
Kafka Streams : 프로세서 API
- Kafka eco-system / KafkaStreams
- 2022. 11. 14.
- 6.1 더 높은 수준의 추상화와 더 많은 제어 사이의 트레이드 오프
- 6.2 토폴로지를 만들기 위해 소스, 프로세서, 싱크와 함께 작업하기
- 6.3 주식 분석 프로세서로 프로세서 API 자세히 살펴보기
- 6.4 코그룹 프로세서
- 6.4.5 또 다른 펑츄에이터 구현
- 6.5 프로세서 API와 카프카 스트림즈 통합하기
- Kafka Streams in action 6장 요약
- 참고 코드
이 글은 Kafka Streams in action 6장을 공부하며 작성한 글입니다.
6.1 더 높은 수준의 추상화와 더 많은 제어 사이의 트레이드 오프
카프카 스트림즈 DSL을 이용하면 손 쉬운 방법으로 레코드를 처리해서 전달할 수 있다. 대부분의 경우에 카프카 스트림즈 DSL을 유용하게 사용할 수 있지만, 카프카 스트림즈 DSL로 구현을 할 수 없는 경우가 있다. 이런 경우에는 카프카 스트림즈의 Processor API를 사용하면 된다.
카프카 스트림즈 Processor API는 Java 코드를 이용해서 개발자가 직접 구현을 해야하기 때문에 구현 난이도는 올라가지만 그만큼 다양한 기능을 개발할 수 있다. 카프카 스트림즈의 Processor API는 다음과 같은 경우에 사용하면 좋다고 한다.
- 일정한 간격(Timestamp, Wall Clock Time)으로 액션을 스케쥴링
- 레코드의 Down Stream 전송시점 완벽히 제어
- 특정 자식 노드에만 레코드 전달
- 카프카 스트림즈 API(DSL)에 없는 기능 구현
6.2 토폴로지를 만들기 위해 소스, 프로세서, 싱크와 함께 작업하기
다음 Topology를 Processor API를 이용해서 직접 구현해보고자 한다. 카프카 스트림즈 DSL을 사용할 때, 결과물은 항상 KStream이나 KTable이었다. 그렇지만 ProcessorAPI를 이용하는 경우에는 항상 동일한 Topology를 반환한다. 카프카 스트림즈 DSL과 카프카 스트림즈 Processor API를 사용할 때의 차이점은 다음과 같다.
| 내용 | DSL | Processor API |
| 결과물 | KStream, KTable | Topology |
| Node 이름 | 자동 작성 | 직접 지정 |
| 자식 Node, 부모 Node | 자동 작성 | 직접 지정 |
| Serde | Serde 제공 | 직렬화기, 역직렬화기 각각 제공 |
기본적으로는 위와 같은 차이가 존재한다. Node 이름은 직접 지정해야하는데 이것은 부모 ↔ 자식 노드를 서로 이어주기 위해서 필요하다. 카프카 스트림즈 Processor API는 저수준의 추상화를 이용하기 때문에 Serde 대신 직접 직렬화기 / 역직렬화기를 제공해야한다. 또한 부모 / 자식 노드 간의 관계 역시 직접 설정해야한다. 그렇지만 필요한 기능을 직접 개발할 수 있기 때문에 이 부분의 장점이 존재한다.
6.2.1. 소스 노드 추가
BEER_TOPIC에서 메세지를 읽어오는 소스 노드를 작성한다.
Topology topology = new Topology();
String domesticSalesSink = "domestic-beer-sales";
String internationalSalesSink = "international-beer-sales";
String purchaseSourceNodeName = "beer-purchase-source";
String purchaseProcessor = "purchase-processor";
topology.addSource(EARLIEST,
purchaseSourceNodeName,
new UsePartitionTimeOnInvalidTimestamp(),
stringSerde.deserializer(),
beerPurchaseSerde.deserializer(),
BEER_TOPIC)- 어디서부터 읽어올지를 직접 지정한다.
- Source 노드 이름을 설정한다
- TimeStampExtractor를 설정한다.
- Key, Value에 대한 역직렬화기를 각각 제공한다.
- 읽어올 토픽을 설정한다.
코드는 위와 같이 작성할 수 있다.
