
멀티 쓰레드 관련 공부
- 프로그래밍 언어 / JAVA
- 2022. 2. 25.
- 1. 프로세스와 쓰레드
- 2. 쓰레드의 구현과 실행
- 3. start(), run()
- 4. 싱글 쓰레드와 멀티 쓰레드 with 코어
- 5. 쓰레드의 우선순위
- 6. 데몬 쓰레드
- 7. 쓰레드의 실행 제어
- 8. 쓰레드의 동기화
이 글은 자바의 정석, 다른 블로거님의 글을 참고해 작성한 글입니다.
1. 프로세스와 쓰레드
프로세스는 실행 중인 프로그램을 의미한다. 쉽게 말하면 ctrl + alt + del의 프로세스 탭에 올라와있는 것 하나를 하나의 프로세스라고 부른다. 프로세스는 프로그램을 수행하는데 필요한 데이터, 메모리, 쓰레드로 구성되어있다. 쓰레드는 프로그램이 돌아가게 하는 일꾼이다.
쓰레드는 작업을 처리하기 위해 개별적인 메모리 공간을 요구한다. 프로세스에게 할당된 메모리 공간을 한정적이다. 따라서 한 프로세스에서 생성될 수 있는 쓰레드의 갯수는 한정적이다.
멀티태스킹과 멀티쓰레드
MS-DOS에서는 한번에 하나의 프로세스만 할 수 있었다. 게임을 실행하면 게임만 해야한다. 그렇지만 윈도우에서는 게임을 하면서 음악을 들을 수 있다. 윈도우는 한번에 여러 개의 프로세스가 실행 가능하다. 이것을 멀티 태스킹이라고 한다.
멀티 쓰레딩은 프로세스 안의 개념이다. 한 프로세스 안에 하나의 쓰레드가 일을 하면 싱글 쓰레딩, 여러 개의 쓰레드가 동시에 작업을 진행하면 멀티 쓰레드가 된다. 예를 들어 카카오톡은 채팅을 하면서, 동시에 파일 전송이 가능하다. 이것은 하나의 쓰레드가 채팅 기능을 수행, 또 다른 쓰레드가 파일 전송 기능을 수행하기 때문에 가능하다. 이것을 멀티 쓰레드라고 한다.
멀티쓰레드의 장단점
싱글쓰레드로 서버 프로그램을 작성한다면 사용자의 요청마다 새로운 프로세스를 생성해야한다. 프로세스를 생성하는 것은 쓰레드를 생성하는 것에 비해 더 많은 시간과 메모리 공간이 필요하다. 멀티쓰레드로 서버 프로그램을 작성한다면, 여러 개의 쓰레드를 생성해서 동시에 여러 요청을 처리할 수 있게 된다.
멀티쓰레드는 동시성 문제가 발생할 수 있다. 멀티 쓰레드는 같은 프로세스의 자원을 공유하며 작업을 하기 때문에 동기화(Synchronization), 교착상태(deadLock) 등에 빠질 수 있다. 따라서 이 문제를 충분히 고려해서 멀티쓰레드를 사용해야한다.
2. 쓰레드의 구현과 실행
- Runnable 객체 생성 : 작업할 '내용'을 만든다
- 쓰레드 생성 : 쓰레드를 생성하며 작업할 내용을 할당한다.
쓰레드를 생성하며, 무슨 일을 할지를 알려줘야한다. 이 때 쓰레드는 Thread 클래스의 생성자로 생성하면 된다.
쓰레드의 구현
Runnable 구현체 생성 + 쓰레드에게 할당
@Test
void test2() {
Runnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
}
static class MyRunnable implements Runnable{
@Override
public void run() {
System.out.println("Thread New");
}
}
쓰레드 + 익명 클래스를 이용한 Runnable 객체 생성
@Test
void test1() {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Thread New");
}
});
}
쓰레드의 실행
쓰레드는 만든다고 실행되는 것이 아니다. 만들어진 쓰레드를 실행시켜줘야 쓰레드는 동작한다. 쓰레드를 실행시키면, '실행 대기 상태'가 된다. 자신의 차례가 오면 쓰레드는 실행된다. 이 때, 종료된 쓰레드는 다시 실행할 수 없다. 쓰레드는 start() 메서드로 실행한다.
쓰레드 실행 start()
@Test
void test1() {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Thread New");
}
});
thread.start();
}
3. start(), run()
Thread는 내부적으로 run() 메서드를 가진다. 그렇다면 한 가지 궁금한 점이 생긴다. thread.start(), thread.run()은 실제로 어떻게 다른 것일까? 반드시 알고 있어야 할 내용은 쓰레드는 작업을 진행하기 위해 자시만의 메모리 공간을 가져야 한다는 점이다.
