
이 글은 Kafka Streams In Action을 공부하며 작성한 글입니다.
들어가기 전
이전 장에서는 토폴로지를 만들었지만, 스트림에서 변환과 작업이 전혀 없는 상태였다. 스트림마다 개별 트랜잭션으로 생각했었고, 각 트랜잭션을 Join해서 데이터를 더 풍부하게 만들 생각을 하지 못했다. 이번 포스팅에서는 State(상태)라는 것을 이용하려고 한다. 또한 Join을 이용해서 데이터를 더 풍부하게 만드는 부분도 접근하고자 한다.
4.1 이벤트와 스트림
이벤트
카프카에서 이벤트는 끊임없이 발생하는 메세지와 동일하다. 주식을 예로 들면 다음과 같다.
- 10:00 : A 사의 주식을 10000주 구매
- 10:10 : A 사의 주식을 1000주 구매
- 10:20 : A 사의 주식을 100주 구매
다음과 같이 시간에 따라서 각각 발생해서 전달되기만 하는 것을 이벤트라고 볼 수 있다. 이벤트는 개별적으로 많은 정보를 가지고 있을 수도 있지만 이벤트 그 자체만으로는 결정적인 정보가 되지는 못한다. 따라서 이 부분을 보완해주는 State(상태)라는 것을 Kafka Streams는 이용한다. Stream이 흐름이라면 State는 문맥이 될 수 있다. 그냥 흘러가는 흐름에 문맥을 추가해주면서 이벤트에 의미를 더해주는 것이다.
- 10:00 : A 사의 주식을 10000주 구매
- 10:10 : A 사의 주식을 1000주 구매
- 10:20 : A 사의 주식을 100주 구매
- 10:30 : A사는 임상 3상을 통과했다는 뉴스가 발생함. (문맥)
위의 스트림에 다음과 같은 문맥을 추가하면 위의 스트림(이벤트)의 정보는 조금은 다르게 들릴 수 있다. Event에 State를 추가하면서 다양한 형태로 이해를 해볼 수 있게 되었다.
스트림은 상태가 필요하다.
스트림 처리는 기본적으로 서로 관련 없이 처리될 필요가 있는 이벤트의 지속적인 흐름을 의미할 수 있다. 이럴 때 좋은 결정을 내릴 수 있도록 문맥(State)를 추가하면 좀 더 좋은 경우가 있다. 예를 들어 '회원의 구매 점수에 따른 Point 점수' Stream이 있다고 가정해보자. 이 Stream에 누적 Point라는 State를 추가해주면, 이 Stream은 좀 더 풍부한 Stream이 된다.
4.2 카프카 스트림즈에 상태를 가진 작업 적용하기

- 구매 금액에 대한 포인트를 얼만지 계산해서 스트리밍
위와 같은 스트림이 있고, 위 스트림에서는 다음 작업만 일어났다. 이 때, 보상 프로세서에 State(상태)를 추가하면 '누적 포인트'까지 계산한 스트림을 제공해줄 수 있다. 그렇다면 어떻게 상태를 제공하고 처리할 수 있을까? 상태 제공함수는 여러가지가 있지만, transformValues()를 이용해서 처리할 수 있다.