6.2.2 프로세서 노드 추가
위의 소스에서 읽어온 메세지는 달러로 판매된 매출과 파운드/유로로 판매된 매출이 존재한다. 이 부분을 Processor를 이용해서 달러로 판매되었으면 국내 판매액, 파운드 / 유로로 판매되었으면 국제 판매액으로 처리하고 각각의 노드로 보내주는 프로세서를 구현해야한다.
topology.addSource(EARLIEST,
purchaseSourceNodeName,
new UsePartitionTimeOnInvalidTimestamp(),
stringSerde.deserializer(),
beerPurchaseSerde.deserializer(),
BEER_TOPIC)
.addProcessor(purchaseProcessor,
() -> new BeerPurchaseProcessor(domesticSalesSink, internationalSalesSink), // get() 메서드에서 항상 새로운 타입을 생성해야함.
purchaseSourceNodeName)- ProcessorSupplier.get() 메서드를 이용해서 Processor를 제공해야한다.
- 이 때 Singleton Processor를 전달하는 경우 에러가 발생한다. 각 StreamTask가 각각의 Processor를 이용해야하기 때문인 것으로 생강된다.
- addProcessor()의 마지막 파라메터는 부모 노드의 이름이다. 여기서 자식 ↔ 부모 간의 관계가 설정된다.
위의 코드에서는 기본적으로 addProcessor() 메서드를 이용해서 프로세서를 전달하는 역할을 한다. 아래는 BeerPurhcaseProcessor 클래스 코드다.
public class BeerPurchaseProcessor extends ContextualProcessor<String, BeerPurchase, String, BeerPurchase> {
private String domesticSalesNode;
private String internationalSalesNode;
public BeerPurchaseProcessor(String domesticSalesNode, String internationalSalesNode) {
this.domesticSalesNode = domesticSalesNode;
this.internationalSalesNode = internationalSalesNode;
}
@Override
public void process(Record<String, BeerPurchase> record) {
BeerPurchase value = record.value();
Currency transactionCurrency = value.getCurrency();
if (transactionCurrency != DOLLARS) {
BeerPurchase dollarBeerPurchase;
BeerPurchase.Builder builder = BeerPurchase.newBuilder(value);
double internationalSaleAmount = value.getTotalSale();
String pattern = "###.##";
DecimalFormat decimalFormat = new DecimalFormat(pattern);
builder.currency(DOLLARS);
builder.totalSale(Double.parseDouble(decimalFormat.format(transactionCurrency.convertToDollars(internationalSaleAmount))));
dollarBeerPurchase = builder.build();
Record<String, BeerPurchase> nextRecord = new Record<>(record.key(), dollarBeerPurchase, record.timestamp(), record.headers());
super.context().forward(nextRecord, "hello-1");
}else{
super.context().forward(record, "hello-2");
}
}
}- 교재에서는 AbstractProcessor를 extends 해야했지만, 최근에는 ContextualProcessor를 extends 해야한다.
- 로직을 통해서 국내 매출 / 국외 매출을 분리한다.
- super.context().forward()를 통해서 downstream으로 메세지를 전달한다. 이 때, 메세지를 받을 자식 노드를 표기할 수 있다.
- 여기서 "hello-1", "hello-2"는 자식 노드의 이름이다.
- context()는 ProcessorContext를 반환한다. ProcessorContext는 StreamTask가 실행하는 init() 메서드에서 주입된다.
- 만약 자식 노드를 설정하지 않으면, 모든 자식 노드에게 메세지가 전달된다.
6.2.3 싱크 노드 추가
프로세서에게서 메세지를 전달받고 그것을 Kafka Broker에게 전달하려면 싱크 노드를 구현해야한다. 앞서 구현한 국내 / 국외 매출 처리 Processor에서 전달받은 메세지를 Broker로 전달하는 Topology 를 구성한다.
.addSink(internationalSalesSink,
"international-sales",
stringSerde.serializer(),
beerPurchaseSerde.serializer(),
purchaseProcessor)
.addSink(domesticSalesSink,
"domestic-sales",
stringSerde.serializer(),
beerPurchaseSerde.serializer(),
purchaseProcessor)- addSink() 메서드를 이용해서 SinkNode를 구현한다.
- SinkNode 이름을 작성하고, 부모 노드를 지정해준다.
- SinkNode에게는 직렬화기를 제공해야한다.