- thread.run() : 스레드가 가지고 있는 run() 메서드를 단순 호출한다.
- thread.start() : 스레드가 작업에 필요한 공간을 만들고, 그 공간에 run()을 올린다.

thread.run()
- 메인쓰레드는 자신의 호출 스택에 run()을 올린다.
thread.start()
- 메인쓰레드는 새로운 스레드가 작업할 작업 공간을 할당한다.
- 할당한 작업 공간에 run을 올린다.
동작 과정
thread.start()를 하게 되면 쓰레드가 '실행 대기 상태'로 작업 큐에 들어간다. 스케쥴러는 실행 대기 중인 쓰레드의 우선순위를 고려하여 실행 순서, 실행 시간을 배분한다. 그리고 쓰레드는 스케쥴에 의해 할당된 작업 시간이 되면 작업을 하고 대기 상태로 돌아간다. 작업을 마친 쓰레드는 사용하던 호출 스택은 모두 반납된다.
main Thread
자바는 항상 main 메서드를 통해 실행한다. main 메서드를 실행하는 것은 main 쓰레드다. 프로세스가 돌아가려면 최소한 일꾼 하나는 있어야하는데 그것이 main 메서드다. 기존 프로그래밍(싱글 쓰레드 환경)에서는 main 메서드의 호출 스택이 비워지면 프로그램이 종료되었다. 그렇지만 멀티 쓰레드 환경에서는 실행 중인 쓰레드가 하나라도 남아있다면, 프로그램은 유지된다.
멀티쓰레드 환경, 예외 발생하면?
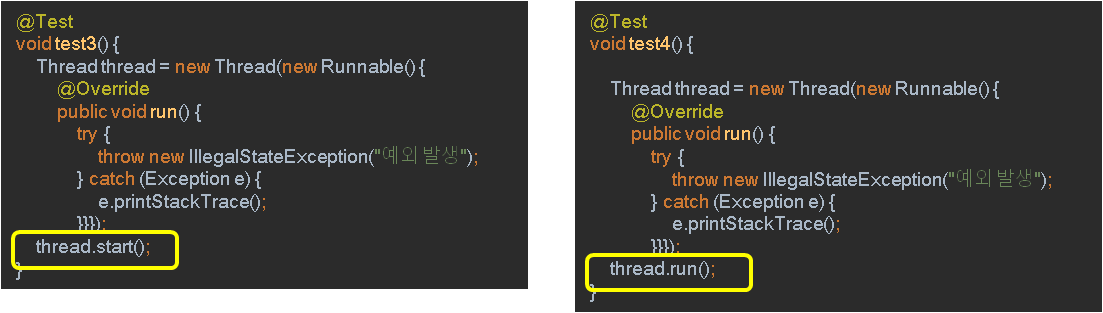
멀티 쓰레드 환경에서 예외가 발생하는 경우를 생각해보자. 두 개의 쓰레드가 돌아가는데, 하나의 쓰레드에서 예외가 발생해도 나머지 쓰레드의 동작에는 영향을 주지 않는다. 철저하게 작업을 분리해서 하고 있기 때문이다.
위의 코드를 통해서 이것을 확인할 수 있다. 예외를 발생하는 코드를 작성했다. 왼쪽은 start() 메서드로 멀티 쓰레드 환경을 만든다. 오른쪽은 run() 메서드로 main 메서드가 thread의 일을 대신하는 것으로 이해할 수 있다.

왼쪽의 결과는 run() 메서드에만 문제가 있다고 나온다. 왜냐하면 main 메서드는 새로운 쓰레드를 위한 작업 공간을 만들고, 그 위에 run() 메서드를 호출하는 것이 작업의 전부였기 때문이다. 따라서 main 메서드는 종료되었다.
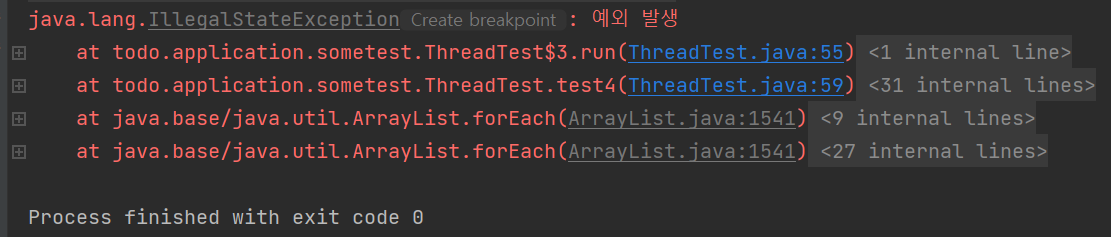
오른쪽 결과는 test4 메서드부터 문제가 있다고 나온다. 왜냐하면 test4를 실행하는 main 메서드의 호출 스택에 run 메서드가 들어가있기 떄문이다. 즉, 싱글 스레드 환경에서 main 메서드가 run() 메서드까지 실행해주기 때문에 다음과 같은 결과가 나왔다.
