Unit Testing : 5. 목과 테스트 취약성
- Test
- 2023. 3. 4.
들어가기 전
이 글은 Unit Testing 5장 목과 테스트 취약성을 공부하며 작성한 글입니다.
5. 목과 테스트 취약성
이번 장에서는 Mock이 취약한 테스트를 만드는 것을 살펴본다. 이 때 취약한 테스트라는 것은 '리팩토링 내성'이 없는 테스트를 의미한다. 그렇지만 Mock을 사용해서 좋은 테스트가 되는 경우도 있다. Mock이 어떻게 취약한 테스트를 만들고, 리팩토링 내성 저하 없이 Mock을 사용하는 방법을 공부한다.
5.1 Mock과 Stub 구분
테스트 대상 시스템 (SUT)와 그 협력자 사이의 상호 작용을 검사할 수 있는 객체들을 테스트 대역이라고 한다. Mock과 Stub은 테스트 대역의 일종이다. Mock, Stub의 구체적인 차이점은 무엇이 있을까?
5.1.1 테스트 대역 유형
테스트 대역은 모든 유형의 가짜 의존성을 의미한다. 테스트 대역의 주요 역할은 테스트를 편리하게 하는 것이다. 하지만 테스트 대역을 나쁜 곳에서 사용하는 경우, 테스트의 설정 및 유지 보수에 어려움을 초래할 수 있다. 즉, 테스트를 처음 구성할 때는 손쉬운 테스트가 가능하게 하지만 소프트웨어의 규모가 커질수록 유지보수의 어려움을 초래한다는 것이다. 아래에서는 Mock과 Stub의 구분을 살펴본다.

- Mock : 외부로 나가는 상호 작용을 모방 + 검사에 도움됨. 이 작용은 SUT가 상태를 변경하기 위해 의존성을 호출하는 경우
- Stub : 내부로 들어오는 상호 작용 모방에 도움됨. 이 작용은 SUT가 입력 데이터를 얻기 위한 의존성을 호출하는 경우
Mock은 외부 의존성과의 상호 작용을 모방하고 검사까지 한다. 그렇지만 Stub은 외부 의존성과의 상호작용을 단순히 모방만한다. 이것은 중요한 차이점인데, 이유는 뒤에서 알아본다.
5.1.2 도구로서의 Mock, 테스트 대역으로서의 Mock
Mock은 두 가지 용어로 사용될 때가 있다. 첫번째는 도구로써의 Mock, 두번째는 테스트 대역으로써의 Mock이 있다.
- 도구 Mock : 테스트 대역 Mock, Stub을 생성
- 테스트 대역 Mock : 앞서 이야기 했던 Mock 개념
- 테스트 대역 Stub : 앞서 이야기 했던 Stub 개념
앞에서 이야기 했던 Mock은 테스트 대역으로써의 Mock을 의미한다. 아래에서 도구 Mock, 테스트 대역 Mock, 테스트 대역 Stub의 개념을 볼 수 있다.
class MemberTest {
@Test
void test1() {
// mock
EmailGateWay emailGateway = mock(EmailGateWay.class);
// stub
TestDataBase dataBase = mock(TestDataBase.class);
when(dataBase.getData()).thenReturn("1");
// when
Member member = new Member();
member.sendEmail();
// then
verify(emailGateway, times(1)).send(); // mock
}
}- mock()은 도구로써의 Mock을 의미한다. mock()을 이용해서 테스트 대역 mock, stub을 생성할 수 있게 된다.
- dataBase는 stub을 의미한다. 외부 의존성인 database로부터 단지 Input만 얻어오는데, 이것은 내부로 들어오는 상호작용이기 때문이다.
- emailGateWay는 mock을 의미한다. 외부 의존성을 나가는 상호작용이며, verify를 통해 행동을 검사까지 한다.
5.1.3 스텁으로 상호 작용을 검증하지 말라
스텁은 내부로 들어오는 상호 작용을 모방한다. 내부로 들어오는 상호 작용은 특히 검증을 해서는 안된다. 내부로 들어오는 상호작용은 SUT가 생성하는 최종 결과가 아니기 때문이다. 스텁은 단순히 SUT가 최종결과를 생성하도록 입력을 제공한다. 테스트에서 리팩토링 내성을 향상시키는 방법은 구현 세부 사항에서 멀어지고 결과만을 검증하는 것이다. 따라서 스텁과의 상호작용은 검증할 필요 없이, 단순히 인풋 데이터를 넣어주는 형태로 사용한다.
