Effective Java : 아이템7. 완벽공략
- 프로그래밍 언어/JAVA
- 2023. 4. 1.
완벽공략
- NullPointerException (완벽공략 19)
- WeakHashMap (완벽공략 20)
- WeakReference
- Executor 백그라운드 쓰레드 (완벽공략 21)
- ScheduledThreadPoolExecutor
아이템7에서 나오고, 부수적으로 살펴볼만한 내용은 다음과 같다.
완벽 공략 19. NullPointerException
Java 8 Optional을 활용해서 NPE를 최대한 피하는 것이 좋다.
NullPointerException을 만나는 이유는 다음과 같다.
- 메소드에서 null을 리턴하기 때문 + null 체크를 하지 않았기 때문
- 메소드에서 적절한 값을 리턴할 수 없는 경우에 선택할 수 있는 대안
- 예외를 던진다
- null을 리턴한다
- Optional을 리턴한다.
아래의 코드를 이용해서 살펴보자.
public class Channel {
private int numOfSubscribers;
public MemberShip defaultMemberShip() {
if (this.numOfSubscribers < 2000) {
return null;
} else {
return new MemberShip();
}
}
}위 코드를 살펴보면 구독자수가 2000명보다 작은 경우 null을 반환하고, 그렇지 않은 경우 MemberShip을 반환한다. 반환값이 null 일 수 있다는 것이다. 그렇다면 사용하는 쪽에서는 어떻게 할까?
@Test
void npeTest() {
Channel channel = new Channel();
MemberShip memberShip = channel.defaultMemberShip();
if (memberShip != null) {
memberShip.equals(new MemberShip());
}
}Null을 리턴할 수 있기 때문에 사용하는 쪽에서는 반환받은 값이 Null인지를 확인해야한다. 만약 확인하지 않는 경우 NPE가 발생한다. API를 만드는 입장에서 생각해보면, 가급적이면 NullPointerException을 줄일 수 있게끔 만들어주면 좋을 것 같다.
API를 만드는 입장에서 생각해보자. 만들 때 어떻게 하면 NPE를 잘 안 만나도록 해줄 수 있을까? 선택지는 다음과 같다. API에서 null을 절대로 던지지 않기 때문에 사용자는 if 문을 이용해서 null 체크를 할 필요가 없게 된다.
- Error를 던진다
- Optional로 감싸서 반환한다. → Optional.Empty(), Optional.of()
API를 사용하는쪽에서는 Optional을 받는다. Optional로 감싼 객체는 바로 그 객체의 메서드를 사용할 수가 없다. 그렇기 때문에 Optional에서 객체를 꺼내서 사용해야하는데, 이 때 Optional이 다양한 기능들을 제공해준다. 예를 들면 다음과 같이 사용할 수 있다.
public Optional<MemberShip> defaultMemberShipWithOptional() {
if (this.numOfSubscribers < 2000) {
return Optional.empty();
} else {
return Optional.of(new MemberShip());
}
}
@Test
void npeWithOptionalTest() {
Channel channel = new Channel();
Optional<MemberShip> optional = channel.defaultMemberShipWithOptional();
optional.ifPresent(MemberShip::hello);
}
}- Optional을 반환하도록 empty(), of()를 사용한다. 이 때 null 값을 반환하면, 클라이언트에서 동일하게 Null을 체크해야하기 때문에 무의미한 행동이다.
- 사용자는 ifPresent()를 이용해서 Optional 안에 객체가 존재하는지 확인하고, 필요한 작업을 하면 된다.
Optional은 객체를 사용하는 입장에서 더욱 더 코드를 간결하게 만들어준다. 예를 들어 ifPresent() 메서드는 내부에서 컨슈머를 제공해준다. 컨슈머는 객체를 하나 제공받아서 메서드를 실행하는 역할을 하고 반환값이 없는 함수형 인터페이스다. 이 때 컨슈머를 통해서 제공되는 객체는 Optional로 감싸진 객체다. 이를 이용해서 더욱 코드가 간결해진다. 아래에는 Optional을 사용할 때 주의할 점이다.