위와 같이 싱크 노드를 구현해줄 수 있다. 부모 Processor가 메세지를 선택적으로 전달하도록 context().forward()에서 지정했다면 자식 노드는 특정한 메세지만 받는다. 만약 그렇게 지정하지 않았을 경우 부모 Processor에게서 전달되는 모든 메세지가 자식 노드로 전달된다. 그리고 이 녀석은 Kafka Broker 쪽으로 메세지를 쏴준다.
6.3 주식 분석 프로세서로 프로세서 API 자세히 살펴보기
책에는 이런저런 내용이 적혀있는데 사실 크게 의미 있는 내용은 아니다. 다음 조건을 만족하는 Kafka Streams 프로세서를 생성한다는 내용이다.
- 이 주식의 현재 가치 조회
- 주식 가치가 상승, 하강 추세인지 표시
- 지금까지 총 주식 거래량과 상승, 하강 추세 여부 포함
- 추세 변동이 2%인 주식만 레코드를 다운 스트림에 전송
- 계산하기 전에 주식의 최소 샘플 20개를 수집
위의 내용을 종합해서 살펴보면 다음의 작업이 필요한 것을 알 수 있다.
- 내가 원할 때만 레코드를 다운 스트림에 전송한다.
- 상태를 기억한다.
위의 내용을 해결하기 위해서 StateStore와 Puncuate 기능을 이용해야한다.
6.3.1 주식 성과 프로세서 Application
토폴로지는 아래와 같이 작성할 수 있다. 살펴볼만한 점은 다음과 같다.
- StateStore를 생성해서 addStateStore를 하고, 이 때 사용할 Processor의 이름을 명시해준다.
- StateStore는 먼저 StoreSupplier를 생성한다음 Builder에게 전달한다. Supplier는 생성자와 비슷한 역할을 한다고 보면 된다.
- Processor를 생성할 때는 매번 새로운 Processor가 전달될 수 있도록 한다. 이것은 StreamTask마다 서로 다른 Processor를 가지고 일하기 위함이다.
Topology topology = new Topology();
String stocksStateStore = "stock-performance-store";
double differentialThreshold = 0.02;
KeyValueBytesStoreSupplier storeSupplier = Stores.inMemoryKeyValueStore(stocksStateStore);
StoreBuilder<KeyValueStore<String, StockPerformance>> keyValueStoreStoreBuilder = Stores.keyValueStoreBuilder(storeSupplier, stringSerde, stockPerformanceSerde);
topology
.addSource(EARLIEST,
"stocks-source",
stringSerde.deserializer(),
stockTransactionSerde.deserializer(),
"stock-transactions")
.addProcessor("stocks-processor",
() -> new StockPerformanceProcessorRetry(stocksStateStore, differentialThreshold),
"stocks-source")
.addStateStore(keyValueStoreStoreBuilder,
"stocks-processor")
.addProcessor("printer",
new KStreamPrint<>((key, value) -> System.out.println("key = " + key + " value = " + value)), "stocks-processor")
.addSink("stocks-sink",
"stock-performance",
stringSerde.serializer(), stockPerformanceSerde.serializer(),
"stocks-processor");
6.3.2 Processor
Processor는 다음과 같이 생성할 수 있다.
생성자
생성자에는 기본적으로 여기서 사용할 필드를 작성해야한다. Processor가 생성되는 당시에는 StreamTask에 의해서 ProcessorContext가 주입되지 않기 때문에 사용할 필드 정도만 주입 받도록 한다.
초기화
StreamTask는 init() 메서드를 이용해서 Processor를 초기화해준다. 이 때, ProcessorContext가 주입된다. 이 때 StateStore, puncuate와 관련된 내용들을 설정할 수 있다.
- stateStore를 필드 변수로 지정한다.
- context.schedule() 메서드를 이용해서 puncuator() 실행을 예약한다.
punctuator를 이용해서 downstream으로 메세지를 내려줄 것이기 때문에 punctuator 내에서 context.forward() 메서드를 이용해야한다.
process
process() 메서드에서는 StockTransaction을 전달받아서 주식성과 객체를 생성하는 작업을 한다.
- StockTransaction에서 symbol을 가져온다.
- symbol을 StateStore에 검색한다. 없는 경우 하나 새로 만들어준다.
- 20회 이상 거래된 경우 계산을 업데이트한다.