// Mock은 검증하기도 함.
verify(emailGateway, times(1)).send(); // mock반면 Mock은 상호작용을 검증하기도 한다. 이런 경우는 이 API를 사용하는 사람들에게 의미있는 호출일 경우다. 예를 들어 이메일이 실제로 보내지는 것은 최종 결과이며, 최종 결과로 메일을 보내는 것은 인사담당자 원하는 일일 경우가 있다. 이 경우에는 사용하는 사람이 원하는 최종 결과이기 때문에 Mock을 통한 외부 의존성 호출을 검증하는 것이 의미가 있다.
// stub 모방
when(dataBase.getData()).thenReturn("1");
// stub 검증
verify(dataBase, times(1)).getData();만약 stub을 검증까지 한다면 위와 같은 코드가 될 것이다. 딱봐도 아무런 의미가 없어보인다.
5.1.4 목과 스텁 함께 사용하기
Mock, Stub이라는 테스트 대역은 성질을 의미한다. 즉, 하나의 Mock 객체가 테스트 대역으로서의 Mock, Stub의 성질을 모두 나타낼 수 있다. 때로는 이런 테스트 대역을 만들기도 해야한다.
@Test
void purchaseFailsWhenNotEnoughInventory() {
// mock
Store store = spy(Store.class);
when(store.hasEnoughInventory("shampoo", 5)).thenReturn(false);
Customer sut = new Customer();
sut.purchase(store, "shampoo", 5);
verify(store, never()).removeInventory("shampoo", 5);
}Mockito의 spy() 메서드를 이용해서 테스트 대역을 하나 생성했다. 이 테스트 대역은 Mock, Stub의 특성을 모두 가진다.
- hasEnoughInventory()를 이용해서 테스트 대역을 통해 sut가 최종 결과를 내기 위한 입력을 넣어준다. → Stub 특성
- 검증 과정에서 verify() 메서드를 이용해 removeInventory()가 호출되지 않은 것을 검증한다. → Mock 특성
앞서 이야기했던 '스텁의 상호작용을 검증하지 마라'라는 대원칙을 위배하지 않으면서도, Mock 객체의 검증을 할 수 있었다. 이처럼 Mock, Stub의 특성을 가지는 테스트 대역은 이름을 가져야 부르기 편하기 때문에 일반적으로 Mock 객체라고 부르고자 한다.
5.2 식별할 수 있는 동작과 구현 세부 사항
4장에서 취약한 테스트는 리팩토링 내성이 없는 테스트라는 것을 알았다. 리팩토링 내성이 없는 테스트는 테스트 대상이 구현 세부 사항과 강하게 결합했기 때문에 발생한다. 리팩토링 내성을 얻는 방법은 '최종 결과를 검증'하는 방법 뿐이라는 것이다. 즉, 테스트는 '어떻게'가 아니라 '무엇을'에 중점을 둬야한다. 이번 절에서는 '식별할 수 있는 동작' 과 '구현 세부 사항'이 무엇인지에 대해서 공부한다.
5.2.1 식별할 수 있는 동작은 공개 API와 다르다.
제품에서 사용되는 모든 코드는 다음 두 가지로 분류해 볼 수 있다.
- 공개 API(public) / 비공개 API (private)
- 식별할 수 있는 동작 / 구현 세부 사항
위의 두 가지는 다른 차원이다. 공개 API이면서 식별할 수 있는 동작일 수 있고, 공개 API이면서 구현 세부 사항일 수도 있다. 하지만 잘 설계된 API라면 공개 API는 식별할 수 있는 동작과 일치하고, 비공개 API는 구현 세부 사항과 일치한다.
그렇다면 식별할 수 있는 동작은 무엇을 의미하는 걸까? 아래 동작 중 하나라도 만족한다면 그것은 식별할 수 있는 동작이다. 구현 세부 사항은 아래 두 가지 중 하나도 만족하지 않는다.
- 클라이언트가 목표를 달성하는 데 도움이 되는 연산을 노출한다.
- 연산을 수행하거나, 사이드 이펙트를 초래하거나, 둘다 하는 메서드다.
- 클라이언트가 목표를 달성하는데 도움이 되는 상태를 노출하라.
- 상태는 시스템의 현재 상태를 의미한다.

잘 구현된 API는 다음과 같이 구성된다. Public API = 식별할 수 있는 동작 / Private API = 구현 세부 사항과 1:1로 매칭되도록 한다.

잘 구현되지 못한 API는 public API를 통해 구현 세부 사항을 클라이언트에게 노출한다. 이것은 잠재적으로 불변성의 모순을 발생시킬 수도 있고, 리팩토링 내성도 약화시킬 수 있다.