Optional 사용 시 주의할 점
- Optional을 매개변수로 사용하지 마라. 매개변수로 전달하게 되면 Optional 자체가 null일 수도 있어서, 매개변수를 받는 쪽에서 Optional이 null인지를 한번 더 체크해야한다. 따라서 매우 비효율적이다.
- Optional은 반환타입으로만 사용해라. null값은 절대로 반환하지 말고 Optional.of(), Optional.empty()를 이용해서 반환해야한다.
- Optional로 Collection을 감싸지 마라. List, Set 자료구조 자체에 안쪽에 객체가 있는지를 알려주는 메서드가 존재한다. 따라서 Optional로 감쌀 필요가 없다.
완벽 공략 20. WeakHashMap
더 이상 사용하지 않는 객체를 GC할 때 자동으로 삭제해주는 Map
- WeakHashMap은 저장된 Key가 더 이상 강하게 레퍼런스(Strong Reference) 되는 곳이 없다면 해당 엔트리(Key, Value)를 제거한다.
- Reference
- Strong / Soft / Weak / Phantom
- WeakHashMap은 맵의 엔트리를 맵의 Value가 아니라 Key에 의존해야 하는 경우에 사용할 수 있다. (Key가 더 중요한 경우)
- 캐시를 구현하는데 사용할 수 있지만, 캐시를 직접 구현하는 것은 권장하지 않는다.
일반적으로 사용하는 Map, List, 배열에 저장된 엔트리(객체)들은 GC가 일어나도 삭제되지 않는다. 왜냐하면 Map, List가 그 객체들을 Strong Reference하고 있기 때문이다. 일반적으로 Strong Reference가 모두 없어진 객체가 GC 대상인 것을 감안한다면 합리적이다. 따라서 누군가가 Map, List에 저장된 객체들의 Strong Reference를 해제해주어야 GC가 그 객체들을 메모리에서 삭제한다.
Object[] array = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
array[1] = null;예를 들면 위와 같이 array는 배열의 각 요소들에 Strong Reference를 가지고 있고, array[1] = null를 이용해서 이 array가 해당 객체에 대해 가지고 있는 Strong Reference를 지워주어야 비로소 GC 대상이 된다.
WeakHashMap은 WeakHashMap에 저장된 Entry들 중 Key가 더 이상 Strong Reference가 없고 Weak Reference만 있는 경우라면, WeakHashMap은 GC가 일어났을 때 자동으로 이 Entry들을 Map에서 삭제해준다. 정확한 동작은 다음과 같고,
- GC가 Strong Reference가 없는 객체들을 메모리에서 삭제한다. 이 때, WeakHashMap에 있는 Key는 Strong Reference 객체를 한번 Wrapping 했기 때문에 WeakReference 자체는 존재한다.
- WeakHashMap은 WeakReference 객체에 Strong Reference가 없으면, 해당 Entry를 Map에서 삭제한다.
이것은 WeakHashMap에 내부적으로 구현된 독특한 동작이다. WeakReference를 사용한다고 모든 자료구조가 이와 같은 동작을 하지는 않는다.
일반적으로는 WeakHashMap을 사용하지 않는다. 왜냐하면 Value가 중요하고 Key가 중요하지 않는 경우가 많기 때문에, Value가 지워지면 Key가 지워지는 형태를 많이 사용한다. 그렇지만 가끔씩 Key가 지워지면 Value도 지워져야 하는 Key가 더 중요한 경우가 존재할 수 있다. 이런 경우에 WeakHashMap을 사용하면 좋다. (실제로는 이 자료구조 자체를 사용하는 것은 권장하지는 않음)
WeakReference 사용 시 조심 1. 자주 사용되는 Reference Type에는 사용하지 마라.
WeakHashMap을 사용할 때, 자주사용되는 Reference Type은 반드시 조심해야한다. 자주 사용되는 Reference Type의 값은 JVM 내부에 상수풀 같은 곳에 캐시가 되어있다. 이것은 JVM 어딘가에 Strong Reference가 존재하는 것을 의미한다. 따라서 지금 함수 Scope을 떠나거나, Strong Reference를 없애준다고 하더라도 JVM에는 항상 Strong Reference가 남아있다.
