파이썬, 세그먼트 트리 구현
- CS/자료구조
- 2021. 9. 21.
세그먼트 트리는 무엇인가?
세그먼트 트리는 완전이진트리를 기반으로 주워진 쿼리에 빠르게 응답하기 위해 만들어진 자료구조입니다. 제가 이 자료구조를 사용해서 문제를 풀었을 때는 대부분 어떤 범위 내에서 어떤 값을 찾아야 할 때 사용을 했는데, 완전탐색을 할 경우 시간초과가 발생하여, O(N^2)에서 O(logn)수준으로 시간복잡도를 줄여야 할 때 주로 사용하게 되었습니다.
세그먼트 트리는 기본적으로 각 노드가 특정 구간에 대한 정보를 가지고 있는 자료구조입니다. 정보는 '특정 구간'내의 어떤 것이든 될 수 있으며, 최소값, 최대값, 구간합, 혹은 최소값의 위치 정보, 정렬 상태 등이 될 수 있습니다.
아래 그림은 세그먼트 트리를 직접 그려본 그림입니다. 노드 위에 있는 N은 'Node'를 뜻하는 알파벳이며 뒤의 숫자는 노드 번호를 나타냅니다. 노드 안에는 범위가 들어있으며, Root Node는 0~7 구간을 의미합니다. 자식 노드들은 해당 구간을 각각 반을 나눠가지게 되며, 재귀적으로 구현되게 됩니다.

위의 내용을 바탕으로 위의 그림으로 보기 좋게 정리해보면 세그먼트 트리 특정 구간의 특정 정보를 가진 완전이진트리라고 정리를 할 수 있겠습니다. 이 세그먼트 트리는 위에서 언급한 것처럼 구간 내의 최소값, 혹은 구간합 같은 것들을 구할 때 완전탐색에 비해 아주 빠르게 찾을 수 있습니다. 단점은 완전탐색에 비해 공간복잡도가 증가한다는 것입니다.
세그먼트 트리의 시간 복잡도는? O(logN)

세그먼트 트리는 한번의 연산을 O(logn)을 요구합니다. 예를 들어 4~7구간에 대한 값을 구한다면 2번의 연산이, 7~7구간에 대한 값을 구한다면 4번의 연산이 필요하게 됩니다. 즉, 연산을 한번 하는데는 최대 세그먼트 트리의 높이만큼의 연산이 필요한 것으로 정리할 수 있습니다.
완전탐색과 비교해보면 굉장히 효율적이란 것을 알 수 있습니다. 예를 들어 0~7번의 합을 구한다고 할 경우, 완전탐색을 할 경우 7번의 연산이 필요한데, 세그먼트 트리 구조에서는 Node 1만 살펴보면 되니 1번의 연산만 필요하게 됩니다.
N의 값이 크면 클수록 세그먼트 트리는 빛이 납니다. 10e9이 샘플로 주어졌을 경우, 세그먼트 트리는 최악의 경우 33번만에 원하는 값을 찾을 수 있습니다. 반면, 완전탐색은 10e9만큼 연산을 진행해야 원하는 값을 도출할 수 있습니다. 즉, 세그먼트 트리를 사용할 경우, 단순히 완전탐색을 하는 것에 비해 많은 시간을 절약할 수 있습니다.
세그먼트 트리의 단점, 공간복잡도