5.2.2 구현 세부 사항 유출 : 연산 결과의 노출 예시
구현 세부 사항이 Public API로 노출되는 상황을 알아보고자 한다. 예시로 상황을 정리해보자.
- UserEntity 클래스가 존재한다.
- Name 필드를 가진다.
- Name 필드는 50자보다 짧은 이름을 가져야 한다.
- UserController 클래스가 존재한다.
- renameUser() 메서드를 테스트 해야함.
- UserId로 User를 DB에서 조회한 다음, User에 새로운 이름을 저장한다.
// 클라이언트
public class UserController {
public void renameUser(Long userId, String newName) {
UserEntity userFromDB = getUserFromDB(userId);
String normalizedName = userFromDB.normalizedName(newName);
userFromDB.setName(normalizedName);
saveUserToDB(userFromDB);
}
...
}
// 테스트 대상
public class UserEntity {
private String Name;
public void setName(String name) {
Name = name;
}
public String normalizedName(String name) {
return name.length() > 50 ? name.substring(0, 50) : name;
}
}UserController가 클라이언트로 가정해보자. 클라이언트는 renameUser()를 이용해서 UserEntity의 이름을 바꾸고 싶다. 이 때 UserController 클라이언트는 UserEntity의 public API normalizedName(), setName() 2가지를 사용한다.
- 클라이언트의 목표는 새로운 이름을 설정 및 저장하는 것이다.
- setName()은 새로운 이름을 저장하는 메서드다. 즉, 클라이언트가 기대하는 동작을 한다.
- normalizedName()은 위의 목표와 직접적인 연관은 없다. 세부 구현 사항이다.
따라서 위의 코드를 살펴보면 구현 세부사항 + 식별할 수 있는 동작이 모두 Public API로 공개된 상태가 된다. 즉, 아래와 같은 상황이 된다.

구현 세부 사항이 노출된 경우, 작성된 코드에 불변성 모순이 발생할 수 있다. 예를 들어 위 코드에서 normalizedName() 메서드를 먼저 사용하는 것을 잊거나, 사용하는 순서가 달라진다면 기대하던 결과와 전혀 다른 결과가 나타난다. 또한 테스트 코드 자체도 깨지기 쉬워진다. 위의 문제가 있는 코드를 개선한다면 다음과 같이 바뀔 수 있다.
public class UserRepository {
public void renameUser(Long userId, String newName) {
UserEntity userFromDB = getUserFromDB(userId);
userFromDB.setName(newName;
saveUserToDB(userFromDB);
}
...
}
public class UserEntity {
private String Name;
// 공개 API
public void setName(String name) {
this.Name = normalizedName(name);
}
// 비공개 API
private String normalizedName(String name) {
return name.length() > 50 ? name.substring(0, 50) : name;
}
}수정을 하면 다음과 같아진다.
- normalizedName()은 구현 세부 사항이기 때문에 비공개 API로 변경했다.
- setName()은 이름을 바꾸길 기대하는 클라이언트의 작업을 돕기 때문에 식별할 수 있는 동작이다. 따라서 그대로 public API로 사용한다.
- setName()은 구현 세부 사항인 normalizedName() 메서드를 사용한다.
위 상태를 그림으로 표현하면 아래와 같다.

정리
- 잘 설계된 API는 식별할 수 있는 기능과 1:1 매칭이 되고, 구현 세부 사항을 노출하지 않는다.
- 구현 세부 사항이 노출되면 취약한 테스트, 불변성에 모순을 가져올 수 있다.
- 구현 세부 사항이 노출되었는지를 확인하는 방법은 다음이 있다.
- 단일한 목표를 달성하고자 클래스에서 호출해야 하는 연산의 수가 1보다 크면 해당 클래스에서 구현 세부 사항을 유출할 가능성이 있다. 이상적으로는 단일 연산으로 개별 목표를 달성해야 한다.
5.2.3 잘 설계된 API와 캡슐화
- 잘 설계된 API를 유지 보수하는 것은 캡슐화 개념과 관련이 있다.
- 캡슐화는 불변성 위반이라고도 하는 모순을 방지하는 조치다. 불변성은 항상 참이어야 하는 조건을 의미한다.
- 구현 세부 사항을 노출하게 되면 불변성 위반을 가져온다.