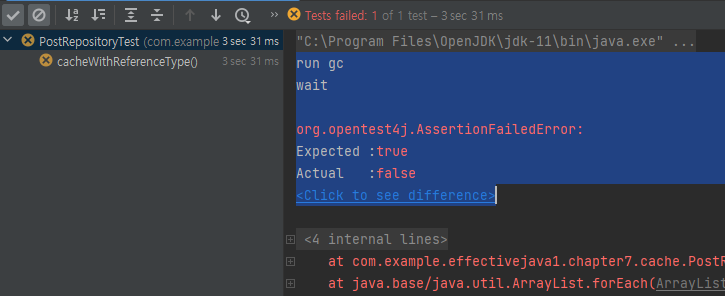
@Test
void cacheWithReferenceType() throws InterruptedException {
PostRepositoryWithReference postRepositoryWithReference = new PostRepositoryWithReference();
Integer key = 1;
postRepositoryWithReference.getPostById(key);
assertFalse(postRepositoryWithReference.getCache().isEmpty());
key = null;
System.out.println("run gc");
System.gc();
System.out.println("wait");
Thread.sleep(3000L);
assertTrue(postRepositoryWithReference.getCache().isEmpty());
}Interger는 대표적인 Reference Type이다. Integer를 WeakHashMap의 Key로 넘겨주고, Cache에 저장해둔다. 그리고 테스트 코드 내부에서 key의 Strong Reference를 해제해주고 GC를 동작해준다. 하지만 Reference Type은 JVM 상수풀에 값이 Strong Reference 되어있기 때문에 GC가 일어나도 Interger key = 1은 메모리에서 삭제되지 않는다. 따라서 아래 결과처럼 WeakHashMap은 비워지지 않는다.
따라서 WeakHashMap을 사용하더라도 항상 Strong Reference가 존재할 수 있기 때문에 원하는대로 동작하지 않을 수 있다. 이런 경우 Reference Type을 한번 감싼 커스텀 클래스를 이용해서 처리하는 것을 추천한다.
@Test
void cache() throws InterruptedException {
PostRepository postRepository = new PostRepository();
// 상수풀에 항상 Strong Reference 존재
Integer p1 = 1;
// 커스텀 클래스로 한벅 감싸기
CacheKey key = new CacheKey(p1);
postRepository.getPostById(key);
assertFalse(postRepository.getCache().isEmpty());
key = null;
System.out.println("run gc");
System.gc();
System.out.println("wait");
Thread.sleep(3000L);
assertTrue(postRepository.getCache().isEmpty());
}위 테스트 코드를 실행해보면 다음 결과를 확인할 수 있다. CacheKey는 Test 코드 메서드 내에서 유일한 Strong Reference를 잃어버리게 되고, GC가 동작되었을 때 삭제된다. 따라서 WeakHashMap은 아래와 같이 해당 Entry를 삭제처리한다.

WeakReference 사용 시 조심 2. List<weakreference<T>>는 잘못된 사용법
WeakReference를 List<WeakReference<User>>를 사용하면 잘못된 것이다. 왜냐하면 List는 WeakReference 내부에 Strong Reference가 없어진다고 해도, WeakReference 엔트리를 삭제하지 않기 때문이다. 이런 동작은 WeakHashMap의 내부 구현에 의한 결과다. 따라서 List 내부의 WeakReference가 삭제되지 않는다.
public class ChatRoomWeak {
// 잘못된 사용법
private List<WeakReference<UserWeak>> users;
public ChatRoomWeak() {
this.users = new ArrayList<>();
}
public void addUser(UserWeak user) {
this.users.add(new WeakReference<>(user));
}
public void sendMessage(String message) {
users.forEach(userWeakReference ->
Objects.requireNonNull(userWeakReference.get())
.receive(message));
}
public List<WeakReference<UserWeak>> getUsers() {
return users;
}
}예를 들어 위의 코드를 고려해보자. chatRoom은 내부적으로 List<weakreference>를 가진다. 그리고 이 리스트에 addUser()를 이용해서 추가할 때 WeakReference로 한번 감싸고 넣는다.