세그먼트 트리를 구성하게 될 경우, 기본적인 완전 탐색을 사용할 때에 비해 더 많은 메모리가 필요하게 됩니다. 위의 이미지에서 볼 수 있듯이, 완전 탐색을 할 경우 총 8개에 대한 할당이 필요한데, 세그먼트 트리를 구성할 때는 총 15개 할당이 필요하기 때문입니다.
물론, 이런 단점을 극복하기 위해 다이나믹 세그먼트 트리 같은 것들이 나와있기는 합니다. 그렇지만 전체를 다 봐야한다고 가정했을 때, 완전탐색보다 더 많은 메모리를 요구할 수 밖에 없습니다.
세그먼트 트리 구현
세그먼트 트리를 구현하는 방법은 Top → Bottom 방식, Bottom → Top 방식이 있습니다. Top → Bottom은 Lazy Propagation 같은 고급 테크닉을 적용할 때, 좀 더 이해하기 쉽지만 재귀 형식으로 구현되기 때문에 Bottom → Top 대비 성능은 떨어진다고 합니다. Bottom → Top은 For문으로 구성되기 때문에 성능이 뛰어나고, 코드 구현이 간편하다고 합니다. 저는 아직 파이썬으로 Bottom → Top을 구현하지 못하기 때문에 제가 할 줄 아는 Top → Bottom 형식으로 구현하겠습니다.
구간 합 세그먼트 트리 초기화
- 가장 먼저 트리의 높이를 구한다.
- 트리의 높이만큼 미리 리스트를 선언한다. 이 때, 리스트에 들어가는 초기값은 세그먼트 트리의 각 노드가 가지는 정보에 따라 다르게 설정 필요함.
- Root Node(Node1)부터 시작해서 자식노드를 하나씩 불러옴.
- Leaf Node에 도달했을 경우, Leaf Node에 단일 구간의 값을 넣은 후 Return.
- 자식 노드들의 합을 더한 값을 현재 Node에 저장하고 Return 함.
#구간합이므로, 각 노드는 '0'으로 초기화 되어있음.
def init(left,right,node) :
if left == right :
tree[node] = my_list[left]
return
else :
mid = (left + right) // 2
init(left,mid,node*2)
init(mid+1, right ,node*2 + 1)
tree[node] = tree[node*2] + tree[node*2 + 1]구간 합 세그먼트 트리 업데이트
특정 위치의 값이 바뀌는 경우가 있습니다. 이럴 때, 트리 업데이트 함수를 구현하여 사용해야 합니다. 이 때, 구간 합 세그먼트 트리를 업데이트 하는데 필요한 시간복잡도는 마찬가지로 O(logn)이 됩니다. 아래의 그림에서는 Index 2에 있는 값을 바꾸는 것을 예시로 들었습니다. Index 2를 업데이트 할 경우, 업데이트 되어야 하는 노드는 10,5,2,1번이 되게 됩니다.

저는 업데이트 함수를 아래 방식으로 구현했습니다.
- 업데이트가 필요한 Index, Value를 입력 받는다.
- 위의 Index가 포함된 노드일 경우, 기존 Index에 있던 값을 빼주고 Leaf Node까지 탐색을 이어간다.
- Leaf Node에 도착하면, Leaf Node에 Value를 업데이트 해주고 Return 한다.
- Return 하면서 자식 노드의 합을 현재 Node에 더해준다.
#left : Node의 왼쪽 구간
#right : Node의 오른쪽 구간
#Node : 현재 Node
#idx : 바꿀 값의 Index
#Value : 바꿀 값
def update(left,right,node,idx, value) :
if left == right == idx :
tree[node] = value
return tree[node]
if idx < left or right < idx :
return 0
else :
mid = (left + right) // 2
update(left , mid, node*2, idx, value)
update(mid+1, right, node*2 + 1, idx, value)
tree[node] = tree[node*2] + tree[node*2 + 1]물론 제가 했던 것처럼 하지 않아도 여러가지 방법은 많습니다. 예를 들어, Leaf Node를 업데이트 한 후, 차이만큼만 각 부모노드에 더해주는 방식으로도 구현이 가능합니다만, 저는 세그먼트 트리의 의미를 더 잘 보여줄 수 있는 방식으로 코드를 짰습니다.
구간 합 세그먼트 트리의 쿼리
쿼리는 쉽게 말해 질문입니다. 어떤 질문이 왔을 때 답을 구하는 행위입니다. 세그먼트 트리에서의 쿼리는 대부분 '범위'가 될 것입니다. 따라서 어떤 범위를 표현할 수 있는 노드만 선택적으로 찾은 후에 필요한 연산을 수행하면 됩니다.
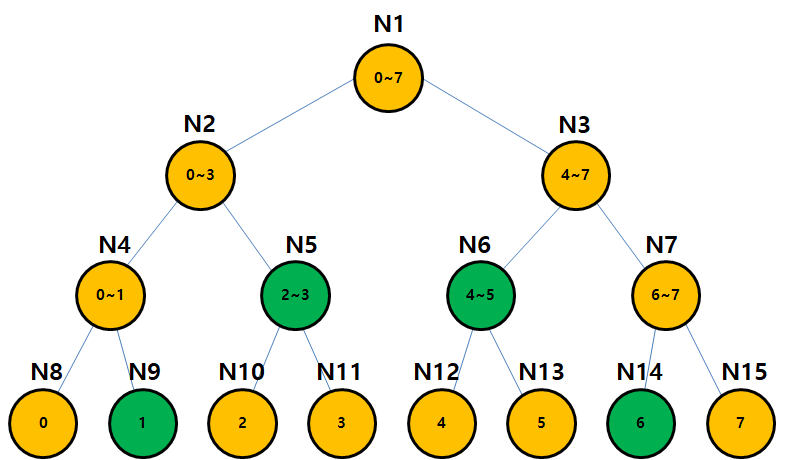
예를 들어, 1~6 구간 합을 구한다고 가정을 해봅시다. 위의 그림에서 쉽게 어떤 노드를 찾아야 하는지 알 수 있습니다. Node 9 + Node 5 + Node 6 + Node 14를 할 경우 1~6 구간 합을 구할 수 있습니다.

