들어가기 전
이 글은 쿠버네티스 인 액션 11장을 공부하며 작성한 글입니다.
11.1 아키텍쳐 이해
쿠버네티스는 전체적으로 다음 요소들로 구성되어있다. 유기적으로 아래 요소들이 협력하면서 쿠버네티스가 잘 운영될 수 있도록 해준다.
- 컨트롤 플레인
- etcd : 분산 저장 스토리지
- API 서버
- 스케쥴러
- 컨트롤러 매니저
- 워커 노드
- kubelet
- kube-proxy
- 컨테이너 런타임
- 애드온
- 쿠버네티스 DNS 서버
- 대시보드
- Ingress Controller
- 힙스터
- CNI (Container Network Interface)
11.1.1 쿠버네티스 구성 요소의 분산 특성
앞에서 이야기 했던 모든 구성요소는 개별적인 프로세스로 동작한다. 그리고 각 구성요소들의 의존성은 다음과 같이 구성된다.

그림에서 볼 수 있듯이, 쿠버네티스의 각 컴포넌트의 통신은 단순 명료하다. 이런 통신 구조를 가지기 때문에 쿠버네티스의 각 컴포넌트끼리는 느슨한 결합을 유지할 수 있다.
- etcd를 제외한 모든 컴포넌트는 API Server하고만 통신한다.
- etcd는 API Server 하고만 통신한다.
개별 구성 요소의 여러 인스턴스 실행
쿠버네티스는 클라우드를 이룬다. 이 말은 마스터 노드 / 워커 노드가 여러 개 존재할 수 있다는 것을 의미한다. 그렇다면 마스터 노드 / 워커 노드가 여러 개 생성 되어 있을 때 쿠버네티스의 각 구성요소는 어떻게 동작할까? 아래의 그림을 살펴보자.

마스터 노드 / 워커 노드가 여러 개 존재하더라도 각 쿠버네티스 노드는 그에 대응되는 쿠버네티스 컴포넌트를 가지고 있다. 위 그림에서 파란색은 분산 처리가 가능한 녀석들이고, 노란색으로 표시된 녀석들은 분산으로 동작하지는 않는 녀석들이다.
컨트롤 플레인의 구성 요소들만 대표적으로 어떻게 동작하는지 정리하면 다음과 같다.
- etcd : 분산 저장 스토리지임. RAFT 알고리즘으로 합의된 상태가 각각의 etcd에 저장되어있음. 따라서 어떤 etcd를 조회해도 무관함.
- API Server : API Server는 stateless함. 따라서 아무 API Server나 찔러도 됨.
- Schedule + Controller Manager : 각 노드에 생성은 되어있음. 실제로는 하나의 인스턴스만 활성화. 나머지는 대기상태
구성요소의 실행 방법
각 구성요소의 실행 방법을 살펴보면 다음과 같다.
- Control Plane
- 파드 : etcd / Api Server / Controller-Manager / Scheduler
- Worker Node
- 파드 : Kube Proxy
- 데몬 프로세스 : kubelet / Container Runtime(Docker)
# 마스터노드
NAMESPACE NAME NODE
kube-system etcd-ubuntu-master ubuntu-master
kube-system kube-apiserver-ubuntu-master ubuntu-master
kube-system kube-controller-manager-ubuntu-master ubuntu-master
kube-system kube-proxy-lnjnf ubuntu-master
kube-system kube-scheduler-ubuntu-master ubuntu-master
# 워커 노드
NAMESPACE NAME NODE
kube-system coredns-5d78c9869d-2zqm7 ubuntu-worker1
kube-system kube-proxy-wrkcf ubuntu-worker111.1.2 쿠버네티스가 etcd를 사용하는 방법
쿠버네티스에 배포된 모든 객체(Pod, Deploy 등등)는 매니페스트 파일로 저장된다. 쿠버네티스는 이 매니페스트 파일을 etcd에 저장해둔다. 그리고 쿠버네티스는 etcd에 저장된 매니페스트의 상태(Desired)와 동일하게 클러스터를 유지하려고 한다.
쿠버네티스는 API Server를 통해서만 etcd에 CRUD를 한다. 이 구조를 통해서 쿠버네티스는 다음의 장점을 얻을 수 있다.
- 낙관적 락
- 유효성 검사
API Server를 통해서만 etcd에 접근할 수 있기 때문에 매니페스트 파일을 접근하려고 할 때, 유효한 매니페스트 파일인지 API Server가 검사해준다. 또한 여러 API Server가 동시에 매니페스트 파일을 업데이트 하려고 할 때, "버전"으로 관리되는 낙관적 락을 통해서 Race Condition을 해결하도록 동작할 수 있다.
낙관적 락을 이용해서 etcd를 업데이트 할 때는 다음과 같이 동작한다.
- API Server가 etcd에게 매니페스트의 버전을 요청한다.
- API Server가 업데이트 한 후에, etcd에 매니페스트 파일 업데이트를 요청한다. 이 때, 이전 버전 + 1의 값이 저장된다.
- 만약 버전 값이 1만큼 증가하지 않았으면, 문제가 있는 것으로 판단되어 업데이트가 거절된다.
- 이렇게 실패한다면, API Server는 다시 한번 매니페스트의 버전을 요청한다. 최신화된 데이터를 읽어서 다시 한번 etcd에 업데이트 요청을 한다.
쿠버네티스에서 리소스를 etcd에 저장하는 방법
쿠버네티스에 배포된 리소스는 모드 etcd에 저장된다. 쿠버네티스는 기본적으로 etcd의 /registry 아래에 key / value 형식으로 리소스를 저장한다. 예를 들어 아래 명령어를 이용해서 /registry 폴더 아래에 저장된 모든 Key / Value 데이터들에 대해서 Key의 값만 불러올 수 있도록 할 수 있다.
// etcd에 저장된 쿠버네티스 매니페스트의 key값 살펴보기
$ etcdctl get /registry --prefix --keys-only
...
/registry/endpointslices/kube-system/kube-dns-jsrnd
/registry/endpointslices/kube-system/metrics-server-dcmvn
/registry/endpointslices/longhorn-system/csi-attacher-x8vs8
/registry/endpointslices/longhorn-system/csi-provisioner-dj5nl
// key 값으로 조회하기
$ kubectl get --raw /api/v1/namespaces/default/pods/my-pod
// alias 추가해서 손쉽게 접근하기.
alias etcdctl='ETCDCTL_API=3 etcdctl \
--endpoints=https://192.168.0.200:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key'etcd에 저장된 값은 프로토버프로 저장되기 때문에 바로 읽을 수는 없다고 한다. 따라서 대부분 깨진 값으로 나올 것이다. Value의 값을 살펴보고 싶다면 kubectl의 --raw 옵션을 이용해서 Key로 검색하면 etcd에 저장된 value 값을 읽을 수 있다.