이 때 context.forward() 객체를 호출하지는 않는다. 왜냐하면 특정 시간마다 흐르는 것을 원하기 때문이다. 이곳에서 foward() 메서드를 호출할 경우, 전달되는 레코드마다 downstream으로 전달되어 원하는 조건을 만족할 수 없게 된다.
public class StockPerformanceProcessorRetry extends ContextualProcessor<String, StockTransaction, String, StockPerformance> {
private KeyValueStore<String, StockPerformance> keyValueStore;
private final String stateStoreName;
private final double differentialThreshold;
public StockPerformanceProcessorRetry(String stateStoreName, double differentialThreshold) {
this.differentialThreshold = differentialThreshold;
this.stateStoreName = stateStoreName;
}
@Override
public void init(ProcessorContext<String, StockPerformance> context) {
super.init(context);
// Processor가 초기화 될 때, 셋팅한다.
keyValueStore = context.getStateStore(stateStoreName);
StockPerformancePunctuatorRetry punctuatorRetry = new StockPerformancePunctuatorRetry(keyValueStore, context, differentialThreshold);
context.schedule(Duration.ofSeconds(15), WALL_CLOCK_TIME, punctuatorRetry);
}
@Override
public void process(Record<String, StockTransaction> record) {
StockTransaction stockTransaction = record.value();
String newKey = stockTransaction.getSymbol();
if (newKey == null) {
return;
}
StockPerformance stockPerformance = keyValueStore.get(newKey);
if (stockPerformance == null) {
stockPerformance = new StockPerformance();
}
stockPerformance.updatePriceStats(stockTransaction.getSharePrice());
stockPerformance.updateVolumeStats(stockTransaction.getShares());
stockPerformance.setLastUpdateSent(Instant.now());
keyValueStore.put(newKey, stockPerformance);
}
}6.3.3 punctuator
punctuator는 메세지를 모았다가 필요한 시점에 한번에 downstream으로 내려줄 수 있도록 기능을 구현했다. 그리고 이녀석은 processorContext()에 schedule되어있다. Stream Thread는 taskManager를 통해 Stream Task process가 끝난 이후에 punctuator가 실행 가능한지 확인하고 실행한다. 이곳에서는 크게 두 가지 작업을 한다.
- downstream으로 메세지를 내려보내도 되는지 확인한다. 이 때 상승 / 하강의 비율이 threshold보다 크면 downstream으로 전달 가능하다.
- 전달 가능한 메세지들을 context.forward()를 이용해서 흘려보내주면 된다.
punctuator의 중요한 장점은 commit(), flush() 등을 호출하지 않아도 레코드의 전달 시기를 정의할 수 있다는 것이다.
public class StockPerformancePunctuatorRetry implements Punctuator {
private KeyValueStore<String, StockPerformance> keyValueStore;
private ProcessorContext context;
private double differentialThreshold;
public StockPerformancePunctuatorRetry(KeyValueStore<String, StockPerformance> keyValueStore, ProcessorContext context, double differentialThreshold) {
this.keyValueStore = keyValueStore;
this.context = context;
this.differentialThreshold = differentialThreshold;
}
@Override
public void punctuate(long timestamp) {
KeyValueIterator<String, StockPerformance> iterator = keyValueStore.all();
while (iterator.hasNext()) {
KeyValue<String, StockPerformance> keyValue = iterator.next();
String key = keyValue.key;
StockPerformance value = keyValue.value;
if (value != null) {
if (value.priceDifferential() >= differentialThreshold || value.volumeDifferential() >= differentialThreshold) {
Record<String, StockPerformance> record = new Record<String, StockPerformance>(key, value, timestamp);
context.forward(record);
}
}
}
}
}
6.4 코그룹 프로세서
다른 프로세서에서 같은 키를 이용해 Join을 처리할 수도 있다. 그렇지만 Processor API를 이용하면 Join을 이용하지 않아도 여러 객체를 Aggregate 하는 역할을 할 수 있다. CoGroup Processor라고 이야기 할 수 있다. 말로만 하면 무슨 내용인지 잘 알 수 없느니 그림으로 살펴보면 다음과 같다.

각각의 Source에서 StockTransaction / ClickEvent 레코드를 받아온다. 그리고 레코드를 전달받은 각각의 Processor들은 Tuple<StockTx, ClickEvent> 객체를 생성해서 CoGroup Processor에게 전달한다. CoGroup Processor는 전달받은 Tuple 객체를 바탕으로 Aggregate 처리를 한다. 그렇다면 Aggregate 처리는 어떻게 할까?