4.2.1 transformValues()
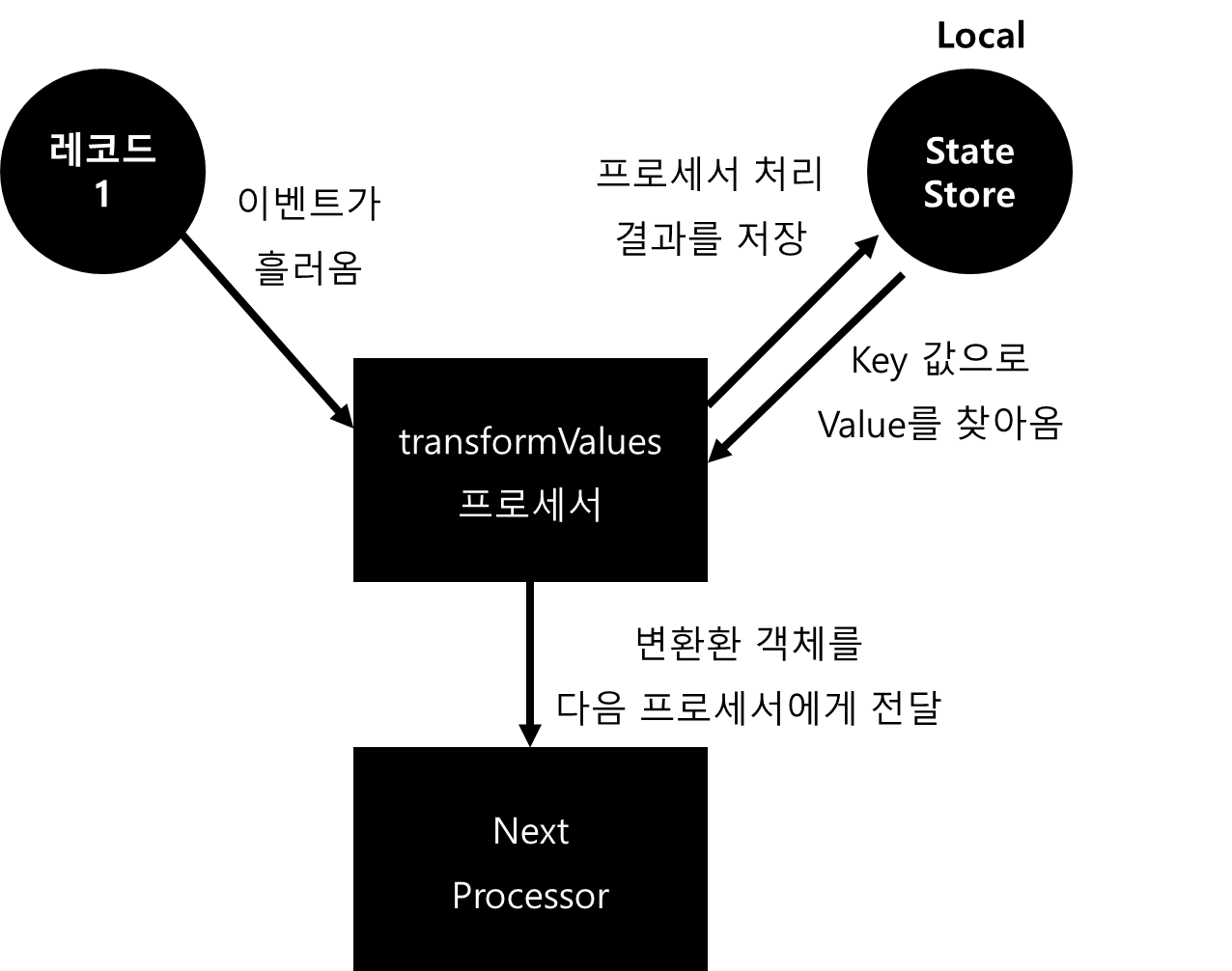
현재 많이 사용하고 있는 Kafka Streams에서는 transformValues가 deprecated 되었다. 어떤 것을 써야하는지는 다음에 알아보고 우선 교재대로 공부했다.
- Local / In Memory의 상태 저장소에 Key 값으로 검색해서 Value를 가져와서 처리한다.
- Local / In Memory의 상태 저장소에 처리한 결과를 업데이트 한다.
- 처리한 Value를 반영한 객체를 만들어서 다음 프로세서에게 준다.
transfromValues는 다음과 같은 역할을 한다. transformValues는 특정한 처리를 하고 객체를 만들어서 다음 Processor에게 전달한다는 점에서는 mapValues()와 동일한 역할을 한다. 그렇지만 이 녀석은 StateStore 객체와 통신하며 프로세싱한다는 차이점이 존재한다.
4.2.3 transformValues 클래스 생성
transformValues 클래스를 생성한다. 이 클래스는 두 가지 책임을 해야한다.
- StateStore에서 상태를 불러와서 처리하고, 처리 결과를 StateStore에 저장한다.