쿠버네티스에서 저장된 오브젝트의 일관성 / 유효성 보장
여러 마스터 노드가 존재하고, 각 마스터 노드의 API Server들이 동시에 etcd를 업데이트 하는 경우를 고려해보자. 이 경우, 어떻게 데이터의 '일관성'이 보장되는 것일까?
- API Server는 etcd로부터 낙관적 락을 획득해서 업데이트 한다.
API Server는 업데이트 하고자 하는 오브젝트의 버전을 얻어온다. 그리고 업데이트를 할 때 버전을 하나 올려서 업데이트 한다. 이 때 API Server가 전달한 버전이 etcd가 기대하던 값이 아닌 경우에 API Server는 다시 한번 etcd에게 데이터를 받아와서 최신 값으로 업데이트 한다. 이런 식으로 낙관적 락이 구성되어 있기 때문에 여러 API Server가 업데이트 하는 경우, etcd는 데이터의 '일관성'을 유지하도록 동작한다.
그렇다면 여러 etcd가 존재하는 경우, etcd 클러스터의 각 인스턴스는 어떻게 데이터 일관성을 유지할까? etcd 클러스터의 데이터 일관성은 다음을 통해서 유지된다.
- 분산 시스템은 실제 상태가 무엇인지 합의(Consensus)에 도달해야 함.
- etcd는 RAFT 알고리즘을 이용해 과반수 이상의 노드가 동의하는 상태 (현재 상태, 이전에 동의된 상태)를 보장함.
전체 노드의 과반수 이상이 '이 상태가 맞아!'라고 동의할 때만 해당 상태가 Valid 하다는 것으로 판단한 후, 일관성을 보장해주는 방식이 된다. 이 때 과반수 이상은 50%가 아닌 51%를 의미한다.

각각의 경우를 고려해보자.
- etcd 1~3이 같은 상태를 가질 때
- 이 녀석들은 과반수 이상이기 때문에 합의(Consensu)를 이룸.
- 따라서 해당 etcd 인스턴스로 오는 업데이트 요청을 수행할 수 있는 상태가 된다.
- etcd 1~2 / etcd 3이 다른 상태를 가질 때
- etcd3이 네트워크 단절이 발생했을 때 etcd1~2에 업데이트가 발생한 경우.
- etcd3는 과반수 이하 상태이기 때문에 업데이트 요청이 와도 업데이트 불가능.
- etcd1~2는 과반수 이상이기 때문에 업데이트 요청이 오면 업데이트 가능.
이런 방식으로 etcd 클러스터는 클러스터 전체의 데이터 일관성을 유지한다.
etcd 인스턴스가 홀수로 배포되는 이유
etcd 인스턴스는 일반적으로 홀수를 배포한다. 이유를 정리해보면 다음과 같다.
- etcd는 RAFT 알고리즘으로 etcd 클러스터의 컨센서스를 이룬다.
- etcd는 과반수가 동의하는 리더를 선출한다.
- 쓰기는 리더를 통해서만 처리되고, 읽기는 리더가 아닌 노드로도 처리 가능하다.
- 리더에게 쓰기 요청이 오면, 리더는 각 구성원에게 합의를 요청한다. 합의는 'N/2 + 1'의 노드가 응답하는 경우에 이루어진다.
- 합의가 이루어지면, 리더는 쓰기 결과를 반환한다.
예를 들어 각각 3 / 4개의 노드로 구성된 클러스터가 있다고 가정해보자. 이 때, 각 클러스터는 몇개의 노드까지 실패할 수 있을까?
- 3개 클러스터 : 2개의 노드 합의가 필요함. 즉, 1개까지 실패 가능.
- 4개 클러스터 : 3개의 노드 합의가 필요함. 즉, 1개까지 실패 가능.
즉, 홀수 / 짝수 클러스터를 비교했을 때 짝수 클러스터는 '내결함성' 관점에서는 홀수 클러스터에 비해서 전혀 이점이 없다는 것이다. 오히려 1개 더 많은 노드에도 데이터를 복사해야하기 때문에 '네트워크 비용'이 짝수 클러스터는 더 많이 나온다.
정리하면 다음과 같다.
- 홀수 클러스터 / 짝수 클러스터의 내결함성 관점에서의 효과는 동일함. (1개까지만 실패할 수 있음)
- 짝수 클러스터의 네트워크 비용이 더 많이 발생함.
- 대규모 etcd 클러스터에서는 5 or 7대의 etcd만 배포하도록 한다.
11.1.3 API 서버의 기능
쿠버네티스의 API 서버는 다음 기능을 수행한다. (https://kubernetes.io/ko/docs/concepts/security/controlling-access/)
- CRUD 제공.
- 상태를 etcd에 저장. 이 때 낙관적 락 처리.
- 인증 / 인가 / 어드미션 컨트롤러
쿠버네티스 API는 kubectl을 통해서 HTTP POST 요청을 받는다. POST 요청은 API 서버에서 인증 → 인가 → 어드미션 컨트롤러를 통과하게 되고, 최종적으로 리소스 유효성 검사 후에 적합하다면 etcd에 저장된다.

인증 플러그인으로 클라이언트 인증
API 서버는 요청을 보낸 클라이언트를 인증해야한다. API 서버는 요청을 보낸 사람이 누구인지 명확하게 알 수 있을 때까지 인증 플러그인을 차례대로 호출한다. (https://kubernetes.io/docs/reference/access-authn-authz/authentication/)
인가 플러그인을 통한 클라이언트 인가
사용자가 인증되었으면, 사용자가 이 요청을 할 자격이 있는지 인가 플러그인을 통해 결정한다. 자격이 있는지 확인할 수 있을 때까지 인가 플러그인을 차례대로 호출한다. (https://kubernetes.io/ko/docs/reference/access-authn-authz/authorization/)
어드미션 컨트롤 플러그인으로 요청된 리소스 확인과 수정
리소스 조회 요청은 어드미션 컨트롤 플러그인에 전달되지 않는다. 리소스 수정 / 삭제 / 생성 요청은 어드미션 컨트롤 플로그인에게 전달된다. 어드미션 컨트롤 플러그인은 리소스에 대한 기본 값을 셋팅해준다. 예를 들어 Pod를 하나 만들 때, 컨테이너 이미지만 설정해도 파드가 정상적으로 만들어지는 것이 '어드미션 컨트롤 플러그인'이 필요한 기본값을 셋팅해주기 때문이다.