장기적으로 소프트웨어의 유지보수에는 캡슐화가 중요하다. 캡슐화를 하면 코드 복잡도를 감소시키는데, 이것은 소프트웨어의 지속적인 성장을 돕는다. 예를 들어 하나의 API가 할 수 있는 것과 할 수 없는 것을 알려주지 않으면 모순이 발생하지 않도록 많은 정보들을 염두해두어야 한다. 하지만 캡슐화가 올바르게 유지되는 경우, 이 부분을 굉장히 덜어준다.
따라서 좋은 테스트 코드를 만들기 위해서는 캡슐화를 항상 잘 해두어야 한다. 정리하면 아래와 같다.
- 구현 세부 사항을 숨기면 클라이언트의 시야에서 클래스 내부를 가릴 수 있기 때문에 내부를 손상시킬 위험이 적다.
- 데이터와 연산을 결합하면 해당 연산이 클래스의 불변성을 위반하지 않도록 할 수 있다.
- 클래스 내부에서 데이터를 구현 세부 사항과 관련된 연산과 결합해서 사용하도록 하자!
5.2.4 구현 세부 사항 유출 : 상태가 노출된 경우
앞선 절에서는 특정 클래스 코드의 구현 세부 사항 중 연산이 노출된 경우를 살펴봤다. 이번에는 구현 세부 사항 중 상태가 노출된 경우를 살펴보고자 한다. 구현 세부 사항의 상태가 노출되더라도 문제가 발생할 수 있다.
public class Team {
public List<Player> players = List.of(new BaseBallPlayer(), new FootBallPlayer(), new SoccerPlayer());
public int playerSalary() {
return players.stream().mapToInt(Player::getSalary).sum();
}
}여기서 players는 상태고, playerSalary()는 연산이다. 클라이언트는 playerSalary()를 통해 현재 Team에 속한 선수의 연봉의 합을 구하는 연산을 한다. 그러면 이 때 players라는 상태는 클라이언트에게 노출되어야 할까? 정답은 클라이언트에게 노출되지 않는 것이 좋다. 이다.
players 상태는 클라이언트가 연봉을 구하는데 있어서 직접적인 도움을 주지는 않는다. 구현 세부 사항에 가깝다. 또한 클라이언트가 players를 직접 가져와서 연봉을 직접 구하는 방법도 있을텐데, 이런 경우는 캡슐화가 제대로 이루어지지 않은 것을 의미한다. 따라서 public players로 공개된 세부 구현 사항 상태 정보를 비공개로 바꾸는 것이 좋다.
이처럼 구현 세부 사항을 모두 비공개로 바꾸면 어떤 점이 좋을까? 테스트에서는 식별할 수 있는 동작을 검증하는 것 외에는 아무런 선택지가 없다. 즉, 테스트가 식별할 수 있는 동작만 검증하도록 강제할 수 있고, 덕분에 테스트 코드의 리팩토링 내성이 증가한다. 표로 정리하면 다음과 같다.
| 식별할 수 있는 동작 | 구현 세부 사항 | |
| 공개 | 좋은 | 나쁨 |
| 비공개 | 해당 없음 | 좋음 |
5.3 목과 테스트 취약성의 관계
이 절에서는 육각형 아키텍쳐, 내부 통신과 외부 통신의 차이점, 목과 테스트 취약성 간의 관계를 알아본다.
5.3.1 육각형 아키텍쳐 정의
육각형 아키텍쳐는 도메인 / 어플리케이션 서비스 계층으로 나누어진다. 도메인은 어플리케이션의 중심부이기 때문에 도표의 중앙에 위치한다. 도메인 계층에는 어플리케이션에서 사용하는 비즈니스 로직이 위치한다. 어플리케이션은 도메인 계층과 프로세스 외부 의존성 간의 작업을 조정한다. 예시는 다음과 같다.
- DB를 조회하고 해당 데이터로 도메인 클래스 인스턴스 구체화
- 해당 인스턴스에 연산 호출
- 결과를 데이터베이스에 다시 저장
육각형 아키텍쳐는 도메인 / 어플리케이션 서비스 계층으로 나누어져 있는데, 이것은 각 계층이 책임을 나눠가져서 좀 더 좋은 구조를 만드는 것을 의미한다.
도메인 / 어플리케이션 서비스 계층의 관심사 분리
- 어플리케이션 서비스 계층은 외부 어플리케이션과 통신하거나 DB를 검색하는 것과 같은 일을 해야한다.
- 어플리케이션 서비스 계층은 요청이 들어오면 도메인 클래스의 연산으로 변환한 다음 결과를 저장하거나 반환해서 도메인 계층으로 바꿔야하는 책임이 있다.