2~5 구간 합을 구할 경우에는 Node 5 + Node 6을 하면 됩니다.
위 그림들을 보며 대략적인 개념을 이제 이해하셨을 것으로 생각합니다. 그렇다면 실제로 구현해보는 일만 남아있는데요, 우리가 구현을 하기 전에 해야할 것은 경계조건을 명확하게 하고 가는 것입니다. 구간을 설명하기 전에 편의상 먼저 변수가 어떤 의미를 가지는지 설정하고 가겠습니다.
- Left,Right,Node : Node는 Left, Right 정보를 가지며 Left, Right는 해당 노드가 어떤 범위의 값을 가지고 있는지 나타낸다.
- lidx,ridx : 이 변수는 구하고자 하는 구간을 나타내는 값이다. 재귀를 하는 동안 변하지 않아야 하는 값.
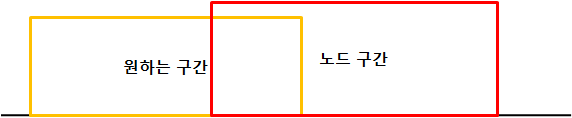
만나지 않는 구간일 때 (의미없는 구간)

위의 이미지처럼 현재 노드가 나타내는 구간과 원하는 구간이 전혀 만나지 않는 경우가 있습니다. 이 경우는 전혀 살펴볼 필요가 없습니다. 따라서 이 조건을 만족할 경우, 아무 연산도 하지 않고 Return을 해야합니다.
if right < lidx or ridx < left :
return노드 구간이 원하는 구간에 포함될 때 (주요 연산 실행)

위의 이미지처럼 원하는 구간 안에 노드 구간이 포함되는 경우가 있습니다. 이 경우에도 자식 노드를 살펴볼 필요가 없습니다. 자식 노드를 더 살펴보면 아래의 이미지처럼 되는데, 보시다시피 현재 상태의 정보로 필요한 정보를 다 얻을 수 있습니다.