- StateStore에서 불러온 상태를 바탕으로 새로운 객체를 만들어서 반환한다.
public class RewardValueTransform implements ValueTransformer<Purchase, RewardAccumulator> {
private ProcessorContext context;
private KeyValueStore<String, Integer> store;
private final String storeName;
public RewardValueTransform(String storeName) {
this.storeName = storeName;
}
@Override
public void init(ProcessorContext context) {
this.context = context;
store = (KeyValueStore) this.context.getStateStore(storeName);
}
@Override
public RewardAccumulator transform(Purchase value) {
RewardAccumulator rewardAccumulator = RewardAccumulator.builder(value).build();
Integer stateValue = this.store.get(rewardAccumulator.getCustomerId());
if (stateValue != null) {
rewardAccumulator.addRewardPoints(stateValue);
}
this.store.put(rewardAccumulator.getCustomerId(), rewardAccumulator.getTotalRewardPoints());
return rewardAccumulator
}
@Override
public void close() {
}
}코드는 다음과 같이 작성할 수 있다.
- Init()를 할 때 ProcessContext가 전달된다. 이 Context에는 스트림 처리에 필요한 전반적인 녀석들이 들어있음. 주로 topology Builder에 들어간 설정값들이 존재함.
- Context에서 StateStore를 가져와서 클래스가 가지도록 한다.
- StateStore에서 값을 꺼내와서 Purchase 객체를 RewardAccumulator로 바꾼 후 반환한다.
- StateStore에서 처리 결과를 선택적으로 Put한다.
이렇게 만들면 끝이 아니다. 자세한 내용은 4.2.4에서 더 이야기 한다.
4.2.4 데이터 리파티셔닝의 필요
ProducerRecord(topic=transactions, partition=null, headers=RecordHeaders(headers = [], isReadOnly = false),
key=null,
value={"firstName":"Miriam","lastName":"Hahn",
"customerId":"243-39-2416","creditCardNumber":"6771-8937-8427-0292",
"itemPurchased":"Fantastic Wool Table","department":"Industrial",
"employeeId":"87966","quantity":4,"price":152.83,
"purchaseDate":"Oct 19, 2022, 8:25:00 AM",
"zipCode":"47197-9482","storeId":"276835"},
timestamp=null)현재 전달되고 있는 데이터는 다음과 같다. 먼저 데이터를 살펴보면 Key가 존재하지 않는다는 것을 알 수 있다. 그리고 포인트를 누적하는데 사용되는 상태의 Key값은 customerId다. 이 둘을 조합해보면 다음과 같은 사실을 알 수 있다.