어플리케이션 내부 통신
- 도메인 계층 내부 클래스는 도메인 클래스끼리만 의존한다.
- 어플리케이션의 흐름은 어플리케이션 서비스 계층 → 도메인 계층만 가능하다. 즉, 단방향 흐름이다. 바꿔이야기 하면 도메인 계층은 어플리케이션 서비스 계층을 알지 못한다.
어플리케이션 간의 통신
외부 어플리케이션은 도메인 계층에 직접적으로 접근할 수는 없다. 반드시 어플리케이션 서비스 계층을 통해서 도메인 계층에 접근하도록 해야한다.

육각형 아키텍쳐를 가지고 있다면 식별할 수 있는 동작은 단방향(어플리케이션 서비스 계층 → 도메인 계층)으로 흐른다. 외부 클라이언트에게 중요한 목표는 개별 도메인 클래스에서 달성한 하위 목표로 변환한다. 따라서 도메인 계층에서 식별할 수 있는 동작은 각각 구체적인 비즈니스 유즈케이스와 연관성이 있다.
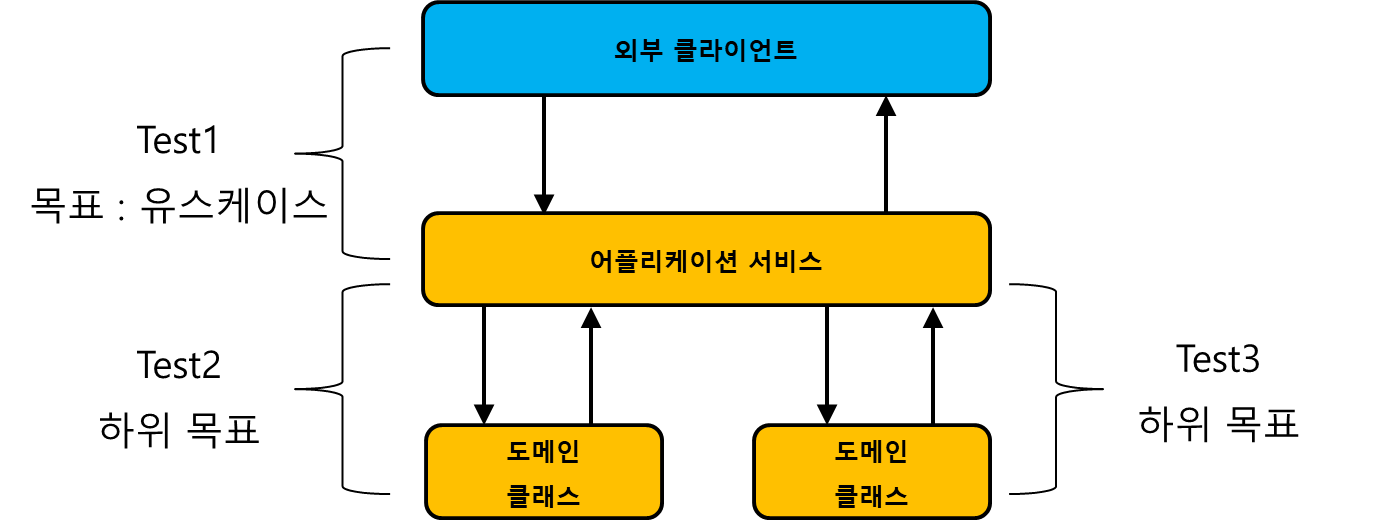
하위 클래스의 식별할 수 있는 동작으로부터 재귀적으로 올라가게 되면 비즈니스 유즈 케이스에 도착하게 된다. 이것을 바꿔서 이야기 하면, 도메인 클래스의 클라이언트는 어플리케이션 서비스 계층이므로 이 관점에서의 식별할 수 있는 동작만 노출하고 테스트하면 된다. 계층적으로 각 클라이언트가 식별할 수 있는 동작을 테스트를 검증하도록 하는 것이다.
좋은 테스트라면, 어떤 테스트든 비즈니스 요구사항으로 거슬러 올라갈 수 있어야 한다. 각 테스트는 도메인 전문가에게 의미 있는 이야기를 전달해야하며, 그렇지 않으면 테스트가 구현 세부 사항과 결합되어 있으므로 불안정하다는 것을 강하게 암시한다.
