 읽어온다.
- timer.notExpired()를 통해서 만약에 읽어온 메세지가 없다면 do ~ while 루프를 돌면서 계속 값을 불러오고자 한다.
- KafkaConsumer.poll() 내부에서 브로커와 통신을 요청하는 client.poll() 메서드는 updateAssignment 및 pollForFetches()에 모두 존재한다.
- 이 때, Client.poll()은 ConsumerNetworkClient가 보내지 않은 unsent 요청을 전부 보내기 때문에 각 메서드마다 각각 요청을 정해서 보내지는 않는다.
KafkaConsumer Main 쓰레드 / Kafka-Coordinator-Heartbeat-Thread
- Consumer는 메인 쓰레드와 Heartbeat 쓰레드 두 개로 나누어져 병렬로 움직이고 있다.
- KafkaConsumer가 있는 메인 쓰레드는 기본적으로 브로커에게 요청을 보낸 다음에 Batch가 차면 그 Batch를 Parsing해서 레코드를 가져오는 역할을 한다.
- 반면 HeartBeat 쓰레드는 주구장창 Broker에게 요청을 보내는 역할만 한다.
// AbstractCoordinator.java
@Override
public void run() {
try {
...
while (true) {
synchronized (AbstractCoordinator.this) {
...
client.pollNoWakeup();
...
}}}- HeartBeat 쓰레드는 AbstractCoordinator 클래스의 run() 메서드의 client.pollNoWakeup() 메서드를 무한루프를 돌면서 호출하면서 주구장창 통신 메서드를 보낸다.
- 이 때, client는 ConsumerNetworkClient다.
public void pollNoWakeup() {
poll(time.timer(0), null, true);
}- ConsumerNetworkClient의 pollNoWakeUp()은 결국 ConsumerNetworkClient를 poll()하는 것이다.
- 따라서 HeartBeat 쓰레드는 끊임없이 NetworkClient를 브로커와 통신하는 역할만한다.
ConsumerNetworkClient의 Unsent 객체들
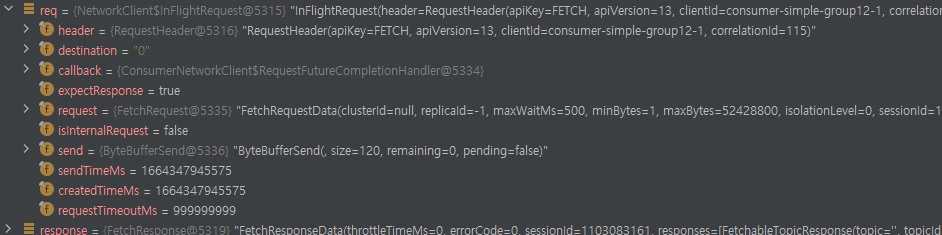
- ConsumerNetworkClient의 Unsent 객체에는 정말 여러가지 타입의 요청이 올 수 있다.
- 단적인 예로 위와 같이 FETCH를 요청하는 객체가 있는 경우 다음과 같은 객체가 unsent에 저장된다.
- 이 뿐만 아니라 HeartBeat / Offset Commit / Find Coordinator 등 다양한 요청 객체가 올 수 있다.
ConsumerNetworkClient의 FecthRequest 객체

- fetchRequest 객체는 요청을 보낼 때, 다음과 같은 형태로 만들어져서 보내지게 된다.
- 이 때, VAlue에는 fetchOffset이 들어가는 것을 볼 수 있다. 즉 다음에 어디서부터 받아야 하는지에 대한 값을 Consumer가 브로커에게 전달하는 것을 볼 수 있다.
코드 추적 : records 가져오기
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
...
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
...
return ConsumerRecords.empty();
}- Consumer는 poll() 메서드가 호출되면, pollForFetches()라는 메서드를 이용해서 브로커로부터 받아온 메세지를 가져온다.
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollForFetches(Timer timer) {
...
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
if (!records.isEmpty()) {
return records;
}
...
return fetcher.fetchedRecords();
}- pollForFetches() 메서드가 호출되면, fetcher의 fetchedRecords()라는 메서드를 호출하게 된다.
public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() {
...
int recordsRemaining = maxPollRecords;
try {
while (recordsRemaining > 0) {
if (nextInLineFetch == null || nextInLineFetch.isConsumed) {
...
} else {
nextInLineFetch = records;
}
completedFetches.poll();
} else {
List<ConsumerRecord<K, V>> records = fetchRecords(nextInLineFetch, recordsRemaining);
return fetched;
}- 먼저 maxPollRecords의 값에 recordsRemaining을 넣어준다.
- 한번에 가져올 수 있는 레코드 갯수를 기록해주는데, 처음에 이 함수로 들어가면 nextInLineFetch가 존재하지 않기 때문에 그 값을 가져온다.
- nextInLineFetch가 존재하게 되면 fetchRecords()라는 함수를 호출한다.
private List<ConsumerRecord<K, V>> fetchRecords(int maxRecords) {
...