@Test
void test1() throws InterruptedException {
ChatRoomWeak chatRoomWeak = new ChatRoomWeak();
UserWeak user1 = new UserWeak();
UserWeak user2 = new UserWeak();
chatRoomWeak.addUser(user1);
chatRoomWeak.addUser(user2);
chatRoomWeak.sendMessage("hello");
user1 = null;
System.gc();
Thread.sleep(5000L);
List<WeakReference<UserWeak>> users = chatRoomWeak.getUsers();
Assertions.assertThat(users.size()).isEqualTo(1);
}그리고 이 테스트 코드를 실행해보자. 이 테스트 코드는 실패한다.
- user1 = null; 로 설정을 하기때문에 user1은 Strong Reference가 모두 사라져서 GC의 대상이 된다.
- List의 WeakReference는 삭제되지 않는다. 왜냐하면 이 기능은 WeakHashMap만의 기능이다. 만약 List에서도 동일하게 동작하도록 하고 싶다면, 그 기능을 직접 구현해야한다.
Reference의 종류
자바에서 Reference는 다음 4가지가 존재한다.
- Strong Reference
- Soft Reference
- Strong Reference가 모두 사라지고, 메모리가 없는 경우 GC 대상이 됨.
- Weak Reference
- Strong Reference가 모두 사라지면 GC 대상이 됨.
- Phantom Referece
- Strong Reference가 모두 사라져서 GC가 되면, Reference Queue로 PhantomReference가 전달됨.
아래에서 각각에 대해서 설명한다.
CacheKey key1 = new CacheKey(1);- Strong Reference는 위와 같은 선언을 의미한다. 필요한 오브젝트를 해당 변수가 직접 참조하도록 한다.
SoftReference<CacheKey> softReference = new SoftReference<>(new CacheKey());- Soft Reference는 위와 같이 선언한다. Soft Reference는 내부적으로 Strong Reference를 가리킬 필드를 가리키고 있는데, 해당 필드에 전달받은 Strong Reference를 저장해둔다.
- 만약 특정 오브젝트가 Strong Reference는 존재하지 않고, Soft Reference만 존재한다면 GC 대상이 된다. Soft Reference가 GC 대상이 되는 순간은 '정맘 메모리가 필요한 상황'에만 된다.
WeakReference<CacheKey> weakReference = new WeakReference<>(new CacheKey(1));- WeakReference는 이렇게 만들 수 있다.
- WeakReference는 Strong Reference가 없다면, 바로 GC 대상이 된다.
BigObject strong = new BigObject();
ReferenceQueue<BigObject> rq = new ReferenceQueue<>();
BigObjectReference<BigObject> phantom = new BigObjectReference<>(strong, rq);- PhantomReferecne는 위와 같이 선언한다.
- PhantomReferecne를 선언할 때에는 ReferernceQueue를 전달한다.
- Strong Reference가 GC가 되면, Strong Reference를 가지고 있던 Phantom Reference 객체는 Refernce Queue에 적재되게 된다. (Strong Reference 객체는 아니다)
팬텀 레퍼런스는 크게 두 가지 용도가 존재한다.
- 자원 정리할 때 사용할 수 있음.
- 언제 무거운 객체가 메모리에서 해제되는지 확인
Phantom Reference를 객체 메모리 해제 시점 확인
- Strong Reference가 메모리 해제가 되면, Phantom Reference는 Reference Queue로 전달된다.
- Phantom Reference는 isEnqeuded() 메서드를 이용해서 큐에 들어갔는지 확인할 수 있다. 즉, 객체가 소멸되는 시점을 확인할 수 있다.
public static void main(String[] args) throws InterruptedException {
BigObject strong = new BigObject();
ReferenceQueue<BigObject> rq = new ReferenceQueue<>();
BigObjectReference<BigObject> phantom = new BigObjectReference<>(strong, rq);
strong = null;
System.gc();
Thread.sleep(3000L);
// TODO 팬텀은 유령이니까..