- Key가 존재하지 않는 경우 Producer는 Round Robin 방식으로 파티셔닝한다.
- 현재 Key가 존재하지 않는다. 따라서 Prdocuer는 동일한 CustomerId를 여러 파티션에 집어넣을 수 있다.
위의 상황을 좀 더 눈에 보이게 살펴보면 아래와 같은 상황이 일어날 수 있다.
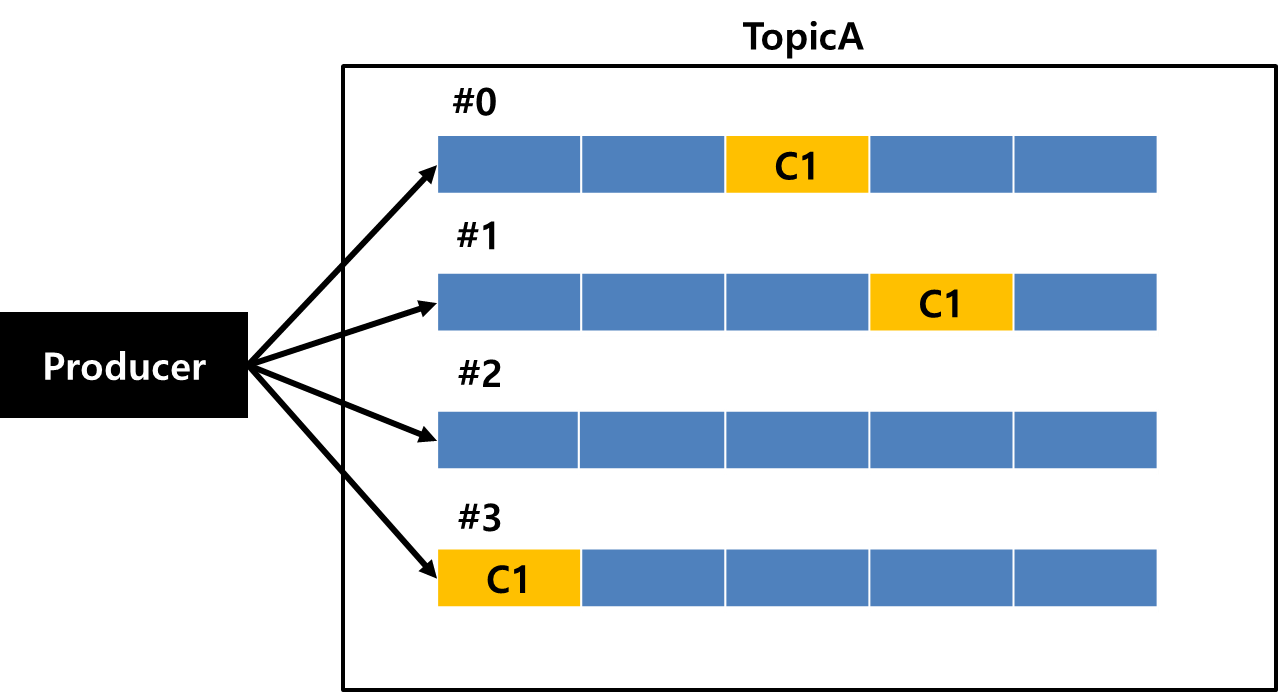
customerID가 C1이라는 녀석이 파티션 #0, #1, #3에 동시에 존재할 수 있는 것이다. StateStore는 StreamTask당 하나만 존재하고, 파티션은 StreamTask에 할당되지만, 파티션이 나눠져있기 때문에 특정 고객을 처리하는 트랜잭션이 한번에 처리되지 않는 것을 의미한다. 따라서 이 부분은 CustomerId를 Key로 이용해서 리파티셔닝이 필요하다.
4.2.4 + a 스트림 리파티셔닝 하기
Materialize this stream to an auto-generated repartition topic and create a new KStream from the auto-generated topic using key serde, value serde, StreamPartitioner, number of partitions, and topic name part as defined by Repartitioned. The created topic is considered as an internal topic and is meant to be used only by the current Kafka Streams instance. Similar to auto-repartitioning, the topic will be created with infinite retention time and data will be automatically purged by Kafka Streams. The topic will be named as "${applicationId}-<name>-repartition", where "applicationId" is user-specified in StreamsConfig via parameter APPLICATION_ID_CONFIG, "<name>" is either provided via Repartitioned.as(String) or an internally generated name, and "-repartition" is a fixed suffix.
스트림 리파티셔닝은 repartition() 메서드를 이용해서 한다. 이 메서드는 다음과 같은 설명을 가진다.
- 내부적으로 사용할 토픽을 하나 생성함.
- 생성한 토픽에 스트림으로 작성한다. 이 때, Serde + Partitioner를 이용해서 파티셔닝해서 스트림을 공급한다.
- 생성한 토픽에서 메세지를 읽어오고, 이것이 리파티셔닝된 스트림이 됨
순서를 살펴보면 다음과 같다. 내부적으로 사용할 토픽에 리파티션닝을 하고, 그 토픽을 다시 읽어서 사용한다는 것이다. 그리고 이 내부적으로 사용하는 토픽은 이 스트림을 위해서만 사용되지 다른 곳에서는 재사용되지 않는다. 그리고 이 때 생성된 토픽은 Kafka Broker에 생성된다.

다음과 같이 Kafka Broker에 라파티셔닝 된 토픽의 파티션 3개가 생성된 것을 볼 수 있다!

그림으로 살펴보면 다음과 같이 동작하는 것으로 이해할 수 있다. 그런데 이런 리파티셔닝은 가급적이면 남발하지 않는 것이 좋다고 한다. 필요하지 않은 경우에도 리파티셔닝을 하면서 오버헤드가 발생할 수 있기 때문이다. 따라서 이런 것보다는 mapValues() / transfromValues() 등을 사용하는 것이 좋다고 한다. 이것을 사용하게 되면 필요한 경우에만 리파티셔닝이 일어나기 때문에 오버헤드가 적게 발생할 수 있기 때문이다.