이렇게 잘 설계된 API를 이용해서 코드 베이스를 검증하는 테스트는 식별할 수 있는 동작만 결합되어 있다. 따라서 비즈니스 요구사항만 잘 검증할 수 있고, 리팩토링 내성도 강하게 가질 수 있게 된다.
public class UserRepository {
// 공개 API
public void renameUser(Long userId, String newName) {
UserEntity userFromDB = getUserFromDB(userId);
userFromDB.setName(newName;
saveUserToDB(userFromDB);
}
}
public class UserEntity {
// 공개 API
public void setName(String name) {
this.Name = normalizedName(name);
}
// 비공개 API
private String normalizedName(String name) {
return name.length() > 50 ? name.substring(0, 50) : name;
}
}예를 들어 위의 UserRepository, UserEntity를 육각형 아키텍쳐라고 정의해보자. 이곳에서 예시를 들어보면 다음과 같다.
- 외부 클라이언트는 renameUser()만 호출한다. → 이름이 정상적으로 바뀌었는지를 검증한다.
- UserRepository는 UserEntity의 setName()만 호출한다. → normalizedName()은 비공개 API로 사용해야한다.
nromalizedName() 메서드만으로는 재귀적으로 위쪽 계층으로 올라갔을 때, 클라이언트의 요구 사항을 추적할 수 없다. 클라이언트의 요구사항은 이름을 바꿔달라는 내용이지만, normalizedName() 메서드는 이름을 50자 이하로 줄여주는 역할만 하기 때문이다. 따라서 normalizedName()은 구현 세부 사항이므로 검증해서는 안된다.
5.3.2 시스템 내부 통신과 시스템 간 통신
어플리케이션의 시스템 통신은 시스템 내부 통신 / 시스템 간 통신으로 나누어진다.
- 시스템 내부 통신 : 구현 세부 사항. 검증 대상이 아님.
- 시스템 간 통신 : 식별할 수 있는 동작. 검증 대상이 될 수 있음. Mock을 이용하면 좋을 수 있음.
여기서 시스템 내부 통신의 예시는 '도메인 클래스 간의 협력'을 의미한다. 외부 클라이언트 입장에서 도메인 클래스끼리 하는 협력은 식별할 수 있는 동작이 아니므로 구현 세부 사항에 해당한다. 따라서 시스템 내부 통신을 검증하면 취약한 테스트가 된다.
시스템 간 통신은 전체적으로 해당 시스템의 식별할 수 있는 동작을 나타낸다. 외부 어플리케이션과 하는 통신은 우리 마음대로 바꿀 수 없을 가능성이 높다. 다른 쪽에서도 외부 어플리케이션을 사용할 수도 있고, 우리가 제어할 수 없는 영역일 수도 있다. 따라서 우리의 어플리케이션이 점점 커지더라도, 외부 어플리케이션과의 통신하는 방법은 유지해야한다.

시스템 간 통신은 식별할 수 있는 동작이기 때문에 검증 대상이다. Mock은 시스템 간 통신 패턴을 확인할 때 사용하면 좋을 수 있다.
5.3.3 시스템 내부 통신과 시스템 간 통신의 예시. 그리고 Mock
다음 비즈니스 유즈 케이스를 이용해 시스템 내부 통신 / 시스템 간 통신의 차이점을 살펴본다.
- 고객이 상점에서 제품을 구매하려고 한다.
- 매장 내 제품 수량이 충분하면
- 재고가 상점에서 줄어든다.
- 고객에게 이메일로 영수증을 발송한다.
- 확인 내역을 반환한다.
public class CustomerController {
...
public boolean purchase(int customerId, int productId, int quantity) {
Customer customer = customerRepository.getById(customerId);
Product product = productRepository.getById(productId);
// customer, store 통신
boolean isSuccess = customer.purchase(store, product, quantity);
// store에서 removeInventory() 호출됨.
if (isSuccess) {
emailGateWay.send();
}
return isSuccess;
}
}위에서 구매라는 동작은 시스템 내부 통신 / 시스템 간 통신으로 구성되어 있다. 아래가 분류 결과다.
- 시스템 간 통신
- 외부 클라이언트에서 customerController의 purchase()를 호출하는 동작.
- customerController()가 emailGateway.send()를 통해 외부 어플리케이션 SMTP에 메세지를 보내는 역할.
- 시스템 내부 통신
- customer.purchase()를 했을 때, store.removeInventory() 되는 것. customer와 store는 각각 도메인 클래스이기 때문이다.