// 죽었지만.. 사라지진 않고 큐에 들어갑니다
System.out.println(phantom.isEnqueued());
Phantom Reference를 이용해서 자원정리하기
특정 객체의 메모리 시점을 Phantom Reference를 통해서 자원 정리를 하고자 한다면, 다음과 같이 작성해 볼 수 있다.
- PhantomReference 클래스를 상속받은 커스텀 클래스 생성
- 커스텀 클래스에서 메모리 해제 시, 사용할 메서드 작성
public class BigObjectReference<BigObject> extends PhantomReference<BigObject> {
public BigObjectReference(BigObject referent, ReferenceQueue<? super BigObject> q) {
super(referent, q);
}
public void cleanUp() {
System.out.println("cleanUp");
}
}그리고 사용할 때는 아래와 같이 사용한다.
- Strong Reference가 GC에 의해서 제거되면, Strong Refernece를 가지고 있던 Phantom Reference는 Reference Que에 들어간다.
- Reference Queue에서 BigObjectReference를 꺼낸 다음에, 앞서 선언한 cleanUp() 메서드를 호출한다.
public static void main(String[] args) throws InterruptedException {
BigObject strong = new BigObject();
ReferenceQueue<BigObject> rq = new ReferenceQueue<>();
BigObjectReference<BigObject> phantom = new BigObjectReference<>(strong, rq);
strong = null;
System.gc();
Thread.sleep(3000L);
// TODO 팬텀은 유령이니까..
// 죽었지만.. 사라지진 않고 큐에 들어갑니다
System.out.println(phantom.isEnqueued());
Reference<? extends BigObject> reference = rq.poll();
BigObjectReference bigObjectCleaner = (BigObjectReference) reference;
bigObjectCleaner.cleanUp();
// 반드시 Reference를 clear 해줘야 함. 그래야 메모리에서 사라짐.
reference.clear();
}
Phantom Reference를 사용할 때는 반드시 reference를 clear 해야함.
Strong Reference는 GC에 의해서 사라지지만, Strong Reference를 참조하고 있던 Phantom Reference는 사라지지 않는다. 따라서 다 사용한 Phantom Reference는 개발자가 직접 clear()를 해줘야한다. 아래와 같이 코드를 실행하면 된다.
public static void main(String[] args) throws InterruptedException {
...
Reference<? extends BigObject> reference = rq.poll();
BigObjectReference bigObjectCleaner = (BigObjectReference) reference;
...
// 반드시 Reference를 clear 해줘야 함. 그래야 메모리에서 사라짐.
reference.clear();
}
WeakReference, SoftReference, Phaantom Reference를 사용하는 것이 좋을까?
WeakReference, SoftReference, PhantomReference로 객체를 없애는 기능을 기대하는 것은 좋지 않다. 왜냐하면 GC가 일어났을 때, 객체가 없어지는 포인트가 명확하지 않기 때문이다.
GC가 일단 언제 일어날지 모르고, GC가 일어난 시점에 Strong Reference가 모두 사라지지 않을 수 있다. 따라서 원하는 메모리 정리가 안될 수도 있기 때문에 이 기능을 이용해서 메모리 관리를 하는 것은 좋지 않다고 한다. 이것을 이용하는 것보다 List, Map에서 명시적으로 객체를 꺼내주는 것을 사용하자.
// 명시적인 제거가 추천됨.
ArrayList<Object> objects = new ArrayList<>();
objects.add(1);
objects.remove(1);
완벽 공략 21. ScheduledThreadPoolExecutor
Thread과 Runnable을 학습했다면 그 다음은 Executor
- Thread, Runnable, ExecutorService
- 쓰레드 풀의 개수를 정할 때 주의할 것
- CPU, I/O
- 쓰레드툴의 종류
- Single, Fixed, Cached, Shceduled
- Runnable, Callable, Future
- CompletableFuture, ForkJoinPool
이 공략해서는 멀티 쓰레딩과 ExecutorService에 대해서 공부해본다.