List<ConsumerRecord<K, V>> records = new ArrayList<>();
try {
for (int i = 0; i < maxRecords; i++) {
if (cachedRecordException == null) {
...
lastRecord = nextFetchedRecord();
...
}
...
records.add(parseRecord(partition, currentBatch, lastRecord));
recordsRead++;
bytesRead += lastRecord.sizeInBytes();
nextFetchOffset = lastRecord.offset() + 1;
cachedRecordException = null;
}
} catch (SerializationException se) {
...
} catch (KafkaException e) {
...
}
return records;
}- Fetcher의 fetchRecords가 호출된다.
- nextFetcehdRecord() 메서드를 이용해서 Batch에서 다음 읽어올 Byte Buffer 형태의 데이터를 읽어와 lastRecord에 저장한다.
- Record를 담을 ArrayList를 생성한다.
- LastRecord를 parseRecord()를 통해서 Parsing 하고 그 값을 ArrayList에 추가한다.
private ConsumerRecord<K, V> parseRecord(TopicPartition partition,
RecordBatch batch,
Record record) {
try {
long offset = record.offset();
Headers headers = new RecordHeaders(record.headers());
ByteBuffer keyBytes = record.key();
byte[] keyByteArray = keyBytes == null ? null : Utils.toArray(keyBytes);
K key = keyBytes == null ? null : this.keyDeserializer.deserialize(partition.topic(), headers, keyByteArray);
ByteBuffer valueBytes = record.value();
byte[] valueByteArray = valueBytes == null ? null : Utils.toArray(valueBytes);
V value = valueBytes == null ? null : this.valueDeserializer.deserialize(partition.topic(), headers, valueByteArray);
return new ConsumerRecord<>(partition.topic(), partition.partition(), offset,
timestamp, timestampType,
keyByteArray == null ? ConsumerRecord.NULL_SIZE : keyByteArray.length,
valueByteArray == null ? ConsumerRecord.NULL_SIZE : valueByteArray.length,
key, value, headers, leaderEpoch);
} catch (RuntimeException e) {
...
}
}- parseRecord()에서는 record에서 byteBuffer 타입으로 Key / Value 값을 불러온다.
- 불러온 Key / Value를 ByteArray로 바꿔준 후에 deserializer를 이용해서 역직렬화를 해준다.
- 역직렬화가 완료된 Key , Value와 함께 ConsumerRecord를 만들어서 반환해준다.
- 이 때, 앞서 호출한 메서드에서 for 문을 돌면서 레코드를 하나씩 전달하기 때문에 하나의 레코드에 대해서만 이 작업을 하고 반환해준다.
public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() {
...
} else {
List<ConsumerRecord<K, V>> records = fetchRecords(nextInLineFetch, recordsRemaining);
if (!records.isEmpty()) {
TopicPartition partition = nextInLineFetch.partition;
List<ConsumerRecord<K, V>> currentRecords = fetched.get(partition);
if (currentRecords == null) {
fetched.put(partition, records);
}
recordsRemaining -= records.size();
}
}
}
...
return fetched;- parse 작업을 반복해서 ArrayList에 저장된 Record를 Fetcher는 반환받는다.
- Fetcher는 이 Records를 fetched라는 HashMap에 저장하고, 이것을 반환해준다.
- 이 때, HashMap에는 Key에는 Partition 번호, Value에는 브로커로부터 읽어온 Record를 담은 ArrayList가 들어간다.
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollForFetches(Timer timer) {
...
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
if (!records.isEmpty()) {
return records;
}
...
}- 위의 작업이 끝나면 그 결과값은 KafkaConsumer에게 반환된다. KafkaConsumer는 fetched를 전달받고, 이것을 records에 저장한다.
- records가 비지 않았기 때문에 KafkaConsumer는 pollForFetches()를 위한 메서드에서 레코드를 읽어서 반환할 수 있게 된다.
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
...
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
if (!records.isEmpty()) {
...
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
...
}
}- KafkaConsumer의 Poll()로 돌아온다. Poll()에서는 전달받은 records를 interceptors.onConsume() 메서드를 호출하고, 그 결과값을 kafkaConsumer.poll()의 결과값으로 반환한다.
public ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records) {
ConsumerRecords<K, V> interceptRecords = records;
for (ConsumerInterceptor<K, V> interceptor : this.interceptors) {
try {
interceptRecords = interceptor.onConsume(interceptRecords);
} catch (Exception e) {
// do not propagate interceptor exception, log and continue calling other interceptors
log.warn("Error executing interceptor onConsume callback", e);
}
}
return interceptRecords;
}- 이 메서드는 만약 Interceptor가 존재한다면, interceptor가 전달받은 records를 consume할 수 있도록 해준다.
- 그렇지 않을 경우, 그 값을 그냥 바로 반환해준다.
'Kafka eco-system > Kafka' 카테고리의 다른 글
| Kafka Broker : Replication (0) | 2022.11.29 |
|---|---|
| Kafka : 프로듀서의 전송 방법 (idempotence, at least once, at most once, exactly once) (0) | 2022.11.23 |
| kafka-dump-log 명령어로 로그 파일의 메세지 내용 확인 (0) | 2022.09.05 |