4. 싱글 쓰레드와 멀티 쓰레드 with 코어
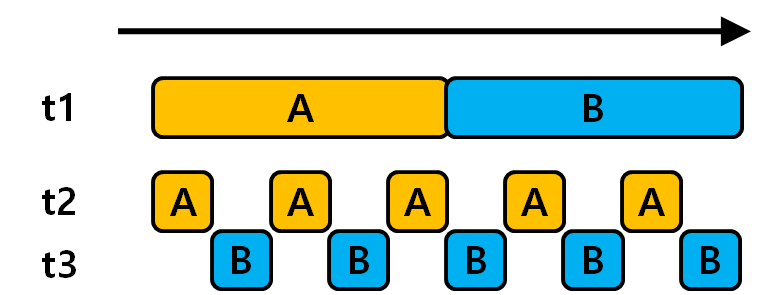
먼저 싱글 코어 환경을 생각해보자. 싱글 쓰레드는 하나의 쓰레드로 작업을 처리하는 것을 의미한다. 멀티 쓰레드는 여러 쓰레드로 작업을 처리하는 것을 이야기한다. t1은 싱글쓰레드 환경으로 A 작업이 끝나면, B작업을 이어서 한다. t2,t3는 멀티쓰레드 환경으로 작업을 한다. 그렇지만 코어가 하나이기 때문에 멀티 쓰레드지만 동시에 작업을 처리할 수는 없다.
싱글 코어 환경에서 멀티 쓰레드로 동작할 경우 오히려 싱글 쓰레드에 비해 시간이 더 걸린다. 왜냐하면 t2 ↔ t3 쓰레드끼리 작업 교체(Context Switching)에 비용이 발생하기 때문이다. 따라서 싱글코어로 작업할 경우 싱글쓰레드가 좀 더 좋은 효율을 보일 수 있다.

싱글 코어 환경에서 멀티 쓰레드는 여러 자원을 사용해야할 때, 싱글 쓰레드 대비 좋은 효율을 보인다. 예를 들어 입력을 받는 일과 1~10을 출력하는 일을 해야한다고 가정해보자. t1 싱글쓰레드 환경에서는 사용자의 입력이 들어올 때까지(A~A 구간) 기다려야 한다. 그리고 A과 완료되어야 B를 출력할 수 있다.

t2,t3 멀티 쓰레드 환경에서는 사용자의 입력을 기다리는 동안 B가 싱글 코어를 점유해서 작업을 처리할 수 있다. 따라서 이런 경우는 멀티 쓰레드 환경이 좀 더 효율적으로 동작한다.

멀티코어를 이용할 때, 멀티 쓰레드 환경을 다시 보자. 싱글 코어에서는 여러 쓰레드가 작업 큐에 들어가면서 허용된 시간만큼만 싱글 코어를 점유하고 대기하는 형태로 작업을 했다. 그렇지만 멀티 코어에서는 극단적으로 t4, t5 쓰레드가 각 코어를 점유할 수 있기 때문에 동시에 A,B 작업이 완료될 수 있다.
5. 쓰레드의 우선순위
쓰레드는 내부적으로 우선순위(Priority)를 가진다. 우선순위 값을 설정해주면, 스케쥴러는 쓰레드의 우선순위 값을 참고해 작업 시간을 배분한다. 기본적으로 우선순위는 1~10의 값을 가지고, main 쓰레드의 우선순위는 5다. 만들어지는 쓰레드의 우선순위의 값은 기본적으로 쓰레드를 만들어주는 쓰레드의 우선순위를 따른다. 예를 들어 main 쓰레드가 쓰레드를 만들면, 만들어진 쓰레드의 우선순위는 5다.

쓰레드 우선순위가 동일할 경우 스케쥴러에 의해 쓰레드마다 할당되는 작업 시간이 동일하다.

쓰레드 우선순위가 다를 경우, 스케쥴러에 의해 우선순위가 더 높은 쓰레드에 더 많은 작업 시간이 할당된다.
쓰레드 우선순위 할당
thread.setPriority(10);
thread.setPriority(1);만들어진 쓰레드의 우선순위는 setPriority() 메서드를 이용해 할당할 수 있다.