간단 정리
- Thread는 Runnable, Callable 인터페이스를 실행함.
- Runnable은 실행 결과를 반환하지 않음.
- Callable은 실행 결과를 반환함. 실행 결과는 Future 객체로 감싸서 반환됨.
- Thread를 생성하는 것은 많은 자원이 듦. 따라서 각 작업마다 쓰레드를 생성하는 것이 아니라, 생성된 쓰레드에게 작업을 할당하면 자원을 절약할 수 있음. 이 역할을 해주는 것이 Executor Service임.
- ExecutorService는 다음 4가지가 존재함.
- FixedThreadPool : 고정된 쓰레드 갯수로 작업.
- CachedThreadPool : 필요하면 쓰레드 생성해서 작업. 위험함
- SingleThreadPool : 쓰레드 하나로만 작업
- ScheduledThreadPool : 고정된 쓰레드 갯수 + 스케쥴링해서 작업함. Task 제출 순서와 실행 순서가 다를 수 있음.
쓰레드로 실행해보기
쓰레드를 하나 만드는 경우를 살펴본다. 쓰레드를 하나 만들면 메인 쓰레드와 병렬로 동작하는 쓰레드가 하나 만들어져 각자 작업을 진행한다. 쓰레드는 Runable, Callable 객체를 실행하는 클래스다. 예를 들어서 아래와 같이 코드를 작성해 볼 수 있다.
public class ThreadExample {
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
Thread thread = new Thread(new Task());
thread.start();
}
System.out.println(Thread.currentThread() + " hello");
}
static class Task implements Runnable {
@Override
public void run() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + " world");
}
}
}쓰레드 이름과 world를 출력하는 Task를 수행해야 하는 쓰레드 100개를 만들고, 각 Thread를 시작하는 코드다. 이 코드의 수행 결과는 아래에서 확인할 수 있다. 쓰레드 이름에서 볼 수 있듯이, 여러 쓰레드가 생성되어 병렬적으로 world를 출력해준다.
Thread[main,5,main] hello
Thread[Thread-42,5,main] world
Thread[Thread-33,5,main] world
Thread[Thread-6,5,main] world
Thread[Thread-10,5,main] world
Thread[Thread-40,5,main] world
Thread[Thread-1,5,main] world
Thread[Thread-38,5,main] world
Thread[Thread-34,5,main] world
Thread[Thread-28,5,main] world
Thread[Thread-39,5,main] world
...하지만 위 코드에서는 매 Task를 수행할 때 마다 쓰레드를 생성한다는 문제점이 있다.
ExecutorService 이용하기
쓰레드를 생성하는 것은 많은 시스템 리소스를 사용하게 된다. 위의 코드에서처럼 각 Task마다 쓰레드를 만들게 되면 시스템에 부하가 걸릴 수 있다. 이것을 해결하기 위한 방법은 쓰레드를 필요한 만큼만 적당한 수준으로 생성해두고, 이 쓰레드들에게 Task를 실행하도록 하는 것이다. 예를 들어 Task는 100개, Thread가 10개가 있으면 10개의 Thread가 이 Task를 나눠서 수행하는 것이다.
위와 같은 기능을 할 수 있도록 도와주는 것이 ExeuctorService다. ExeuctorService를 생성할 때, Exeuctor에서 사용할 쓰레드 풀의 갯수를 정해준다. 그리고 개발자는 ExecutorService에게 수행할 Task를 Submit하고, 작업이 끝날 때까지 기다리기만 하면 된다.
public class ExecutorExample {
public static void main(String[] args) {
int numOfCpu = Runtime.getRuntime().availableProcessors();
ExecutorService service = Executors.newFixedThreadPool(numOfCpu);
for (int i = 0; i < 100; i++) {
service.submit(new Task());
}
System.out.println(Thread.currentThread() + " hello");
service.shutdown();
}
static class Task implements Runnable {
@Override
public void run() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + " world");
}
}
}위 코드에서는 FixedThreadPoolExecutor에게 사용 가능한 CPU 갯수만큼의 쓰레드를 전달해주고, Task()를 ExeuctorService에서 제출해서 수행하는 방식으로 동작한다. 이것은 쓰레드 100개를 직접 만들 때 보다는 시간이 오래 걸릴 수 있지만 시스템 리소스를 보다 적게 사용하기 때문에 안정적으로 동작한다.