Repartitioned<String, Purchase> repartitioned = Repartitioned.with(stringSerde, purchaseSerde).
withNumberOfPartitions(3).withStreamPartitioner(new RewardStreamRepartitionTest());
KStream<String, Purchase> repartitionStream = purchaseKStream.repartition(repartitioned);
// StreamPartitioner
public class RewardStreamRepartitionTest implements StreamPartitioner<String, Purchase> {
@Override
public Integer partition(String topic, String key, Purchase value, int numPartitions) {
return value.getCustomerId().hashCode() % 3;
}
}Key를 사용하지 않고 리파티셔닝은 다음과 같이 할 수 있다.
- 리파티셔닝을 하기 위해서는 repartition() 메서드를 이용하고 repartitioned 객체를 생성해서 전달하면 된다.
- Key를 사용하지 않고 Round Robin을 쓰지 않은 채 파티셔닝을 하고 싶다면 Partitioner를 직접 구현해야한다. 주로 파티셔닝에 사용하고자 하는 필드의 Hash Code를 모듈러 연산해서 구할 수 있다.
KeyValueMapper<String, Purchase, String> customerIdKeyValueMapper = (key, purchase) -> purchase.getCustomerId();
Repartitioned<String, Purchase> repartitioned = Repartitioned.with(stringSerde, purchaseSerde).withNumberOfPartitions(3);
KStream<String, Purchase> repartitionStream = purchaseKStream.selectKey(customerIdKeyValueMapper).repartition(repartitioned)Key를 사용할 때는 다음과 같이 리파티셔닝 할 수 있다.
- selectKey() 메서드를 이용해서 해당 스트림의 Key를 다시 설정해 줄 수 있다.
- repartitioned() 객체를 생성해서 Serde 객체 + 파티션의 갯수를 설정해서 전달해준다.
- Stream에 repartition() 메서드를 이용해서 리파티셔닝 한다.
Key를 이용할 경우 굳이 파티셔너를 전달하지 않아도 되는 이유는 DefaulPartitioner가 특정 Key는 특정 파티션으로 배정되도록 해주기 때문이다.
4.2.5 리파티션 + StateStore 적용하기
// StateStore 처리하기
KeyValueMapper<String, Purchase, String> customerIdKeyValueMapper = (key, purchase) -> purchase.getCustomerId();
Repartitioned<String, Purchase> repartitioned = Repartitioned.with(stringSerde, purchaseSerde).withNumberOfPartitions(3);
KStream<String, Purchase> repartitionStream = purchaseKStream.selectKey(customerIdKeyValueMapper).repartition(repartitioned);
repartitionStream.transformValues(() ->
new RewardValueTransformer(STORE_NAME), STORE_NAME).to("STATE_REPARTITION",
Produced.with(stringSerde, rewardAccumulatorSerde));앞서서 작성한 코드들을 위의 코드로 적용할 수 있다.
- Key가 없어서 여러 파티션에 저장될 수 있는 녀석들을 처리하기 위해서 리파티셔닝 했다.
- 리파티셔닝 한 후, StateStore의 누적된 포인트 값을 불러와서 Purchase 객체를 RewardAccumulator 객체로 변경했다.
앞서 작성한 코드는 위와 같다. 위의 코드로 적용하기만 하면 Sink Stream이 하나가 생성된다.

그림으로 살펴보면 다음과 같이 변경된 것이다!
4.3 상태 저장소 (State Store)
상태(State)에는 크게 두 가지 중요한 부분이 있다. 바로 Data Locality(데이터 지역성)과 Fail over(실패 복구)다. 이 부분에 대해서 살펴보고자 한다.
4.3.1 데이터 지역성
StateStore는 로컬에서 사용한다. 네트워크를 통해 원격 DB를 호출하는 것보다 로컬에서 데이터를 가져오는 것이 더 효율적이기 때문이다. 또한 스트림은 한번에 수십만 건 이상의 데이터를 처리하는 경우도 있는데, 이 때 작은 네트워크 지연도 큰 영향을 불러일으킬 수 있다.