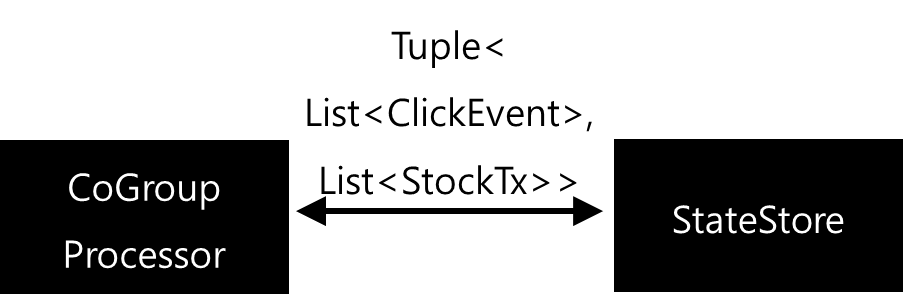
Cogroup Processor는 StateStore를 가진다. 그리고 이 StateStore는 KeyValue 저장소인데, 특정 Key에 대해서 Values는 Tuple을 List 형태로 가지게 된다. 특정 Key에 대해서 Tuple 값이 도착하면, KeyValue 저장소에서 값을 읽어온 후 Tuple의 List에 각각 추가하는 형식이 된다.
여기서 한 가지 주의해야할 점은 이것이다.
Cogroup-Processor는 모든 레코드가 도착하길 기다리지 않는다.
예를 들어 StockTxProcessor에 레코드가 전달되면, 이 레코드는 Tuple 객체를 생성한다. 생성된 Tuple 객체는 ClickEvent가 존재하지 않는 상황이다. 이 Tuple 객체는 Cogroup Processor에 전달될 것이고, Cogroup Processor는 해당 Key에 대한 Tuple<List, List> 객체를 불러올 것이다. 그리고 Tuple의 List<StockTransaction>에 값을 추가하고 StateStore에 값을 보관하게 될 것이다. 결론은 CoGroup Processor 역시 In-depth first하게 동작할 것이라는 거다.
6.4.1 토폴로지 생성
토폴로지는 아래 코드처럼 생성한다.
- stock-transactions, events 토픽으로부터 레코드를 받아오는 Source Node를 2개를 추가한다.
- 2개의 Source Node에서 메세지를 받아 Tuple을 생성하는 프로세서를 2개 생성한다.
- Tuple 생성하는 프로세서 2개로부터 데이터를 받아 StateStore에 보관하고, 펑츄에이션하는 CoGrouping-Processor를 생성한다.
- CoGrouping-Processor에서 사용할 StateStore를 추가한다.
- Cogrouping-Processor에서 처리한 결과를 보관할 Sink 토픽을 생성한다.
topology.addSource(EARLIEST
, "Txn-source",
stringSerde.deserializer(),
stockTransactionSerde.deserializer(),
"stock-transactions")
.addSource(EARLIEST,
"Events-source",
stringSerde.deserializer(),
clickEventSerde.deserializer(),
"events")
.addProcessor("Txn-processor",
StockTransactionProcessor::new,
"Txn-source")
.addProcessor("Events-Processor",
ClickEventProcessor::new,
"Events-source")
.addProcessor("CoGrouping-Processor",
() -> new CogroupingProcessor(storeName),
"Txn-processor", "Events-Processor")
.addStateStore(keyValueStoreStoreBuilder, "CoGrouping-Processor")
.addSink("Tuple-sink",
"cogrouped-results", stringSerde.serializer(), tupleSerde.serializer(),
"CoGrouping-Processor");
KafkaStreams kafkaStreams = new KafkaStreams(topology, props);
kafkaStreams.start();
6.4.2 각 프로세서 생성
StockTransactionProcessor를 생성한다.
- 소스 노드에서 StockTransaction 객체를 받아온다.