Thread[main,5,main] hello
Thread[pool-1-thread-5,5,main] world
Thread[pool-1-thread-6,5,main] world
Thread[pool-1-thread-12,5,main] world
Thread[pool-1-thread-7,5,main] world
Thread[pool-1-thread-8,5,main] world
Thread[pool-1-thread-4,5,main] world
...ExeuctorService의 종류
위 코드에서는 FixedThreadPoolExecutor를 이용했다. 하지만 ExeuctorService가 제공해주는 Executor는 여러가지가 있으며, 각 Executor의 특징을 알고 사용해야한다.
SingleThreadExecutor
이 Executor는 싱글 쓰레드만으로 Task를 수행한다. 100개의 작업이 전달되었을 때, 1개의 쓰레드만 병렬적으로 Task 수행에 동참하기 때문에 속도는 느려진다.
CachedThreadPool
이 쓰레드 풀은 내부적으로 Task를 단 하나만 저장할 수 있는 큐를 가진다. 따라서 Task를 받는 순간, 그 Task를 실행할 쓰레드에게 Task를 전달하고 작업을 실행하게 한다. 이런 자료구조의 특성상 CachedThreadPool은 쓰레드와 상호작용 할 때 다음과 같이 동작한다.
- 이미 생성된 쓰레드가 있는 경우, 그 쓰레드에게 Task를 전달한다.
- 쓰레드가 없으면, 쓰레드를 생성해서 Task를 전달한다.
- 쓰레드가 일정시간동안 놀고 있으면 쓰레드를 제거한다.
CachedThreadPool의 단점은 시스템 사용량이 폭발적으로 증가할 수 있다는 것이다. 예를 들어 갑자기 Task가 1000개가 들어왔고 가용 쓰레드가 없다면, 이 녀석은 쓰레드 1000개를 만들지도 모른다. 시스템 리소스가 증폭하며, 장애를 유발할 수 있으므로 조심히 사용해야 한다.
newFixedThreadPool
- 이 쓰레드 풀은 생성될 때, 몇 개의 쓰레드를 가지고 작업할 수 있을지를 정한다. 쓰레드 풀이 생성될 때, 그만큼의 쓰레드를 생성해둔다. 이 쓰레드풀에 Task가 submit되면, 쓰레드 풀에 있는 쓰레드가 Task를 나눠가져서 실행한다.
- ThreadPool은 내부적으로 Blocking Que를 가진다. Blocking Que는 Concurrent-safe하기 때문에 Task가 제출된 순서대로 작업이 진행될 수 있다. 일반적으로 사용하는 List, Map은 Concurrent-Safe 하지 않다.
- newFixedThreadPool은 I/O 작업, CPU 작업이냐에 따라서 몇 개의 쓰레드를 할당할지 정해야 한다.
ScheduledThreadPool
- 이 쓰레드 풀은 newFixedThreadPool과 동일하게 고정된 쓰레드 갯수만으로 동작한다. Task는 특수한 Que에 저장이 되어서, Exeuctor에 Task가 submit된 순서대로 실행이 보장되지는 않는다.
- 이 쓰레드 풀은 작업 시간을 고려해서 Task가 실행된다. 몇 초 뒤에 실행하거나, 주기적으로 실행하고 싶은 Task에 주로 사용된다.
ThreadPool에서 사용할 Thread 갯수 정하기
ThreadPool에서 사용할 Thread 갯수는 I/O 위주인지 CPU 위주인지에 따라서 다르게 설정한다.