여기서 중요한 부분은 이것이다. SMTP를 호출하는 것은 외부 클라이언트가 식별할 수 있는 동작이고, 시스템 간 통신을 의미한다. 따라서 검증 대상이 된다. 시스템 간 통신은 항상 유지되기 때문에 Mock으로 대체해도 큰 문제가 없다. (항상 유지된다는 대전제가 없다면, 통신 방식이 바뀌면 바로 테스트 코드는 실패하게 될 것이다.). 대부분 시스템 간 통신 방식은 수정 되지 않기 때문에 이것을 Mock으로 대체해도 취약한 테스트가 되지 않는다. 따라서 이 부분만 Mock으로 대체를 한다.
// 좋은 테스트
@Test
void purchaseSuccessWhenEnoughInventory() {
// Mock
EmailGateWay emailGateWay = mock(EmailGateWay.class);
// given
CustomerController customerController = new CustomerController(emailGateWay);
// when
boolean isSuccess = customerController.purchase(1, 2, 5);
// then
assertThat(isSuccess).isTrue();
verify(emailGateWay, times(1)).send();
}시스템 간 통신을 Mock으로 변경하면, 식별 가능한 동작(외부 SMTP에 메세지 보내기)를 검증할 수 있게 된다. 또한, 값을 정상적으로 받았다는 연산 결과 (식별가능한 동작) 역시 검증한다.
// 취약한 테스트
@Test
void badTest() {
// Mock
Store store = mock(Store.class);
when(store.hasEnoughInventory("shampoo", 5)).thenReturn(true);
// given
Customer customer = new Customer();
// when
boolean isSuccess = customer.purchase(store, "shampoo", 5);
// then
assertThat(isSuccess).isTrue();
verify(store, times(1)).removeInventory("shampoo", 5); // 필요없는 부분
}반면 Mock을 이런 곳에 사용하게 되면 취약한 테스트가 된다. Customer 클래스의 purchase() 동작은 최종 사용자 관점에서 중요한 것은 다음과 같다. 즉, 식별 가능한 동작은 다음과 같다.
- 샴푸를 구매했는지 성공한 것. → customer.purchase()의 값으로 확인.
- store에서 샴푸가 5개 차감되었는지 확인하는 것 → store.getInventory()로 확인.
이 때, store.removeInventory()가 호출되는 것은 클라이언트의 요청을 달성하기 위한 중간 과정이다. 중간 과정은 구현 세부 사항이다. 위의 테스트 코드는 구현 세부 사항과 결합되어 있으므로 취약한 테스트 코드가 된다. 이렇게 Mock을 사용하는 것은 안 좋은 테스트 코드를 만든다
5.4 단위 테스트의 고전파 / 런던파 재고
- 런던파는 불변 의존성을 제외한 모든 의존성에 목 사용을 권장한다. 또한 시스템 간 통신 / 시스템 내부 통신을 구분하지 않는다. 시스템 내부 통신에도 목을 사용하기 때문에 세부 구현 사항과 강하게 결합해서 리팩토링 내성이 없어진다.
- 고전파는 테스트 간에 공유하는 의존성만 Mock으로 사용할 것을 권장한다. 그렇지만 이것 역시 완벽하지는 않다. 자세한 내용은 아래에서 살펴본다.
5.4.1 모든 프로세스 외부 의존성을 Mock으로 해야하는 것은 아니다.
프로그램에서 사용하는 의존성은 다음으로 분류할 수 있따.
- 공유 의존성 : 테스트 간에 공유하는 의존성 (제품 코드가 아님)
- 프로세스 외부 의존성 : 프로그램의 실행 프로세스 외에 다른 프로세스를 점유하는 의존성 (DB, SMTP, 메세지 버스, 카프카 등)
- 비공개 의존성 : 공유하지 않는 모든 의존성
공유 의존성은 단위 테스트 간의 격리를 위해서 반드시 필요하다. 공유 의존성이 프로세스 내부에 있다면, 새로운 인스턴스를 생성해서 손쉽게 대체할 수 있다. 하지만 공유 의존성이 외부에 있으면 그렇게 할 수 없다. 이 때, 공유 의존성을 테스트 대역(Mock)으로 변경해주는 것이다.
하지만 모든 외부에 있는 공유 의존성을 Mock으로 바꾸지 않아도 된다. 외부에 있는 공유 의존성이지만, 클라이언트가 우리 어플리케이션을 통해서만 접근가능하고, 외부에서 관찰 불가능한 어플리케이션은 우리 시스템의 일부가 된다. 이런 외부 공유 의존성은 우리 시스템과 함께 생명주기를 바꿔도 문제가 없기 때문이다. 이런 경우는 우리 시스템에서 사용하는 DB가 좋은 예시가 된다. 우리 시스템에서 DB로 접근하는 것은 지금부터는 시스템 내부 통신, 즉 구현 세부 사항으로 볼 수 있다.