6. 데몬 쓰레드
데몬 쓰레드는 일반 쓰레드가 잘 동작할 수 있도록 도와주는 보조 쓰레드의 개념이다. 따라서 일반 쓰레드가 더 이상 동작하지 않으면, 데몬 쓰레드가 남아 있다고 하더라도 프로세스는 종료된다. 데몬 쓰레드는 주로 GBC, 게시글 임시 저장 등의 작업을 하는데 사용된다.
thread.setDaemon(true); // 데몬 쓰레드 선언
thread.start(); // 데몬 쓰레드 시작데몬 쓰레드로 사용하기 위해서는 쓰레드를 시작하기 전에 반드시 setDaemon 메서드에 True 값을 설정해줘서 데몬 쓰레드로 만들어줘야한다. 데몬 쓰레드는 주로 Runnable 인터페이스 내부에 무한 루프를 돌도록 설정한 후, 대기 + 작업을 하도록 구성해줘야한다.
7. 쓰레드의 실행 제어
쓰레드에 우선순위를 설정하면서 쓰레드 간의 스케쥴링에 눈꼽만큼의 영향을 줄 수 있게 되었다. 예를 들어 더 중요한 작업은 우선순위를 높게 주어 작업 시간을 더 길고 잦게 할 수 있도록 하는 것이었다. 그렇지만 스케쥴러에 의한 스케쥴링만으로는 효율적이지 않을 수 있다. 따라서 자바는 쓰레드의 상태를 설정할 수 있도록 실행 제어 기능을 제공한다.
쓰레드의 전반적인 흐름
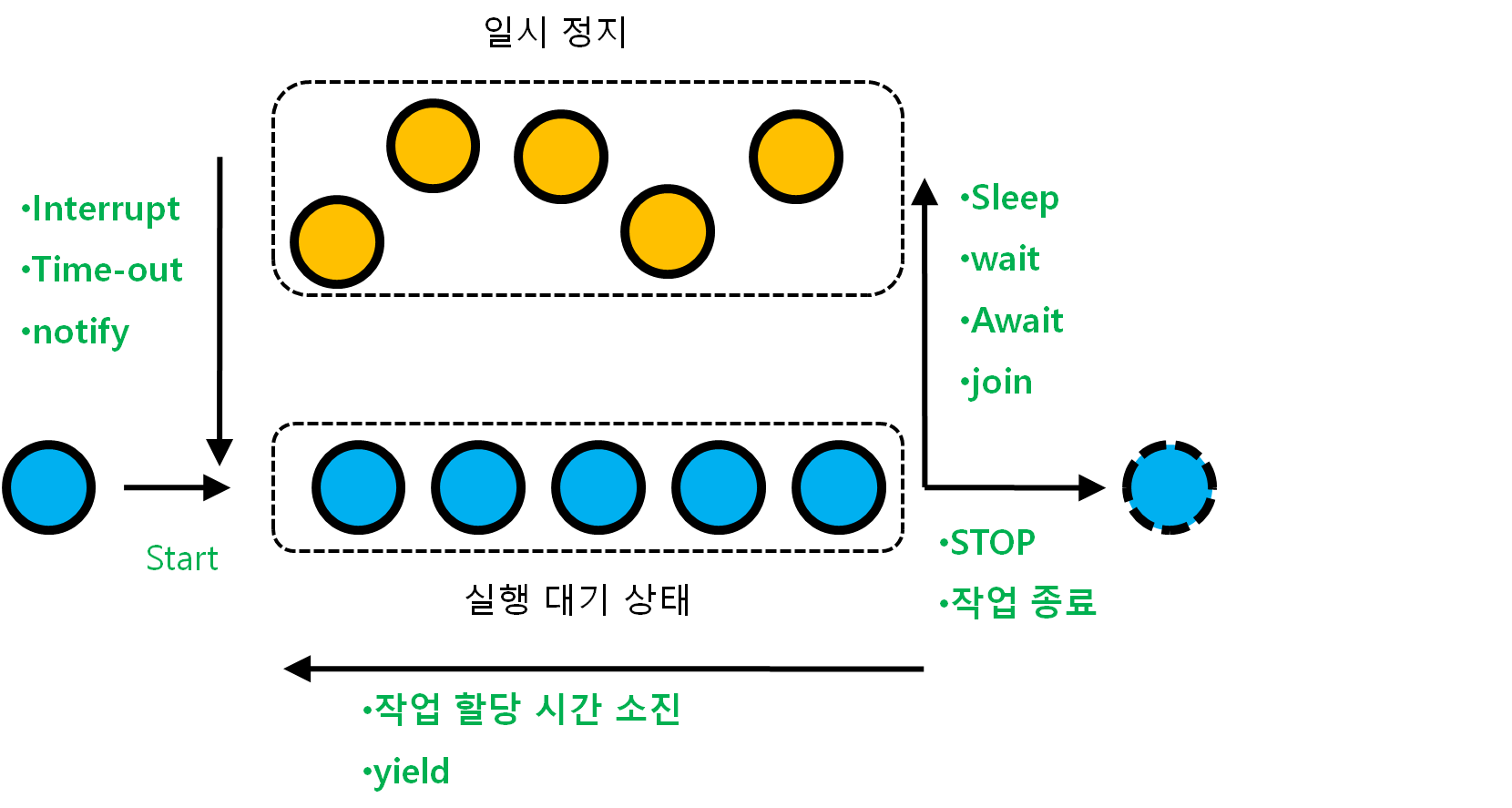
- 쓰레드의 전반적인 흐름은 위와 같이 정리할 수 있다.