어드미션 컨트롤 플러그인의 예시는 다음과 같고, 더 많은 예시는 이곳(https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/)에서 확인할 수 있다.
- AlwaysPullImages : 파드의 ImagePullPolicy를 Always로 변경함.
- ServiceAccount : 명시적으로 지정하지 않을 경우, default 서비스 어카운트를 사용함.
- NamespaceLifecycle : 삭제되는 과정에 있는 네임스페이스 / 존재하지 않은 네임스페이스에 파드 생성 방지함.
- ResourceQuota : 네임스페이스에 할당된 CPU + 메모리만 사용하도록 강제함.
리소스 유효성 확인 및 영구 저장
요청이 모든 어드미션 컨트롤러를 통과하면, API 서버는 리소스의 유효성 검사를 진행한다. 유효성 검사에 통과하면, API Server는 해당 리소스를 etcd에 저장한다.
11.1.4 API 서버가 리소스 변경을 클라이언트에 통보하는 방법 이해
API 서버가 제공하는 기능은 다음과 같다.
- 리소스의 CRUD를 제공함.
- 리소스의 상태는 etcd에 저장함.
- 클라이언트 요청 시, 리소스의 변경사항을 제공함.
API 서버가 쿠버네티스 리소스의 '선언 상태'를 유지하는데 실제로 일하는 것은 없다. 쿠버네티스의 선언 상태 유지는 다음 형태로 이루어지게 된다. REST API 서버는 정보를 제공하고, 실제로 상태를 유지하는 것은 Kubelet, Controller Manager, Scheduler 등이 하게 된다.
- 쿠버네티스 구성요소가 API 서버를 Watch한다.
- API 서버를 통해서만 etcd의 리소스가 변경된다.
- API 서버는 리소스가 변경되면, API 서버를 Watch하고 있는 구성요소에게 변경사항을 전달한다.
- 변경사항을 받은 쿠버네티스 구성요소(Controller Manager / Scheduler 등)가 '선언 상태'를 유지한다.

쿠버네티스 리소스를 관리하기 위해서 각 클라이언트 (스케쥴러 / Kubelet / 컨트롤러 매니저)는 HTTP 커넥션을 맺고 변경 사항을 감지한다. API 서버가 etcd에게 변경 사항을 통보받으면, API Server는 맺어진 HTTP 커넥션의 스트림을 이용해 변경 사항을 각 클라이언트에게 전달한다. 변경 사항을 통보받은 클라이언트들은 각자 맡은 임무를 진행한다.
11.1.5 스케쥴러 이해
파드 생성 요청을 했을 때, 파드가 생성될 노드를 정하는 것은 일반적으로 '스케쥴러'가 한다. (예외의 경우는 Affinitiy와 관련있음). 스케쥴러는 다음과 같이 동작한다.
- 스케쥴러는 API 서버를 Watch한다. 새로운 Pod가 생성되어야 한다는 사실을 API 서버로부터 통지받는다.
- 스케쥴러는 자신의 알고리즘을 통해 생성될 노드를 설정한다. 그리고 API 서버에게 HTTP 요청을 보내서 etcd에 저장된 파드의 매니페스트 파일을 업데이트 한다. 이 때, 파드의 매니페스트 파일에는 '어떤 노드에 생성될지'가 업데이트 된다.
- 파드의 매니페스트 파일이 업데이트 되었으므로 API 서버는 변경 사항을 etcd로부터 통지받는다. 변경사항을 Watch하고 있는 클라이언트에게 전달한다.
- 각 노드의 kubelet은 API 서버를 watch하다가 자신의 노드에 스케쥴링된 파드 매니페스트를 확인하면 파드의 컨테이너를 생성하고, API 서버에게 알려준다.
여기서 중요한 점은 스케쥴러는 파드가 어떤 노드에 생성되어야 할지 결정만 하고, 실제로 노드에 파드를 생성하는 것은 각 노드의 kubelet이 한다는 점이다.
기본 스케줄링 알고리즘 이해
기본 노드 스케쥴링은 다음 순서로 진행된다.
- 파드가 배치 가능한 노드 목록을 필터링한다.
- 파드를 수용 가능한 노드의 우선순위를 정하고, 점수가 높은 파드를 선택한다. 같은 점수를 가진다면 파드가 노드에 골고루 분배되도록 Round Robin으로 분배한다.
아래 그림을 보면 명확히 이해할 수 있다.

수용 가능한 노드 찾기
파드가 새로 생성되었을 때, 스케쥴러는 파드를 수용가능한 노드를 찾기 위해서 미리 설정된 조건 함수(Predicate Function) 목록에 각 노드를 전달한다. 조건 함수의 예시는 다음과 같다.
- 노드가 파드의 하드웨어 리소스 요청을 만족할 수 있는가?
- 노드에 리소스가 부족한가?
이런 내용들의 조건 함수를 이용해서 가능한 노드만 먼저 선별한다. 이 뿐만 아니라 Affinity / Node Selector 등과 관련된 조건함수들이 존재한다. 스케쥴러는 모든 노드에 대해서 조건 함수를 실행해야 노드 필터링이 완료된다.
파드에 가장 적합한 노드 선택
노드 필터링을 한 후에, 스케쥴러는 각 노드에 대한 우선순위 점수를 매긴다. 그리고 우선순위가 높은 노드에게 파드를 먼저 분배한다. 예를 들어 두 개의 노드만 남았고 같은 점수를 가질 때, 각 노드에 10개 / 2개의 파드가 기동중이라고 가정해보자. 그러면 새롭게 생성되는 파드는 2개의 파드가 있는 노드에 분배되는 것이 더 효율적일 것이다.
고급 파드 스케쥴링
Deployment / StatefulSet을 이용해서 여러 Pod가 생성되었다고 가정해보자. 만약 Pod가 특정 노드에 몰려서 생성되었다면, Node Failure가 발생했을 때 서비스 장애를 경험할 가능성이 커진다. 반면, Pod가 모든 노드에 골고루 생성되었다면 몇 개의 노드가 실패하더라도 여전히 서비스를 이용할 수 있다.
고급 파드 스케쥴링은 이처럼 파드가 전체 노드에 골고루 분산되어서 배포될 수 있도록 해준다. 예를 들어 Anti Affinity + Node Affinity 등을 이용할 수 있다. 이것은 16장에서 공부한다.
다중 스케줄러 사용
일반적으로는 하나의 클러스터에서 Default 스케쥴러 하나만 동작한다. 하지만 이렇게 동작시킬 수 있다.