DB처럼 완전히 통제권을 가진 외부 어플리케이션은 우리의 의지에 따라 언제든지 바뀔 수 있다. 따라서 이 부분을 Mock으로 대체하게 된다면 깨지기 쉬운 테스트가 된다. 외부 의존성을 Mock으로 변경하는 것은 '통신 방법이 거의 변할 가능성이 없다'에서 기인했다. 하지만 DB가 내부 시스템의 일부처럼 되면서 언제든지 바뀔 수 있는 존재가 되었다. 따라서 이런 부분은 절대로 Mock을 사용해서는 안된다.
5.4.2 목을 사용한 동작 검증
좋은 테스트는 그 메서드의 동작 결과가 비즈니스 결과로 재귀적으로 도달할 수 있는지와 관련있다. 구현 세부 사항은 비즈니스 결과에 재귀적으로 도달할 수 없다. Mock을 사용해도 좋은 경우는 클라이언트의 요청을 달성하기 위해 어플리케이션이 외부 시스템과 통신하고, 이 때의 통신 결과로 사이드 이펙트가 외부 환경에서 보일 때만 사용하는 것이 좋다.
5장 정리
- 테스트 대역은 테스트에서 가짜 의존성 역할을 하는 녀석들이다. 크게 Mock, Stub이 존재한다.
- Mock은 외부로 나가는 상호 작용 모방과 검증에 도움이 된다.
- Stub은 내부로 들어오는 상호 작용에 도움이 된다.
- Stub과의 상호 작용을 검증하면 취약한 테스트가 된다. Stub의 상호 작용은 일반적으로 중간 단계이므로 세부 구현 사항에 해당된다.
- 공개 API와 식별할 수 있는 동작을 일치시키는 것이 좋은 API 설계가 된다.
- 식별할 수 있는 동작은 다음 두 가지 중 하나를 만족시키는 것이다.
- 클라이언트가 목표를 달성하는데 도움이 되는 연산을 노출하라. 연산은 계산을 수행하거나 사이드 이펙트를 초래하거나 둘다 하는 메서드다.
- 클라이언트가 목표를 달성하는 데 도움이 되는 상태를 노출하라. 상태는 시스템의 현재 상태다.
- 캡슐화는 코드를 불변성 위반으로부터 보호하는 행위다. 구현 세부 사항을 노출하면 캡슐화가 위반되는 경우가 종종 있다.
- 육각형 아키텍쳐는 도메인 / 어플리케이션 서비스 계층으로 분리되어있다.
- 육각형 아키텍쳐는 다음을 강조한다.
- 도메인 / 어플리케이션 계층 간의 영향 분리. 도메인 계층은 비즈니스 로직을 책임져야 하고, 어플리케이션 서비스는 도메인 계층과 외부 어플리케이션 간의 작업을 조정해야한다.
- 서비스 계층에서 도메인 계층으로의 단방향 의존성 흐름. 도메인 계층 내 클래스는 서로에게만 의존해야함.
- 외부 어플리케이션은 어플리케이션 서비스 계층으로만 접근 가능하고, 도메인 계층에는 직접 접근할 수 없다.
- 육각형의 각 계층은 식별할 수 있는 동작을 나타내며, 각각의 세부 구현 사항이 있다.
- 시스템 내부 통신 / 시스템 간 통신이 있다. 시스템 내부 통신은 클래스 간 통신이다. 시스템 내부 통신은 세부 구현 사항을 나타내고, 시스템 내부 통신과 테스트가 결합하면 취약한 테스트가 된다.
- 어플리케이션을 통해서만 접근할 수 있는 외부 시스템과의 통신도 구현 세부 사항이 된다. 왜냐하면 그 결과의 사이드 이펙트를 외부에서 확인할 수 없기 때문이다.
- 시스템 내 통신을 검증하고자 Mock을 사용하면 취약한 테스트가 된다.
'Test' 카테고리의 다른 글
| Unit Testing 7장: 가치 있는 단위 테스트를 위한 리팩토링 (0) | 2023.03.19 |
|---|---|
| Unit Testing 6장 : 단위 테스트 스타일 (0) | 2023.03.18 |
| Unit Testing : 4. 좋은 단위 테스트의 4대 요소 (0) | 2023.03.01 |
| Unit Testing : 3. 단위 테스트 구조 (0) | 2023.02.28 |
| JUnit in Action : 6. 스텁을 활용한 포괄적인 테스트 (0) | 2023.02.28 |