- 쓰레드가 만들어진다.
- 쓰레드가 start 메서드를 만나면 실행 대기 상태에 들어간다.
- 쓰레드의 작업이 종료되거나 STOP되면, 쓰레드는 종료된다.
- 쓰레드에게 할당된 작업 시간이 다 소진되거나, yield를 만나면 쓰레드는 다새 실행 대기 큐로 들어간다
- 쓰레드가 sleep, wait, await, join을 만나면 일시 정지 Waiting Pool로 들어가서 기다린다
- 일시정지 Waiting Pool의 쓰레드는 Interrupt를 만나면 Exception을 발생하며 실행대기 상태로 들어간다. notify, Time Out이 되면 쓰레드는 자동으로 실행대기 상태로 들어간다.
쓰레드 Sleep
Sleep은 쓰레드를 일정시간 동안 일시정지 상태로 만든다. 이 때, 쓰레드는 Waiting Pool로 들어가게 되고 일정 시간이 지나면 실행대기 상태로 들어온다. 혹은 Interrupt를 만나도 들어온다. Sleep은 현재 실행중인 쓰레드가 대상이 되기 때문에 항상 static으로 사용한다.
쓰레드 Interrupt
긴 파일을 다운받고 있는 쓰레드가 있다. 그런데 중간에 이 작업을 취소시키고 싶을 수 있다. 이 때 Interrupt를 하면 쓰레드는 하던 작업을 멈추고 Waiting Pool로 들어간다.
Interrupt는 또 다른 기능도 가지고 있다. Waiting Pool에서 쉬고 있는 쓰레드가 Interrupt를 만나면 Interrupted라는 Exception을 발생시키며 실행 대기 큐로 들어간다. 이렇듯 Exception이 발생하기 때문에 Sleep 같이 Waiting Pool에서 대기하는 함수들을 try / catch로 감싸진다.
쓰레드 Yield
쓰레드가 Yield 명령어를 만나면 현재 쓰레드에게 남은 작업 시간을 실행 대기 큐에 있는 다음 쓰레드에게 넘기고, 현재 쓰레드는 자동으로 실행 대기 큐 제일 뒤로 가서 줄을 선다. Yield를 적절하게 사용하면 프로그램의 응답성을 높이는데 도움이 된다.
while(!a){
if(!b){
...
}
else{
Thread.yield(); // 무한 루프에서 허송세월 낭비 X
}
}다음 코드에서 yield를 추가해서 반응성을 높일 수 있다. 어떤 쓰레드는 "b"인 동안 의미없이 While문에서 루프를 타야한다. 이처럼 하는 것은 없는데 쓰레드가 열일 하는 것처럼 보이는 것이 "busy-Waiting" 상태라고 한다. 이런 대기 상태일 때, 쓰레드가 코어를 가지고 있는 것이 아니라 다음 쓰레드에게 Yield로 코어 점유권을 넘겨주면 프로그램의 응답성이 좋아진다.
쓰레드 Join
현재 쓰레드가 Join 메서드를 만나게 되면, 현재 쓰레드는 Join 메서드의 대상이 되는 쓰레드의 작업이 끝날 때까지 일시정지를 한다. Join에는 시간을 넣을 수 있는데, 시간을 넣을 경우 그 시간만큼 Join의 작업이 끝날 때까지 기다린다는 의미다. Waiting Pool에 들어가 특정 쓰레드의 작업이 끝날 때까지 대기하는데, Interrupt로 일시 대기 상태를 끝낼 수 있다.
thread1.join();예를 들어 위의 문장을 만나면 현재 쓰레드는 'thread1'의 작업이 끝날 때까지 일시정지 상태에서 대기한다. 대표적인 예로는 GBC를 모사한 프로그래밍이 될 수 있다. 이렇게 프로그램을 구성할 수 있다.
- 메인 쓰레드들이 작업을 한다.
- 메인 쓰레드들이 작업을 하던 도중 남은 메모리 용량이 40% 수준인 것을 확인한다
- 40% 수준 이하로 떨어지면, 메인 쓰레드는 GBC.join()을 호출해서 GBC가 작업을 먼저 할 수 있도록 한다.