- 클러스터에 여러 스케쥴러를 동작시킨다.
- 파드를 정의할 때 schedulerName 속성이 있는데, 이것은 파드 스케쥴링에 사용할 스케쥴러를 정하는 것이다. 이 값을 정의하지 않으면 default 스케쥴러를 사용해 파드가 정의된다. 이 때, Default 스케쥴러 말고 다른 스케쥴러를 사용해 배정할 수도 있다.
11.1.6 컨트롤러 매니저에서 실행되는 컨트롤러 소개
사용자들은 Deployment, Statefulset 같은 오브젝트에 원하는 상태(Desired State)를 선언했다. 그렇다면 누군가는 이 선언 상태를 만족시키기 위해 동작해야한다. 선언 상태를 달성하기 위해서 동작하는 녀석들을 Controller라고 한다. Controller는 Controller Manager 내부에서 동작한다. 다음과 같이 정리할 수 있다.
- Resource : 클러스터에 필요한 상태를 선언함.
- Controller : 선언된 상태를 달성하도록 작업 수행함.
컨트롤러의 역할과 동작 방식 이해
컨트롤러는 다음과 같이 동작한다.
- 컨트롤러는 API 서버를 Watch한다. 변경점이 발생하면 이를 Watch하고 있다가 필요한 작업을 수행한다.
- 컨트롤러는 조정 루프를 실행해, 실제 상태를 원하는 상태로 조정하고 새로운 상태를 리소스의 Status 섹션에 기록함.
- 컨트롤러끼리 통신하지 않는다. 컨트롤러는 API 서버를 통해 이벤트를 확인하고, 원하는 상태를 업데이트 한다. 그리고 다른 컨트롤러가 API 서버를 감시하다가 다음 작업을 수행하는 방식의 체이닝이 이루어진다.
컨트롤러와 관련된 코드는 이곳에 있다.
https://github.com/kubernetes/kubernetes/blob/master/pkg/controller
- 컨트롤러에는 Informer가 있다. Informer는 API 오브젝트가 변경된 내용을 받을 때 마다 호출되는 리스너다. Informer는 특정 리소스가 변하는지를 계속 감시한다.
- 컨트롤러에는 worker() 메서드가 존재한다. 컨트롤러가 무슨 일을 해야할 때, worker() 메서드가 호출된다. 실제 기능은 syncHandler나 이와 비슷한 필드에 저장됨.
Replication Manager
ReplicationController 자원을 활성화 해주는 Controller가 Replication Manager다. 이 녀석은 다음과 같은 방식으로 동작한다.
- Replication Manager는 무한 루프를 돌며, 파드 셀렉터와 일치하는 파드의 수를 찾고 원하는 Replicas와 비교한다.
- Replication Manager는 매 루프마다 모든 파드 정보를 가져오지는 않는다. 대신 감시 메카니즘을 이용해 Replicas와 파드 수에 영향을 주는 변화만 선택적으로 수신 받는다.
- 만약 Replicas와 파드 수가 다르다면, API 서버에게 파드를 생성 / 삭제 요청을 한다.
예를 들면 아래 그림처럼 볼 수 있다. 아래 그림에서 Controller Manager에 포함된 Replication Manager는 API 서버의 Replication Controller / Pod 리소스만 감시한다. 만약 여기서 유의미한 변화가 있다면, Replication Manager는 의도된 상태를 맞추기 위해 API 서버에게 Pod 리소스의 변화를 요청할 것이다.
예를 들어 Pod 생성을 요청했다면, 매니페스트 파일이 etcd에 저장되고 실제로 Pod가 생성되는 것은 아니다. 그 다음 일은 또 다른 인스턴스가 맡아서 하게 된다. 쿠버네티스의 컨트롤러 매니저는 이런 형태로 유기적으로 협력하며 동작한다.
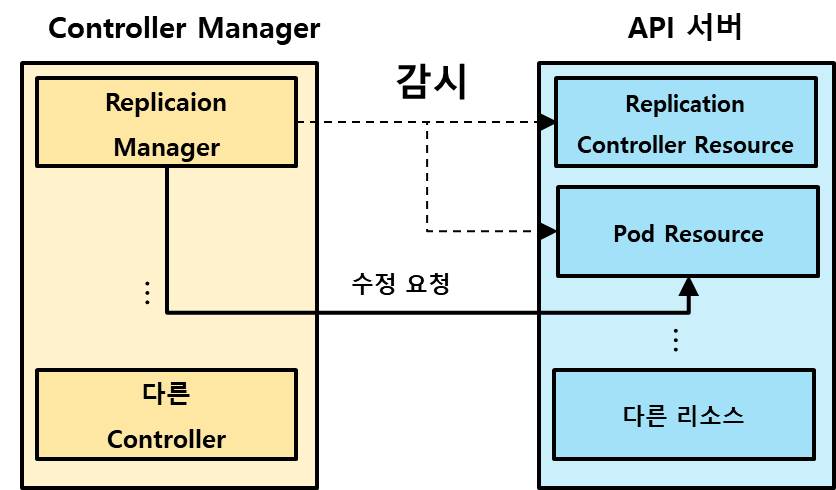
다른 컨트롤러들
- RecpliaSet / DaemonSet / Job Controller : 각 리소스에 정의된 Pod Template에서 파드 리소스를 생성한다. 생성한 파드 정의를 API 서버에 게시한다.
- Deployment Controller : Deployment의 오브젝트가 수정될 때 마다 새로운 버전으로 Rollout 한다. ReplicaSet 생성 요청을 게시한다.
- Statefulset Controller : Statefulset 리소스 정의에 따라 파드의 생성 / 관리 / 삭제 수행함. 또한 PVC도 인스턴스화 및 관리함.
- Node Controller : 각 노드의 상태를 모니터링하고 연결이 끊어진 노드에서 파드를 제거한다.
- Service Controller : 로드밸런서 유형의 서비스 생성 / 삭제 시 METAL LB 같은 곳에 로드 밸런서를 요청하고 해제하는 역할을 함.
- Endpoint Controller : 라벨 셀렉터와 일치하는 파드의 IP / 포트로 엔드포인트 리스트를 계속 갱신함. 이 녀석은 Service + Pod를 모두 감시함. 엔드포인트 리소스는 엔드포인트 컨트롤러가 직접 생성 / 삭제함.
- 네임스페이스 컨트롤러 : 네임스페이스 리소스가 삭제되면, 네임 스페이스에 존재하던 모든 리소스도 같이 삭제되는데 이게 네임스페이스 컨트롤러가 함.