데이터 지역성은 각 처리 노드에 대해 따로 따로 동작하고, 심지어는 프로세스와 스레드 간에도 공유하지 않는다는 것을 의미한다. 이렇게 동작할 경우 하나의 프로세스가 실패하더라도 다른 스트림 프로세스에는 영향을 미치지 않는다.
4.3.2 실패 복구와 내결함성
분산 처리에서는 실패 복구가 중요하다. Kafka Streams는 State에 대한 실패 복구로 두 가지를 대신한다.
- Local State Store
- Change Log (Kafka Broker)
Change Log는 Local State Store의 백업을 위해서 Kafka Broker에 생성되는 토픽으로 이해할 수 있다. Local State Store는 레코드에 대한 최신값을 캐싱하다가 Flush() 하는 순간 KafkaProducer를 통해 Change Log에 메세지를 전송한다. 그리고 Kafka Producer는 Batch 단위로 메세지를 보내기 때문에 네트워크 비용 또한 절약된다. 또한 메세지가 ChangeLog에 저장될 때 Compact Strategy로 저장된다. 따라서 메세지를 저장하는 비용이 최소화된다.
또한 StateStore는 StreamTask 당 1개씩 배정된다. StreamTask는 쓰레드에게 배정되기 때문에 쓰레드 / 프로세스끼리 격리된 상태로 사용할 수 있다.
4.3.3 Kafka Streams에서 상태 저장소 사용하기
- Materialized : 주로 고수준 DSL 사용 시
- StoreBuilder : 저수준 Processor API로 작업 시
KafkaStreams에서 상태 저장소는 두 가지 형태로 사용할 수 있다.
KeyValueBytesStoreSupplier storeSupplier = Stores.inMemoryKeyValueStore(STORE_NAME);
StoreBuilder<KeyValueStore<String, RewardAccumulator>> keyValueStoreStoreBuilder = Stores.keyValueStoreBuilder(storeSupplier, stringSerde, rewardAccumulatorSerde);
streamsBuilder.addStateStore(keyValueStoreStoreBuilder);StoreBuilder로 StateStore를 만드는 방법은 위와 같다.
- StoreSuplier를 생성한다.
- 생성한 StoreSuplier를 StoreBuilder에게 전달한다.
- SToreBuilder를 StreamBuilder에게 전달해준다.
이렇게 생성할 경우, StreamBuild가 생성하는 topology에 stateStore는 Store이름으로 저장되어있기 때문에 언제든지 인스턴스를 불러와서 사용할 수 있다.
4.3.4. KafkaStreams에서 생성할 수 있는 키/값 State Store Supplier
KeyValueBytesStoreSupplier storeSupplier = Stores.inMemoryKeyValueStore(STORE_NAME);위의 함수를 이용해서 StateStore를 생성했었다. Stores 클래스를 이용하면 이것말고도 다양한 StateStore를 생성할 수 있다.
- Stores.persistentKeyValueStore
- Stores.persistentWindowStore
- Stores.persistentSessionStore
- Stores.lruMap
- Stores.inMemoryKeyValueStore
위의 StateStore를 추가적으로 생성할 수 있다. 여기서 PersistentStateStore는 RocksDB를 사용해서 로컬 디스크에 스토리지를 제공한다. RocksDB는 고성능 DB라고 한다.
4.3.5. StateStore의 내결함성
- 모든 StateStoreSupplier는 로깅이 활성화되어있다. 여기서 로깅은 ChangeLog를 의미한다. ChangeLog에는 StateStore의 값을 백업한다.
- 만약 Kafka Streams Server가 죽었다가 재기동되면, StateStore는 ChangeLog에 의해서 백업된다. 이 때 ChangeLog에 마지막 커밋된 오프셋으로 복원된다.
- disableLogging()을 이용해서 로깅(ChangeLog에 기록)을 비활성화 할 수 있는데, 이 경우 내결함성은 사용할 수 없게 된다.
4.3.6 ChangeLog 토픽 설정하기
ChangeLog는 StateStore의 값을 저장하고 있는 녀석이다. ChangeLog는 Kafka Broker에 저장되는 Topic인데, Topic이기 때문에 원하는 설정을 할 수 있다.