- 받아온 StockTransaction 객체를 Tuple<ClickEvents, StockTransaction> 객체로 바꾼 후 downstream으로 보낸다.
public class StockTransactionProcessor extends ContextualProcessor<String, StockTransaction, String, Tuple<ClickEvent, StockTransaction>> {
@Override
public void process(Record<String, StockTransaction> record) {
String key = record.key();
StockTransaction value = record.value();
if (key == null) {
return;
}
Tuple<ClickEvent, StockTransaction> tuple = Tuple.of(null, value);
Record<String, Tuple<ClickEvent, StockTransaction>> generatedRecord = new Record<String, Tuple<ClickEvent, StockTransaction>>(key, tuple, record.timestamp());
context().forward(generatedRecord);
}
}
ClickEventProcessor를 생성한다.
- 소스 노드에서 ClickEvent 객체를 받아온다.
- 받아온 ClickEvent 객체를 Tuple<ClickEvents, StockTransaction> 객체로 바꾼 후 downstream으로 보낸다.
public class ClickEventProcessor extends ContextualProcessor<String, ClickEvent, String, Tuple<ClickEvent, StockTransaction>> {
@Override
public void process(Record<String, ClickEvent> record) {
String key = record.key();
ClickEvent clickEvent = record.value();
if (key == null) {
return;
}
Tuple<ClickEvent, StockTransaction> tuple = Tuple.of(clickEvent, null);
Record<String, Tuple<ClickEvent, StockTransaction>> generatedRecord = new Record<String, Tuple<ClickEvent, StockTransaction>>(key, tuple, record.timestamp());
context().forward(generatedRecord);
}
}CogroupingProcessor를 구현한다
- 초기화 과정에서 펑츄에이터를 생성하고 펑츄에이션을 지정한다.
- Process()에서는 Aggregator 하는 작업만 진행한다. 실제 donwstream은 펑츄에이터에서 처리한다.
- 전달받은 Tuple 객체의 Key로 StateStore에서 값을 조회한다.
- StateStore는 Tuple<List, List> 형식이다. 이 곳에 같은 Key를 가진 녀석들인 경우 각 List에 추가한다. 즉, 이곳에서 집계가 이루어지고 있다.
public class CogroupingProcessor extends ContextualProcessor<String, Tuple<ClickEvent, StockTransaction>, String, Tuple<ClickEvent, StockTransaction>> {
private KeyValueStore<String, Tuple<List<ClickEvent>, List<StockTransaction>>> keyValueStore;
public String storeName;
public CogroupingProcessor(String storeName) {
this.storeName = storeName;
}
@Override
public void init(ProcessorContext<String, Tuple<ClickEvent, StockTransaction>> context) {
super.init(context);
keyValueStore = context.getStateStore(storeName);
CogroupPunctuator cogroupPunctuator = new CogroupPunctuator(keyValueStore, context);
context.schedule(Duration.ofSeconds(15), STREAM_TIME, cogroupPunctuator);
}
@Override
public void process(Record<String, Tuple<ClickEvent, StockTransaction>> record) {
String key = record.key();
Tuple<ClickEvent, StockTransaction> value = record.value();
Tuple<List<ClickEvent>, List<StockTransaction>> cogroupedTuple = keyValueStore.get(key);
if (cogroupedTuple == null) {
cogroupedTuple = Tuple.of(new ArrayList<>(), new ArrayList<>());
}
if (value._1 != null) {
cogroupedTuple._1.add(value._1);
}
if (value._2 != null) {
cogroupedTuple._2.add(value._2);
}
keyValueStore.put(key, cogroupedTuple);
}
}
6.4.3 펑츄에이터 구현
CogroupPunctuator를 구현한다
- 스케쥴링 시간마다 펑츄에이터는 실행된다.
- 펑츄에이터가 실행되었을 때, StateStore에 있는 모든 값을 가져와서 조건에 만족하는 경우 downstream으로 보내주는 작업을 하도록 구현한다.