CPU 위주 Task
Task가 CPU 위주 작업이라면 쓰레드는 작업 시간 내내 CPU를 점유해야한다. 따라서 CPU 보다 많은 쓰레드를 생성하더라도, 각 쓰레드는 병렬적으로 일을 하지 않고 CPU를 점유할 시간만을 기다린다. 불필요하게 쓰레드가 많이 생성되어 시스템 리소스가 낭비되는 것이다. 이것의 해결책은 가용한 CPU 갯수만큼 쓰레드를 생성하는 것이다.
int numOfCpu = Runtime.getRuntime().availableProcessors();
ExecutorService service = Executors.newFixedThreadPool(numOfCpu);위와 같이 가용한 CPU 갯수를 구하고, 그 갯수만큼 쓰레드를 생성하는 것으로 해결할 수 있다. 하지만 이것은 시스템 전체로 본다면 정답은 아닐 수 있다. 모든 쓰레드 풀이 이렇게 생성한다면, CPU 갯수 이상으로 쓰레드가 생성되기 떄문이다.
I/O 위주 Task
I/O 위주의 Task는 작업이 실행될 때 CPU를 점유하지 않고, 기다리기만 한다. 따라서 CPU 이상으로 Task가 만들어져도 병렬적으로 동작하는데 문제가 없다. 그렇다면 I/O 위주의 Task는 몇 개의 쓰레드를 만들어야 할까? 이것은 어떤 I/O인지, I/O 동작이 어떤 것인지에 따라 다르다고 한다.
DB의 특정 쿼리를 가져올 때 얼마만큼의 네트워크 지연이 있는지, 다른 서버의 API를 호출했을 때 얼마만큼의 네트워크 지연이 있는지 등의 시간을 고려해서 쓰레드 풀의 쓰레드 갯수를 설정해야한다. 이것을 성능 튜닝이라고 한다.
Runnable, Callable
Task는 Runnable, Callable 인터페이스를 이용할 수 있다. Runnable은 단순히 작업만 실행하고, 작업의 결과를 반환하지 않는다. 만약 작업의 결과를 알고 싶다면 Callable 인터페이스를 구현해서 사용해야 한다. 예를 들면 아래와 같은 코드를 이용할 수 있다.
public class ExecutorWithCallableExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
int numOfCpu = Runtime.getRuntime().availableProcessors();
ExecutorService service = Executors.newFixedThreadPool(numOfCpu);
// Non-Blocking
Future<String> submit = service.submit(new Task());
System.out.println(Thread.currentThread() + " hello");
// Blocking
System.out.println("submit.get().toString() = " + submit.get().toString());
service.shutdown();
}
static class Task implements Callable<String> {
@Override
public String call() throws Exception {
Thread.sleep(2000);
System.out.println(Thread.currentThread() + " world");
return Thread.currentThread().getName();
}
}
}코드는 다음과 같다.
- Callable 인터페이스를 선언할 때, 반환받을 타입을 지정해줘야한다.
- Future<String> submit에서는 메인 쓰레드가 Blocking 되지 않는다. 이 때, 서브 쓰레드가 생성되어 병렬적으로 Task를 처리하기 시작한다. 따라서 hello가 바로 출력된다.
- Future 객체에서 결과를 가져오려고 하면, 이 때 메인 쓰레드는 Blocking 된다.
실행 결과는 다음과 같다.
Thread[main,5,main] hello
Thread[pool-1-thread-1,5,main] world
submit.get().toString() = pool-1-thread-1'프로그래밍 언어 > JAVA' 카테고리의 다른 글
| Effective Java : 아이템9. try-finally 보다 try-with-resources를 사용하라 (0) | 2023.04.02 |
|---|---|
| Effective Java : 아이템14. Comparable 규약 (0) | 2023.04.02 |
| Effective Java : 아이템5 완벽공략 (0) | 2023.02.26 |
| Effective Java : 아이템2. 생성자에 매개변수가 많다면 빌더를 고려하라 (0) | 2023.02.26 |
| Effective Java : 아이템5. 자원을 직접 명시하지 말고 의존객체 주입을 사용하라 (0) | 2023.02.25 |