- PV 컨트롤러 : PVC를 감시하고 있다가, 컨트롤러는 요청한 접근 모드와 일치하는 PV를 찾아서 매칭한다.
컨트롤러 정리
모든 컨트롤러는 API 서버로 API 오브젝트를 제어한다. 어떤 컨트롤러도 kubelet과 직접 통신하거나 명령하지 않는다.
11.1.7 Kubelet이 하는일
Kubelet은 워커 노드에 데몬 프로세스 형태로 실행된다. 이 Kubelet은 정확히 무슨 역할을 하는 것일까? Kubelet은 워커 노드에서 발생하는 모든 일을 처리해준다. Kubelet 역시 API 서버를 Watch한다는 것을 기억하자.
- Kubelet은 워커 노드를 Node 리소스(쿠버네티스 리소스)로 만들어 API 서버에 등록한다. (etcd에 등록됨)
- Kubelet은 API 서버를 Watch함. 노드에 파드가 스케쥴링 되면 컨테이너 런타임을 이용해 파드를 생성함.
- Kubelet은 파드의 상태, 이벤트, 리소스 사용량을 API 서버에게 보냄.
11.1.8 쿠버네티스 서비스 프록시의 역할
쿠버네티스의 모든 노드에는 kube-proxy가 DaemonSet으로 설치된다. Kube-Proxy는 쿠버네티스 서비스와 파드를 연결해주는 목적으로 사용된다. Kube-Proxy는 Userspace와 Iptables 모드가 존재하는데, 동작 방식은 조금씩 다르나 서비스와 파드를 연결해준다는 동작은 변함없다. 각 모드의 동작 방식은 다음과 같다.
- UserSpace : 리눅스 Iptable을 조작해, 각 노드의 서비스 IP로 들어오는 트래픽을 모드 Kube-Proxy로 전달하도록 함. Kube-proxy는 트래픽을 받아 각 파드로 라운드 로빈 방식으로 뿌려줌.
- IpTables : Kube-Proxy는 API 서버를 Watch함. Service에 대한 Endpoint가 업데이트 되면, 각 Service + Port로 들어온 요청을 각 Endpoint로 뿌려주도록 리눅스 Iptable을 매번 업데이트 함. 이 때, 파드는 무작위로 뿌려짐.
- 자세한 내용은 이곳에 정리했음. (https://ojt90902.tistory.com/1523)
UserSpace는 네트워크 홉을 한번 더 타야하기 때문에 성능적으로 문제가 있지만 라운드 로빈 형식으로 균등하게 트래픽을 뿌려준다. 그렇지만 최근에는 네트워크 홉을 적게 다는 Iptables 모드가 kube-proxy의 기본 모드로 동작한다.
11.1.9 쿠버네티스 애드온 소개
쿠버네티스 컴포넌트 (스케쥴러 / 컨트롤러 매니저 등)은 쿠버네티스의 핵심 요소로 동작한다. 쿠버네티스에서는 '애드온'을 설치해서 더 많은 기능을 제공해준다. 대략적으로 다음 기능을 제공해준다.
- 쿠버네티스의 대시보드 제공
- 쿠버네티스 서비스의 DNS 조회
- 여러 HTTP 서비스의 단윌 외부 IP 주소로 노출
아래에서 하나씩 살펴보려고 한다.
DNS 서버 동작 방식
- 클러스터의 모든 파드는 기본적으로 클러스터 내부 DNS 서버를 사용하도록 설정됨.
- DNS 서버는 kube-dns 서비스로 노출됨.
- kube-dns 서비스의 IP 주소는 클러스터에 배포된 모든 파드 컨테이너의 /etc/resolv.conf 파일 안에 nameserver로 지정되어있음.
- DNS 서버 동작
- kube-dns 파드는 API 서버를 watch하며 Service / Endpoints의 변화를 감지하고 DNS 레코드를 업데이트 함.
- 이 덕분에 파드는 서비스를 이름으로 쉽게 찾을 수 있음. 서비스가 헤드리스 서비스 인 경우, 해당되는 파드의 IP 주소를 볼 수 있음.
Ingress Controller 동작 방식
- Ingress Controller는 리버스 프록시 서버(Nginx)를 실행함.
- Ingress Controller는 인그레스 / 서비스 / 엔드포인트의 변경을 감시하며, 변경이 있을 때 마다 프록시 서버(Nginx) 설정을 변경함.
- Ingress Controller는 서비스로 트래픽을 보내는 것이 아님. 서비스의 엔드포인트의 IP 주소를 찾은 후, Ingress Controller가 직접 IP로 트래픽을 보냄. 외부에서 접속한 클라이언트가 Ingress Controller로 연결할 때 IP를 보존하는데 영향을 주기 때문에 이 방법을 선호함.
11.2 컨트롤러가 협업하는 방법
어떠한 컨트롤러도 직접 파드를 만들지 않는다. 각 컨트롤러는 API 서버를 감시하며, 변경이 발생될 때 마다 자신이 해야할 쿠버네티스 리소스를 생성하는 작업만 한다. 직접 파드를 생성하는 것은 Kubelet이 한다. 파드가 진짜 만들어질 때 까지 각 컨트롤러가 어떻게 협업하는지를 살펴보자.
11.2.1 ~ 11.2.2 이벤트 체인
각 리소스를 생성하는 것은 일종의 '이벤트'로 바라볼 수 있다. 일련의 이벤트 체이닝이 발생하면서, 각각의 리소스가 생성되고 최종적으로 파드가 생성되는 것이다. 아래에서 이벤트 체이닝을 단계별로 살펴보고자 한다.

위의 이미지는 파드가 생성되기 전까지의 과정을 순서대로 살펴보는 방법이다.
- Kubectl이 POST 요청을 통해 매니페스트 파일을 API 서버에 전달한다. API 서버는 유효성 검사 후, Deployment 생성을 etcd에 기록한다.
- Deploy Controller는 API Server의 Deployment 리소스 생성을 감시한다. 이 때 API 서버에 새로운 Deployment가 생성된 것을 확인한다.
- Deploy Controller는 Deploy 생성에 대응되는 ReplicaSet 생성 요청을 API 서버로 전송한다. API 서버는 유효성 검사 후, 새로운 ReplicaSet 리소스 생성을 etcd에 기록한다.
- ReplicaSet Controller는 API Server에 Watch를 걸어두며 ReplicaSet 리소스 생성을 살펴본다.