public class CogroupPunctuator implements Punctuator {
private KeyValueStore<String, Tuple<List<ClickEvent>, List<StockTransaction>>> keyValueStore;
private ProcessorContext context;
public CogroupPunctuator(KeyValueStore<String, Tuple<List<ClickEvent>, List<StockTransaction>>> keyValueStore, ProcessorContext context) {
this.keyValueStore = keyValueStore;
this.context = context;
}
@Override
public void punctuate(long timestamp) {
KeyValueIterator<String, Tuple<List<ClickEvent>, List<StockTransaction>>> iterator = keyValueStore.all();
while (iterator.hasNext()) {
KeyValue<String, Tuple<List<ClickEvent>, List<StockTransaction>>> keyValue = iterator.next();
Tuple<List<ClickEvent>, List<StockTransaction>> value = keyValue.value;
if (value != null && (!value._1.isEmpty()) && (!value._2.isEmpty())) {
Record record = new Record(keyValue.key, keyValue.value, timestamp);
context.forward(record);
}
}
}
}
6.4.4. StateStore 추가
Co-Grouped Processor에서 집계에 사용할 녀석을 작성한다. StateStore는 여러 StreamTask(예를 들어 파티션이 나누어진 경우)에서 사용될 녀석이기 때문에 StateStore 자체를 제공해야하는 것이 아니라 StateStore를 생성할 수 있는 Supplier를 제공해야한다.
- StateStore에서 사용할 설정값을 제공한다.
- Stores.persistentKeyValueStore()를 이용해서 Supplier를 생성한다.
- 생성한 Supplier를 전달해서 StoreBuilder를 생성한다.
HashMap<String, String> changeLogProps = new HashMap<>();
changeLogProps.put("retention.ms", "120000");
changeLogProps.put("cleanup.policy", "compact, delete");
Topology topology = new Topology();
String storeName = "tupleCoGroupStore";
KeyValueBytesStoreSupplier storeSupplier = Stores.persistentKeyValueStore(storeName);
StoreBuilder<KeyValueStore<String, Tuple<List<ClickEvent>, List<StockTransaction>>>> keyValueStoreStoreBuilder =
Stores.keyValueStoreBuilder(storeSupplier, stringSerde, tupleSerde).withLoggingEnabled(changeLogProps);
6.4.5 또 다른 펑츄에이터 구현
앞서서는 Punctuator 인터페이스를 구현하는 형태로 펑츄에이터를 구현했다. 그렇지만 실제로는 펑츄에이터 인터페이스를 구현하지 않아도, 프로세서 내부에서 해결할 수 있다.
- 프로세서 내부에서 펑츄에이터 역할을 할 메소드를 개발한다.
- 펑츄에이터 인터페이스를 생성하고, 람다식으로 작성한다.
- 람다식을 작성하면 this::펑츄에이터 형태로 작성할 수 있다.
public class CogroupingProcessorWithPunctuator extends ContextualProcessor<String, Tuple<ClickEvent, StockTransaction>, String, Tuple<ClickEvent, StockTransaction>> {
private KeyValueStore<String, Tuple<List<ClickEvent>, List<StockTransaction>>> keyValueStore;
public String storeName;
public CogroupingProcessorWithPunctuator(String storeName) {
this.storeName = storeName;
}
@Override
public void init(ProcessorContext<String, Tuple<ClickEvent, StockTransaction>> context) {
super.init(context);
keyValueStore = context.getStateStore(storeName);
// this:cogroup으로 펑츄에이터 처리함.
context.schedule(Duration.ofSeconds(15), STREAM_TIME, this::cogroup);
}
...
public void cogroup(long timestamp) {
KeyValueIterator<String, Tuple<List<ClickEvent>, List<StockTransaction>>> iterator = keyValueStore.all();
while (iterator.hasNext()) {
KeyValue<String, Tuple<List<ClickEvent>, List<StockTransaction>>> keyValue = iterator.next();
Tuple<List<ClickEvent>, List<StockTransaction>> value = keyValue.value;
if (value != null && (!value._1.isEmpty()) && (!value._2.isEmpty())) {
Record record = new Record(keyValue.key, keyValue.value, timestamp);
context().forward(record);
}
}
}
}
6.5 프로세서 API와 카프카 스트림즈 통합하기
앞서 배운 것처럼 카프카 스트림즈에는 DSL과 Processor API가 존재한다. DSL은 고수준 추상화가 되어있어 사용하기에 편리하지만 자유도는 제한적이다. 반면 Processor API는 저수준 추상화가 되어있기 때문에 사용하는데는 다소 불편할 수 있으나 많은 자유도를 보장한다. 그리고 카프카 스트림즈는 DSL과 Processor API를 함께 쓸 수 있도록 해준다.
- KStream.process() : 일반적인 Processor API 이용. StateStore / Punctuator 모두 가능함.
- KStream.processValues() : transformValues 같은 것들에 사용함.