8. 쓰레드의 동기화
멀티 쓰레드 환경에서 각 쓰레드는 자원을 공유한다. 따라서 의도치 않게 다른 쓰레드가 또 다른 쓰레드의 작업을 방해할 수 있다. 이런 문제를 막기 위해서 다른 쓰레드에 의해 작업이 방해받지 않도록 해야한다. 이런 문제를 '동기화(Syncrhonization)'이라고 한다.
동기화는 '임계 영역'과 '락'이라는 두 가지 개념으로 구성된다. 특정 영역을 설정하고, 그 영역에서는 '락'이라는 권한을 가진 쓰레드만 그 영역을 활용할 수 있게 해주는 것이다. 특정 영역의 락을 한 쓰레드가 얻어서 사용하고 있을 때, 다른 쓰레드가 그 영역에 도착한다면 기존 쓰레드의 작업이 끝나고 락이 반환될 때 까지 기다려야 한다.
이런 이유 때문에 동기화를 하게 된다면, 일정 부분 프로그램 응답성이 떨어지는 효과가 있다. 따라서 임계영역을 적재적소에 잘 분배해서 사용할 수 있어야 한다.
쓰레드의 동기화 : Synchronized
Synchronized 키워드를 이용하면 임계영역을 손쉽게 설정할 수 있다. 쓰레드는 임계영역에 도착하면 락을 얻을 수 있는 경우에만 작업을 하고, 그렇지 못한 경우에는 락을 얻을 때까지 기다린다.
// 메서드 영역을 임계 영역 설정
public synchronized void calcSum(){...}
// 특정 영역을 임계 영역 설정
synchronized(객체의 참조 변수){...}임계영역은 위 코드에서처럼 손 쉽게 설정할 수 있다. 그렇지만 남발하면 안된다. 프로그램의 응답성일 떨어지기 때문이다.
쓰레드의 동기화가 길어지면? wait, notify
동기화를 통해 공유되는 자원을 보호하는 것은 좋다. 그렇지만 불의의 사건으로 임계영역을 한 쓰레드가 점거하는 시간이 길어진다면 어떻게 될까? 모든 쓰레드가 여기에서 대기할 것이므로 프로그램은 곧 멈추게 될 것이다. 따라서 특정 쓰레드가 락을 오래 가지고 있는 것을 지양하는 것이 좋다.
이 때 사용할 수 있는 것이 wait, notify 명령어다. 쓰레드가 wait()를 만나게 되면, 쓰레드는 락을 반납하고 현재 상태를 기억한 채 waiting Pool로 들어간다. 나중에 작업을 진행할 수 있는 상태가 되면 notify() 명령어를 이용해 쓰레드에게 통지한다. 그러면 쓰레드는 실행 대기 큐로 들어가서 자신의 차례를 기다리게 된다.
notify, notifyAll 명령어가 있다. notify는 waiting Pool에 있는 무작위 쓰레드에게 '너 일하러 가"라고 이야기 하는 것이다. 따라서 우리가 원하는 대상이 다시 실행 대기 상태로 들어가지 못할 수도 있다. 재수가 없으면 평생 통지를 못 받을 수 있다. 이를 기아 문제(Starvation)이라고 한다. notifyAll은 waiting Pool에 있는 모든 쓰레드에게 일하러 가라고 하는 것이다. 따라서 모든 쓰레드들이 실행대기 상태로 들어가기 때문에 다시 한번 Lock을 얻기 위해서 대기해야한다. 즉, 쓰레드들이 Lock을 얻기 위해 경쟁을 해야하기 때문에 경쟁 상태(Race Condition) 문제가 생긴다.
객체마다 Waiting Pool을 가지고 있다. 예를 들어 Table 객체가 있고, Chair 객체가 있다고 가정해보자. Table 객체에서 작업하던 쓰레드가 멈추게 되면 이 쓰레드는 "Table 객체 Waiting Pool"로 들어간다. Chair 객체에서 작업하던 쓰레드가 멈추게 되면 이 쓰레드는 "Chair 객체 Waiting Pool"로 들어간다. NotifyAll은 특정 객체의 Waiting Pool에 있는 모든 쓰레드들에게만 적용이 된다.
기아 현상과 경쟁 상태
notify 메서드를 이용하면 임의의 쓰레드가 통지를 받는다. 재수가 없으면 평생 어떤 쓰레드는 통지를 못받을 수 있다. 이런 현상을 기아현상이라고 한다. notifyAll을 할 경우 특정 waiting Pool에 있는 모든 쓰레드가 실행 대기 상태로 간다. 즉, 모든 쓰레드가 동시에 Lock을 얻기 위한 경쟁에 참여하게 된다. 이것을 경쟁상태라고 한다.