즉, 노드 구간이 원하는 구간에 포함될 때는 여기서 재귀를 멈추고 필요한 연산만 하고 Return을 하면 됩니다. 구간합을 구하기 때문에 저는 Global 변수 Answer에 현재 노드에 저장된 값을 Return하는 식으로 코드를 작성했습니다.
if lidx <= left and right <= ridx :
answer += tree[node]
return위의 케이스를 제외한 노드 구간과 원하는 구간이 겹칠 때 (자식 노드로 재귀)
위의 이미지처럼 원하는 구간과 노드 구간이 애매하게 겹치는 경우가 있습니다. 이 경우는 값이 특정되지 않았기 때문에 자식노드를 살펴봐야하고, 현 노드에 기록된 값을 사용하지 않습니다. 즉, 아래의 코드에서 볼 수 있듯이 재귀를 태워주는 용도로 사용하면 됩니다.
if lidx <= right or left <= ridx :
mid = (left + right) // 2
query(left,mid,node*2, lidx,ridx)
query(mid+1, right, node*2 +1 , lidx, ridx)
return
위의 경우를 종합해서 확인하면 다음과 같이 Query 함수를 구현할 수 있습니다.
def query(left,right,node,lidx,ridx) :
global answer
if ridx < left or right < lidx :
return
elif lidx <= left and right <= ridx :
answer += tree[node]
return
elif lidx <= right or left <= ridx :
mid = (left + right) // 2
query(left,mid,node*2, lidx,ridx)
query(mid+1, right, node*2 +1 , lidx, ridx)
return
세그먼트 트리, 변수의 의미
import math
h_tree = 2 ** math.ceil(math.log2(n) + 1)h_tree는 n개의 입력이 들어왔을 때, 세그먼트 트리를 구성하는데 필요한 전체 노드 개수를 의미한다. 예를 들어 5개의 입력이 있다고 가정하면, 리프 노드는 8개가 될 것이고, 리프 노드 8개인 세그먼트 트리의 필요 노드 갯수는 16개가 된다. 즉, 리프 노드만큼 리프노드 위로 노드가 존재한다.
def query(tree, node, left, right, start, end) :
pass
query(tree, node, 0, (h_tree//2)-1 , 0, (h_tree//2)-1)위의 query의 의미는 전 구간에 대한 합을 구하겠다는 의미다. 세그먼트 트리의 의미를 정확하게 하려면 각 노드를 표현할 때, right 영역에 h_tree // 2로 표현을 해주어야 한다. 완전이진탐색 트리를 만드는건데, 이 경우 입력이 5개라고 하더라도 리프노드는 8개가 되기 때문이다. 노드 구성 관점에서 본다면 루트노드는 0~7의 모든 정보를 가져야 하기 때문에 h_tree//2 - 1로 표현이 되어야 한다.
세그먼트 트리, 반복문으로 업데이트 하기.
def update(tree, node, start) :
node += start
while node :
tree[node] +=1
node //= 2 :
return위 코드는 세그먼트 트리를 반복문으로 업데이트 할 때 사용되는 코드다. 반복문을 사용하는 이유는 실행속도를 빠르게 하기 위함이다. 재귀를 여러번 부를 경우보다, 간단한 업데이트라면 반복문으로 업데이트를 빠르게 해버리는게 실행속도 관점에서는 빠르다.
Node는 특정 Index를 이야기 한다. 예를 들어 7개의 값으로 세그먼트 트리를 구성했다고 하면, 리프 노드 8개, 나머지 노드 8개로 구성이 될 것이다. 여기서 Start는 나머지 노드 8개를 뜻한다. Node는 바꾸고자 하는 구간을 그대로 넣으면 된다. 예를 들어 7개의 값 중 0번째에 있는 값을 바꾼다고 가정한다면, 이 값의 세그먼트 트리에서의 위치는 Start + 0으로 표현할 수 있다. 좀 더, 특정해서 이야기 하면 8 + 0이 이 값의 세그먼트 트리가 가지는 값이다.
세그먼트 트리, Query 시 시간 복잡도 감소 시키기.
query(tree, 1, 0, h_tree//2 - 1, 시작지점, h_tree//2 - 1)
이건 미세팁이다. 백준의 북서풍 같은 문제를 풀다보면, 굉장히 시간이 쪼들리는 문제가 있다. 특히 북서풍 문제는 현재 지점보다 크거나 같은 지점의 누적합을 구하는 문제다. 이 경우, 굳이 구간을 정확하게 쪼갤 필요가 없다. 예를 들어 100개의 노드로 세그먼트 트리를 만들었다고 가정해보자. 이 때, 세그먼트 트리의 전체 노드는 256개가 될 것이다.
이 때, 정말 재수없게도 쿼리가 들어온 영역이 63보다 크거나 같은 지점의 합을 구해야 한다는 쿼리가 있다고 가정해보자. 그렇다면 이 때, 정직하게 63 ~ 100의 값을 구할 필요가 없다. 아마 63~64를 기점으로 2등분이 될 것이기 때문에 63과 100은 정말 정말 멀리 떨어져있는 노드다. 이 경우, 63까지 한번 훑은 후에 64~100을 살펴보는 노드까지 다시 한번 탐색을 해야한다.
그렇지만 이 문제의 특성을 이해한다면 63 ~ 100까지 보는 것이나, 63 ~ 128까지 보는 것이나 결과는 똑같이 나온다. 과정은 63~128까지 보는 것이 훨씬 감소된다. 왜냐하면 63 ~ 128은 1번의 탐색만으로 바로 찾아지기 때문이다.
'CS > 자료구조' 카테고리의 다른 글
| 정렬 알고리즘 정리 (0) | 2021.10.03 |
|---|---|
| Heap 구조 및 파이썬 구현 (0) | 2021.09.30 |
| 테이블과 해시 함수 (0) | 2021.09.26 |
| 세그먼트 트리의 Lazy Propagation + 파이썬 구현 (0) | 2021.09.22 |
| Trie(트라이) 자료구조 파이썬 (0) | 2021.09.21 |