위 명령어들에 Kafka Streams의 Processor API 기능을 개발해서 넣어주는 방법으로 접근할 수 있다. 이 때는 펑츄에이터 시멘틱도 제공한다. 아래 예시를 살펴볼 수 있다.
- 기본적으로 아래 예시는 DSL을 사용하도록 했다. StreamBuilder를 이용하기 때문이다.
- StreamBuilder 사이에 Process()를 넣었다. 그리고 이곳에서 StateStore를 사용할 수 있도록 StateStore도 추가했다.
그렇다면 Processor는 어떻게 구현할까?
public static void main(String[] args) {
Properties initProperty = new Properties();
Properties props = InitProducerProperty.initProperty(initProperty);
props.setProperty(StreamsConfig.APPLICATION_ID_CONFIG, UUID.randomUUID().toString());
props.setProperty(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
GsonSerializer<StockTransaction> stockTransactionGsonSerializer = new GsonSerializer<>();
GsonDeserializer<StockTransaction> stockTransactionGsonDeserializer = new GsonDeserializer<>(StockTransaction.class);
Serde<StockTransaction> stockTransactionSerde = Serdes.serdeFrom(stockTransactionGsonSerializer, stockTransactionGsonDeserializer);
Serde<String> stringSerde = Serdes.String();
StreamsBuilder builder = new StreamsBuilder();
String storeName = "hello-store";
KeyValueBytesStoreSupplier storeSupplier = Stores.inMemoryKeyValueStore(storeName);
StoreBuilder<KeyValueStore<String, StockTransaction>> keyValueStoreStoreBuilder = Stores.keyValueStoreBuilder(storeSupplier, stringSerde, stockTransactionSerde);
builder.addStateStore(keyValueStoreStoreBuilder);
builder
.stream("stock-transactions",
Consumed.with(stringSerde, stockTransactionSerde).withOffsetResetPolicy(EARLIEST))
.process(() -> new MyStockTransactionProcessorWithPunctuator(storeName), storeName)
.print(Printed.toSysOut());
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), props);
kafkaStreams.start();
}Processor도 동일하게 구현할 수 있다. 앞에서 봤던 Processor API와 동일한 형태로 구현했고, Punctuator 역시 동일하게 구현했다.
public class MyStockTransactionProcessorWithPunctuator extends ContextualProcessor<String, StockTransaction, String, StockTransaction> {
private KeyValueStore<String, StockTransaction> keyValueStore;
private ProcessorContext context;
private String stateStoreName;
public MyStockTransactionProcessorWithPunctuator(String stateStoreName) {
this.stateStoreName = stateStoreName;
}
@Override
public void init(ProcessorContext<String, StockTransaction> context) {
super.init(context);
this.context = context;
keyValueStore = context.getStateStore(stateStoreName);
context.schedule(Duration.ofSeconds(15), WALL_CLOCK_TIME, this::myPunctuate);
}
@Override
public void process(Record<String, StockTransaction> record) {
String key = record.key();
String nextKey = "[NEXT-KEY]" + key;
keyValueStore.put(nextKey, record.value());
}
private void myPunctuate(long timeStamp) {
KeyValueIterator<String, StockTransaction> all = keyValueStore.all();
while (all.hasNext()) {
KeyValue<String, StockTransaction> next = all.next();
Record<String, StockTransaction> stringStockTransactionRecord = new Record<String, StockTransaction>(next.key, next.value, timeStamp);
context.forward(stringStockTransactionRecord);
}
}
}
Kafka Streams in action 6장 요약
- Kafka Streams DSL는 내부적으로 Processor API를 사용한다.
- 사용할 API를 결정해야 할 때, 먼저 DSL을 사용해보고 부족한 부분은 Processor API를 이용해서 통합을 고려해볼 수 있다.
참고 코드
https://github.com/chickenchickenlove/kafkastudy/tree/master/src/main/java/kafkaStreams/chapter6
'Kafka eco-system > KafkaStreams' 카테고리의 다른 글
| Kafka Streams : 카프카 스트림즈 고급 어플리케이션 (0) | 2022.11.20 |
|---|---|
| Kafka Streams : 모니터링과 성능 (0) | 2022.11.15 |
| Kafka Streams : Punctuator (0) | 2022.11.13 |
| Kafka Streams : StandBy Task (0) | 2022.11.13 |
| Kafka Streams : State의 복구 (0) | 2022.11.13 |