- ReplicaSet Controller는 ReplicaSet이 생성된 것을 확인했다. ReplicaSet에 있는 Replicas와 Pod Selector에서 선택되는 파드 갯수가 같은지 확인하고, 다르다면 API 서버에게 파드 생성 요청을 보낸다. API 서버는 파드 리소스를 etcd에 기록한다.
- 스케쥴러는 API 서버에서 새로운 파드 리소스가 생성되는지 Watch 기능을 통해 확인한다. 생성된 파드 리소스에 Nodename이 지정되어있지 않을 것을 확인한다.
- 스케쥴러는 스케쥴링 알고리즘을 통해 적절한 노드를 선택한 후, 파드 리소스의 NodeName에 해당 이름을 기록하는 요청을 API 서버에 보낸다. API 서버는 요청 결과를 etcd에 저장한다.
- 각 워커 노드의 Kubelet은 API 서버를 Watch하며, 자신의 노드에 생성된 파드를 감시한다.
- + 10. Kubelet은 자신의 노드에 새로운 파드가 할당된 것을 확인하면, 컨테이너 런타임에게 파드 생성 요청을 보낸다. 결국 Kubelet이 최종적으로 파드를 생성하게 되는 것이다.
결론적으로 이야기 하면, 각 컨트롤러는 자신이 관찰하는 리소스와 생성하는 리소스가 정해져있고 Watch를 통해서 변경점을 감시하고 생성하는 역할만 한다.
11.2.3 클러스터 이벤트 관찰
위에서 발생한 일련의 이벤트는 모두 쿠버네티스의 '이벤트 리소스'로 생성되어 제공된다. 예를 들면 아래 명령어를 이용해서 발생한 이벤트를 계속 살펴볼 수 있다.
$ kubectl get events -w11.3 실행 중인 파드에 관한 이해
컨테이너 하나만 가지는 파드를 생성한다고 하더라도, 파드 내부에 실제로는 2개의 컨테이너가 생성된다. 하나는 Pause 컨테이너고, 하나는 우리가 생성하고자 했던 컨테이너다. Pause 컨테이너는 command가 "/pause"로 제공되는 컨테이너인데, 실제로는 아무런 작업을 하지 않고 인프라를 제공해주는 컨테이너다.
$ docker ps
CONTAINER ID IMAGE COMMAND
98b82139s... gcr.io/../pause 3.0 "/pause"Pause 컨테이너는 다음 기능을 제공하며, 특성은 이렇다.
- Pause 컨테이너는 리눅스 네임스페이스를 제공해준다.
- 파드의 다른 컨테이너는 Pause 컨테이너의 리눅스 네임스페이스를 이용해 통신한다.
- Kubelet은 다른 컨테이너 생성 직전에 Pause 컨테이너를 생성, 다른 컨테이너 파괴 직후에 Pause 컨테이너 파괴함.
- Pause 컨테이너와 일반 컨테이너의 라이프 사이클은 같음을 의미한다.

11.4 파드 간 네트워킹
쿠버네티스에서 파드 간 통신은 다음 요구 사항을 만족해야 한다. 아래 장에서 어떻게 이것을 만족하는지 살펴보고자 한다.
- 각 파드는 고유한 IP를 가져야 한다.
- 서로 다른 노드에 존재하는 파드끼리도 NAT 없이 Flat 네트워크로 통신할 수 있어야 한다.
- 파드가 외부망으로 요청을 보낼 때 노드 IP로 바뀌어야 함. (파드의 IP는 사설 IP이기 때문임.)
11.4.1 네트워크는 어떤 모습이어야 하는가
앞서 이야기 한 것처럼 서로 다른 노드에 존재하는 파드끼리도 NAT 없이 Flat 네트워크로 통신할 수 있어야 한다는 요구 사항이 있다. 이것에 대응되는 네트워크의 모습은 어떨까? 아래와 같은 모습일텐데 NAT를 거치지 않기 때문에 패킷에 기록된 출발 / 도착지의 IP가 변하지 않아야 한다.

만약 Pod - Pod의 연결이 아닌, Pod - 외부망 연결인 경우에 Pod가 보낸 패킷의 출발지 주소는 10.1.1.1이 아닌 노드 주소가 되어야 한다. 왜냐하면 Pod는 쿠버네티스 클러스터 내부에 배정된 Private IP를 가지기 때문이다. 따라서 파드에서 외부 망으로 요청을 보낼 때, 파드에서 보낸 패킷의 모든 출발지는 노드 주소로 바뀌게 된다.
11.4.2 네트워킹 동작 방식 자세히 알아보기
앞선 내용에 파드 내부의 컨테이너는 Pause 컨테이너의 리눅스 네임스페이스를 공유해서 사용하며 통신한다는 것을 알았다. 그러면 같은 노드의 파드 통신 / 서로 다른 노드의 파드 통신은 어떻게 구현되는 것일까?

아래에서 하나씩 살펴보자.
동일한 노드에서 파드 간의 통신 활성화
- 파드가 생성될 때 노드 기준으로 veth(가상 네트워크 인터페이스) 쌍이 생성된다. veth는 노드에 존재하며, eth0는 파드의 Pause 컨테이너에 생성된다.
- 노드에 있는 veth는 각 노드의 네트워크 브릿지로 연결된다. 그리고 각 Pod의 IP는 네트워크 브릿지에서 할당받는다.
- 각 노드의 브릿지는 서로 다른 CIDR을 제공해야, 노드에서 생성되는 파드의 IP가 유일해진다.
- 동일 노드에 있는 파드 간의 통신은 노드의 네트워크 브릿지를 통해 이루어진다.
- Pod A eth0 → veth123 → 브릿지 → vetch234 → Pod B eth0
서로 다른 노드에서 파드 간의 통신 활성화
- 서로 다른 노드에 있는 파드가 통신하려면, 트래픽이 노드A - 노드B 사이를 움직일 수 있어야 한다. 위의 그림을 예시로 들어보면 노드 A의 라우팅 테이블에 10.1.2.0/24로 향하는 모든 패킷이 노드 B로 전달될 수 있도록 구성되어야 한다.
- 일반적으로는 네트워크 브릿지 → 물리 어댑터 → 회선 → 물리 어댑터 .. 형식으로 패킷이 전달된다. 그런데 이 경우는 물리적으로 '네트워크 스위치'에 함께 연결된 노드인 경우에만 가능하다.
- SDN (Software Defiend Network)를 사용해서 네트워크를 구성하면, 하부 네트워크 토폴리지가 어떻게 되어있건 하나의 네트워크에 연결되어있는 것처럼 볼 수 있다. CNI는 SDN의 기술을 이용해서 노드와 노드 사이의 통신을 가능하게 만든다.