경쟁 상태를 조금 나누어 생각해보자. 예를 들어 A, B 쓰레드가 존재한다고 해보자. A쓰레드는 일을 해야하는데 LOCK을 얻기 위해 기다리고 있었고, B는 그냥 쉬고 있었다. 이 때, A+B가 모두 통지를 받아서 다시 락을 얻기 위해 실행 대기 상태로 간다고 해보자. 이런 경쟁 상태는 지양하는 것이 좋아. 이런 경쟁 상태를 지양하기 위해서는 쓰레드별로 waiting Pool을 따로 만들어서 사용하는 것이 좋을 것이다.
Lock / Condition을 이용한 동기화
원하는 위치에 Lock을 걸고 풀면서 임계영역을 간단히 구현할 수 있다. Synchronzied와 구별되는 것은 Synchronized는 항상 대기하게 만들었는데, Lock은 그것과 조금은 다르다는 것이다.
| Lock 종류 | 동작 |
| ReentrantLock | 재진입이 가능한 락. 가장 일반적인 배타 락 |
| ReentrantReadWriteLock | 동시 읽기 가능, 쓰기에는 배타 락 |
| StampedLock | ReentrantReadWriteLock에 낙관적인 Lock을 추가함 |
ReentrantLock은 재진입이 가능한 락이다. wait / notify처럼 특정 위치에서 락을 풀고 나중에 다시 락을 얻어 임계영역으로 들어와서 이후의 작업을 수행할 수 있다.
ReentrantReadWirteLock은 읽기 / 쓰기 Lock이 나누어 걸린다. 현재 임계영역에 읽기 Lock이 걸려있다면, 다른 쓰레드가 읽기 Lock을 중복으로 걸고 동시에 읽을 수 있다. 읽기는 내용을 변경하지 않기 떄문에 문제가 없다. 그렇지만 읽기 락이 걸린 상태에서 쓰기 락을 걸 수는 없다.
StampedLock은 ReentrantReadWriteLock(읽기 / 쓰기 락) 이외에 낙관적 읽기 락이 추가되었다. 읽기 락이 걸려있는 경우 쓰기 락을 얻기 위해서는 읽기 락이 풀릴 때까지 대기해야한다. 반응성을 좀 더 높이기 위해 먼저 낙관적 읽기 락을 건다. 이 때 쓰기락이 걸리면, 낙관적 읽기 락은 해제되고 쓰기락이 걸린다. 이런 상황에서 다른 쓰레드가 다시 한번 읽어오기 위해 낙관적 읽기 락을 걸려고 한다. 그러면 실패를 한다. 실패가 되면, 읽기 락을 걸고 값을 읽어와야한다.
즉, 쓰레드의 충돌이 거의 발생하지 않을 것이라고 가정해서 여러 쓰레드가 읽어올 수 있게 만들고, 문제가 없으면 그대로 읽는데.. 쓰기가 들어오면 즉시 낙관적 읽기락을 취소하는 것이다.
ReentrantLock
ReentrantLock()
ReentrantLock(boolean fair) // true를 줄 경우, lock이 풀렸을 때 가장 오래된 쓰레드가 락을 획득ReentrantLock은 위와 같이 생성할 수 있다. 매개변수로 True를 주면 가장 오래된 쓰레드가 락을 획득할 수 있도록 한다. 그런데 임계 영역에서 예외가 발생하거나 return 문으로 빠져나가게 되면 락은 계속 특정 쓰레드가 가지고 있다. 따라서 다음과 같이 try / finally 구조로 unlock을 반드시 해제해주어야 한다.
lock.lock()
try{
... //임계 영역
}finally{
lock.unlock // 임계영역 해제
}
ReentrantLock과 Condition
private REentrantLock lock = new ReentrantLock();
// lock으로 condition을 생성
private Condition forCook = lock.newCondition();
private Condition forCust = lock.newCondition();ReentrantLock을 생성하면, 이 객체를 통해 Condition을 만들 수 있다. 이 컨디션은 쓰레드 종류별로 대기할 수 있는 Waiting Pool을 만든 것으로 이해할 수 있다. 따라서 특정 상태의 쓰레드를 특정 Pool에 몰아두고, 필요할 때 그 특정 Pool에만 통지를 주면서 쓸 데 없는 쓰레드간의 경쟁 상태를 막을 수 있다.
forCook.await(); // 현재 쓰레드는 forCook waiting Pool에서 대기한다.
forCook.signal(); // forCook에 있던 쓰레드를 모두 깨운다.쓰레드가 동작할 때, ReentrantLock가 만든 Condition의 await()문을 만나게 되면 해당 객체에서 대기를 하게 된다. 이후, 사용하고 싶다면 동일하게 signal()이란 메서드를 주면 된다.
Lock + Condition, 그리고 경쟁, 기아상태
쓰레드 별로 다른 waiting Pool에서 대기하게 하고, 필요하면 그 특정 쓰레드가 모여있는 Waiting Pool에 signal()을 줘서 다시 실행 대기 상태로 대기할 수 있도록 했다. 이를 통해 쓸모없는 경쟁 상태를 회피할 수 있게 되었다. 그렇지만 한 가지 도전과제가 남는다.
예를 들어 특정 쓰레드끼리의 경쟁상태와 기아 현상이 남아있을 수 있다는 것이다. 정작 필요한 쓰레드가 평생 락을 얻지 못해서 대기를 타고 있는 상황이 있을 수 있다. 이런 부분까지 개선하고자 한다면 좀 더 Condition을 세분화해서 나누면서 해결할 수 있다.
volatile
요즘은 멀티코어가 대세다. 코어는 CPU 하나를 의미하는데(틀리다면 알려주세요!), 각 CPU는 캐시를 하나씩 가진다. CPU는 필요한 값을 메모리에서 읽어올 때 먼저 캐시에 값이 있는지 확인한다. 없으면 메모리에 값을 요청해 캐시에 저장하고, 이후에는 캐시에서 값을 얻어 쓴다. 갑자기 이 얘기를 왜하냐면 멀티 쓰레드 환경에서 문제가 될 수 있기 때문이다.
A 쓰레드를 사용하는 A코어는 1이라는 값을 메모리에 읽어서 캐시에 저장해두었다. 이후에는 1이라는 값을 메모리에서 계속 읽어서 사용한다. 이 때, B코어를 이용하는 B쓰레드는 메모리에 있는 1이라는 값을 2로 수정했다. A 쓰레드는 계속 1이라는 값을 캐시에서 읽어서 쓰기 때문에 메모리에 있던 원래 값이 1 → 2로 바뀐 것을 알지 못하고 잘못된 동작을 한다. 즉, 멀티 쓰레드 환경에서는 메모리와 캐시에 저장된 값의 일치도 중요해진다.
이런 문제를 해결하기 위해 자바에서는 volatile이라는 키워드를 제공한다. 변수 앞에 volatile 키워드를 사용하면, 이 변수는 항상 메모리에서 직접 값을 읽어온다. 따라서 멀티 쓰레드 환경에서 volatile 키워드를 쓰는 것도 고려해볼 수 있다.
volatile과 synchronized → 변수 관점
volatile은 특정 변수를 항상 메모리에서 읽어오는 키워드다. synchronized는 임계영역을 설정해서 락을 획득한 쓰레드만 일을 할 수 있도록 한다. 그런데 synchronized는 쓰레드가 임계영역 블록을 들어갈 때, 캐시와 메모리 간의 동기화가 이루어지기 때문에 변수에 한해서 volatile을 적용한 것과 동일한 효과를 가져온다.
volatile과 synchronized → 원자화 관점
JVM은 데이터를 4바이트 단위로 처리한다. 따라서 int 같은 타입은 하나의 명령어로 읽기, 쓰기가 가능하다. 그렇지만 double, Long 같은 8바이트 타입은 하나의 명령어로 읽고 쓰는 것이 불가능하다. 따라서, 두 개의 명령어를 사용하는데, 두 개의 명령어 사이에 다른 쓰레드가 끼어들 여지가 있다.
synchronized로 임계 영역을 설정하면 이 문제가 해결된다. 그런데 모든 변수에 단순히 이런 문제로 인해 synchronzied를 쓸 수는 없다. volatile을 사용하면 매우 간단히 해결된다. volatile은 이 변수를 원자화 시켜준다. 사실은 두 개의 명령어로 실행 되어야 하지만, volatile을 붙이면서 '작업을 나눌 수 없게' 만드는 것이다.
주의해야할 점은 volatile을 붙이는 것은 변수의 읽기/쓰기를 원자화 할 때만이다. 동기화를 해야할 때는 volatile이 synchronized를 사용할 수 없다. 왜냐하면 volatile은 단순히 읽기/쓰기를 원자화시켜주고 메모리 = 캐시 값을 일치화시켜주는 작업만 하기 때문이다.
https://honbabzone.com/java/java-thread/#%EC%9E%91%EC%97%85%EC%9D%98-%EC%83%9D%EC%84%B1
JAVA 쓰레드란(Thread) ? - JAVA에서 멀티쓰레드 사용하기
JAVA에서 Thread사용하는 방법을 배우고 멀티코어 환경에서 멀티 쓰레드를 사용하는 방법을 알아보겠습니다.
honbabzone.com
'프로그래밍 언어 > JAVA' 카테고리의 다른 글
| Java의 상속 (0) | 2023.01.20 |
|---|---|
| Java Stream과 Stream 활용한 예시 (0) | 2022.02.25 |
| Java : 사용자 정의 어노테이션 만들기 (0) | 2022.02.24 |
| 람다식 (0) | 2022.02.24 |
| 참조 변수, 메모리 간단 정리 (0) | 2021.11.09 |