11.4.3 컨테이너 네트워크 인터페이스 소개
컨테이너를 네트워크에 쉽게 연결하기 위해 CNI(Container Network Interface)가 만들어지기 시작했다.
- Calico
- Flannel
위 CNI를 설치하면, 쿠버네티스는 DaemonSet을 이용해 각 노드에 Network Agent를 배포해준다. 그리고 Agent를 이용해 우리가 원하는 형식으로 통신을 할 수 있게 된다.
11.5 서비스 구현 방식
서비스는 파드 집합을 라벨로 묶어주고, 안정적인 서비스 IP + Port를 제공한다. 파드 IP는 매번 달라질 수 있는데, 클라이언트는 서비스 덕분에 파드의 IP를 신경쓰지 않고 서비스 IP : Port로 접근하기만 하면 된다. 그렇다면 서비스는 어떻게 구현될까?
11.5.1 kube-proxy 소개
- 쿠버네티스의 서비스와 관련된 모든 것은 Kube-Proxy가 처리한다.
- Kube-Proxy는 각 노드에 DaemonSet으로 실행된다.
- Kube-Proxy는 UserSpace / iptables 모드가 존재함. 최근은 iptables가 Default임.
- Kube-Proxy는 서비스를 IP + Port로 업데이트 한다.
- 이것은 서비스 IP로만 접근했을 때, 아무런 도착지도 없음을 의미한다.
- 서비스 IP는 리눅스의 Iptables에 IP + PORT로 필터링 되어 NAT 역할을 하는데 사용됨.
11.5.2 kube-proxy가 iptables를 사용하는 방법
- Service가 생성되면 API 서버는 바로 서비스에 가상 IP를 부여한다. 이것은 etcd에 저장된다.
- 각 노드에 있는 kube-proxy는 API 서버를 Watch 한다.
- kube-proxy는 새로운 Service가 생성된 것을 확인하면 각 노드의 IpTables를 수정한다.
- kube-proxy는 새로운 Endpoints가 생성된 것을 확인하면 각 노드의 IpTables를 수정한다.
- Service IP + Port를 목적지로 하는 패킷이 들어오면, 해당 패킷을 각 Pod로 보내주는 형식으로 Iptable을 수정한다. 이 때, 도착지가 Service IP : Port → Pod IP : Port로 변경되며, 이것은 iptable의 DNAT 명령어로 수행됨.
- 즉, kube-proxy는 Pod 생성 / 삭제, Pod의 Readness Probe 무응답, Service 생성 / 삭제 이벤트를 관찰하며 그것을 자신이 기동되고 있는 노드의 Iptable을 업데이트 하는 동작을 한다.
자세한 동작 방식은 이곳(https://ojt90902.tistory.com/1523)에 정리했다.
11.6 고가용성 클러스터 실행
서비스를 중단 없이 계속 실행하기 위해서는 쿠버네티스 컨트롤 플레인까지 고가용성이 필요하다. 그렇다면 쿠버네티스 컨트롤 플레인 고가용성을 달성하기 위한 방법은 무엇이 있을까?
11.6.1 어플리케이션 가용성 높이기
이 절에서는 어플리케이션의 가용성을 높이는 방법을 살펴본다.
가동 중단 시간을 줄이기 위한 다중 인스턴스 실행
수평 확장이 불가능한 어플리케이션이라고 하더라도, Replicas가 1로 지정된 Deployment를 사용하는 것이 좋다. 문제가 생기면 컨트롤 플레인이 새로운 파드로 교체해주기 때문이다. 하지만 Replicas가 1이기 때문에 발생하는 짧은 중단 시간은 어쩔 수 없다.
수평 스케일링이 불가능한 어플리케이션을 위한 리더 선출 메커니즘 사용
수평 스케일링이 불가능한 어플리케이션이라면 다음 방식으로 고가용성을 확보할 수 있다.
- 여러 어플리케이션 복제본을 생성해둠. 빠른 임대 / 리더 선출 매커니즘을 이용해 단 하나만 활성화 상태로 만들어야 함.
- 리더 / 팔로워는 다음 동작으로 구성할 수 있다.
- 리더만 활성화. 팔로워는 대기
- 리더는 쓰기 / 읽기 가능. 팔로워는 읽기만 가능.
리더 선출 로직은 반드시 어플리케이션에 포함되어야 하는 것은 아니다. 사이드카 컨테이너를 이용해서도 충분히 구현할 수 있다고 한다. 리더 선출 작업을 다른 컨테이너를 이용해서 하고, 사이드카가 이 신호를 전달받는다. 그리고 사이드카는 그 신호를 메인 컨테이너에게 동작해서 대기 → 활성화 상태로 바꿀 수도 있다. 쿠버네티스에서는 아래 링크(https://github.com/kubernetes-retired/contrib/tree/master/election)에서 리더 선출과 관련된 예제를 지원한다.
11.6.2 쿠버네티스 컨트롤 플레인 구성 요소의 가용성 향상
쿠버네티스 컨트롤 플레인의 가용성을 향상 시키려면, 컨트롤 플레인 구성요소가 가용성을 가지도록 하면 된다.
- etcd
- API Server
- Controller Manager
- Scheduler
컨트롤 플레인은 위 요소들로 구성되어있는데, 각 구성요소들이 어떻게 고가용성을 가질 수 있는지 고려해보자. 쿠버네티스 컨트롤 플레인의 고가용성은 다음 그림과 같이 구성되어 달성된다. 아래에서 더 자세히 설명해보자.

etcd 클러스터 실행
- etcd는 분산 시스템으로 설계되었다. 따라서 etcd 인스턴스가 여러 개 실행되었다고 하더라도 고가용성에는 문제가 없다.
- etcd는 RAFT 알고리즘을 이용해 합의가 이루어진 데이터를 각 etcd 인스턴스가 나누어 가진다. 예를 들어 3개의 노드 중, 1개의 노드가 실패해도 etcd는 여전히 가용한 상태다.
API 서버 클러스터 실행
- 쿠버네티스가 제공하는 API 서버는 기본적으로 stateless하다. API 서버는 요청을 받고, 모든 요청을 etcd에 기록한다. 따라서 API 서버는 여러 대 실행되어도 문제없다.
- API 서버가 etcd에 데이터를 저장하는 것은 낙관적 락을 통해 저장된다. 따라서 분산된 API 서버에 여러 요청이 들어와도 문제없이 동작한다.
컨트롤러 매니저 / 스케쥴러 실행
- 컨트롤러 매니저와 스케쥴러는 여러 인스턴스가 실행되어서는 안된다. 조금만 상상해보면, 여러 스케쥴러가 동작했을 때의 문제점을 손쉽게 떠올릴 수 있다.
- 컨트롤러 매니저 / 스케쥴러는 '리더'만 활성화 된 상태로 작업하고, '나머지'는 리더가 실패할 경우를 대기해야 한다.
- 리더가 실패할 경우 새로운 컨트롤러 매니저 / 스케쥴러의 리더가 선출되고, 이전 리더 대신 작업을 진행한다.
- 리더 활성화 / 선출은 쿠버네티스가 자체적으로 제공한다.
- 리더 활성화는 --leader-elect 옵션으로 제어됨. 기본값은 True임.
컨트롤 플레인 구성 요소에서 사용되는 리더 선출 메커니즘 이해
최근 쿠버네티스의 각 컨트롤 플레인 구성요소들은 RAFT 알고리즘을 이용해 리더 선출을 한다고 한다. 각 컴포넌트들이 직접 RAFT 알고리즘을 구현하는 것은 아니고, 이미 RAFT 알고리즘으로 합의된 상태인 etcd를 이용해 리더를 선출한다고 한다. etcd는 'lease'라는 것을 제공하는데, 이 기능을 이용해서 구현한다.
- 각 컴포넌트(스케쥴러 / 컨트롤러 매니저)는 API 서버에게 Lease 오브젝트 생성을 요청한다.
- API 서버는 이 요청을 받고, etcd에게 'lease'를 요청한다. etcd가 Lease를 주면 API 서버는 Lease 오브젝트를 k8s 클러스터에 배포한다. 이 때, Lease는 굉장히 빠르게 Expire 되는 값이 전달된다. 그리고 Lease 생성한 요청한 녀석의 Lease의 Holder가 된다.
- Lease 오브젝트 내부에는 HolderIdentity로 이 Lease를 가지고 있는 것이 누구인지 명시한다. Lease 오브젝트의 소유자가, 해당 인스턴스들의 리더가 된다.
- 인스턴스의 리더는 계속적으로 API 서버에게 Lease가 Expire 되기 전에 갱신될 것을 요청한다. 만약 Expire 되면, 더 이상 리더가 아니게 된다.

대략적으로 위와 같은 그림으로 동작한다. 그렇다면 각 인스턴스들은 어떻게 동작할까?
- 각 인스턴스는 API 서버를 통해 Lease가 갱신되지 않는지 계속 Watch한다.
- 리더 인스턴스는 API 서버에게 Lease가 갱신되도록 요청한다. 요청이 제대로 전달되지 않거나, 늦게 갱신 되는 경우 새로운 리더 선출이 이루어진다.
- 각 인스턴스는 모두 API 서버를 Watch하며 etcd의 변경점을 확인한다. 그렇지만 여기서 리더 인스턴스만 해당 이벤트를 받고 작업을 진행한다. 팔로워들은 대기 상태로 이벤트를 감시만 한다.
아래 명령어를 이용해서 현재 전체 네임 스페이스에 생성된 lease 오브젝트를 살펴볼 수 있다. 살펴보면 Controller MAnager / Shceduler에 대한 lease 뿐만 아니라 Ingress Controller에 대한 lease 역시 생성된 것을 확인할 수 있다.
$ kubectl get lease -A
>>>
ingress-nginx ingress-nginx-controller-leader ingress-nginx-controller-controller-7dfbc455b5-q89vd 24d
kube-node-lease master1 master1 26d
kube-node-lease worker1 worker1 26d
kube-node-lease worker2 worker2 26d
kube-node-lease worker3 worker3 26d
kube-system apiserver-bskcrn2i4gf5c5gco6huepssle apiserver-bskcrn2i4gf5c5gco6huepssle_460b7e50-c47a-46d6-86b7-34bb6c22b2aa 10d
kube-system kube-controller-manager master1_23374c57-2886-48e8-ac56-bb1d460ef2a3 26d
kube-system kube-scheduler master1_ee7fbe2b-a477-4b9a-8230-f2acbeb365a1 26d
longhorn-system driver-longhorn-io csi-provisioner-65dd48db7b-cl2rq 25d
longhorn-system external-attacher-leader-driver-longhorn-io csi-attacher-689fdb475f-mm27p 25d
longhorn-system external-resizer-driver-longhorn-io csi-resizer-847d645569-bm5m2 25d
longhorn-system external-snapshotter-leader-driver-longhorn-io csi-snapshotter-59ff78b47b-bb6qb 25d
longhorn-system longhorn-manager-upgrade-lock 25d아래에서 각 lease의 매니페스트 파일의 Spec을 살펴보면 현재 lease에 대한 정보를 살펴볼 수 있다.
- acquireTime : 해당 HolderIdentity가 lease를 etcd로부터 얻은 시간.
- holderIdentity : 이 lease의 소유자. 일반적으로 Pod를 의미함.
- leaseDurationSeconds: Lease가 유효한 시간. 이 시간이 지나면 lease는 expire된다.
- leaseTransitions : Lease의 소유권이 바뀐 횟수. 41이면, 현재 리더가 41번 바꼈다는 이야기다.
$ kubectl get lease -n ingress-nginx -o yaml
apiVersion: v1
items:
- apiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
creationTimestamp: "2023-05-23T01:47:02Z"
name: ingress-nginx-controller-leader
namespace: ingress-nginx
resourceVersion: "1366443"
uid: 90a5cc76-42d8-4d08-ba2a-e11cd9e5e538
spec:
acquireTime: "2023-06-08T08:01:26.690560Z"
holderIdentity: ingress-nginx-controller-controller-7dfbc455b5-q89vd
leaseDurationSeconds: 30
leaseTransitions: 41
renewTime: "2023-06-16T08:47:25.164855Z"
kind: List
metadata:
resourceVersion: ""
https://tech.kakao.com/2021/12/20/kubernetes-etcd/
https://ojt90902.tistory.com/1523
'Dev-Ops > kubernetes' 카테고리의 다른 글
| Kubernetes in Action : Chapter.4 레플리케이션과 그 밖의 컨트롤러 (0) | 2023.06.20 |
|---|---|
| Kubernetes in Action : Chapter14. 파드의 컴퓨팅 리소스 관리 (0) | 2023.06.20 |
| Kubernetes의 Kube Proxy / Iptables의 동작 (0) | 2023.06.07 |
| Kubernetes in Action : Chapter10. Statefulset (0) | 2023.06.05 |
| Kubernetes in Action : Chapter9. Deployment (0) | 2023.06.01 |