HashMap<String, String> changeLogProps = new HashMap<>();
changeLogProps.put(TopicConfig.RETENTION_MS_CONFIG, "172800000");
changeLogProps.put(TopicConfig.RETENTION_BYTES_CONFIG, "10000000");
// StoreBuilder를 사용할 때
keyValueStoreStoreBuilder.withLoggingEnabled(changeLogProps);
// Materialized를 사용할 때
Materialized.as(Stores.inMemoryKeyValueStore(STORE_NAME))
.withLoggingEnabled(changeLogProps);설정은 위와 같이 할 수 있다. 로깅을 하게 하는데, 이 때 ChangeLog에 필요한 설정값을 한 녀석을 전달해주면 된다. Kafka Streams는 ChangeLog를 생성할 때 기본적으로 Compact 전략으로 생성한다. 그렇지만 Compact를 하다가 많은 Key가 쌓이게 되면 그것 역시 부담이 될 수 있다. 이 부분을 해결하기 위해서는 Log Clean Strategy를 Delete + Compact로 처리해주면 된다.
HashMap<String, String> changeLogProps = new HashMap<>();
changeLogProps.put(TopicConfig.RETENTION_MS_CONFIG, "172800000");
changeLogProps.put(TopicConfig.RETENTION_BYTES_CONFIG, "10000000");
changeLogProps.put(TopicConfig.CLEANUP_POLICY_CONFIG, "compact, delete");이렇게 작성하면 compact를 한 후 일정 시간이나 용량이 지나면 delete 하는 형식으로 처리할 수 있게 된다.
4.4 Stream의 Join
Stream끼리의 Join은 새로운 Context를 만드는 것과 동일하다. Stream의 Join을 통해서 데이터를 좀 더 풍부하게 만들고, 이것을 의미있는 형태로 전달해줄 수 있다.
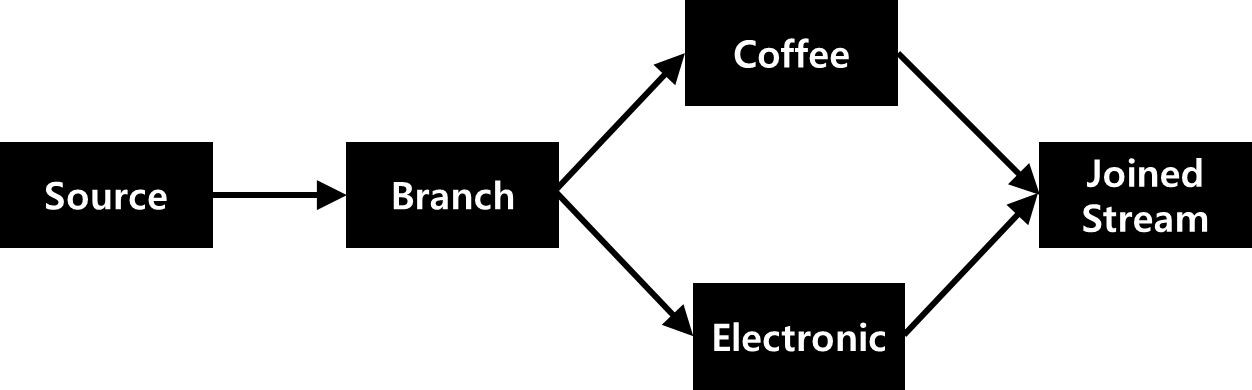
다음과 같은 형태로 Join을 한다. 이 때 Coffee와 Electornic을 Join하는 기준은 다음과 같다.
- 각 손님이 Coffee를 사고 20분 이내에 Electornic을 사는 경우
- 각 손님이 Electronic을 사고 20분 이내에 Coffee를 사는 경우
위의 경우를 만족하면 그 손님에게 커피 쿠폰을 제공하는 형태로 접근을 하고자 한다. 따라서 JoinedStream을 만드는 것은 Coffee / Electronic을 Inner Join 하고 Time Window를 20분 이내로 설정해야한다.
4.4.1 ~ 4.4.2 데이터 설정 + Key 생성
Map<String, KStream<String, Purchase>> branches = purchaseKStream.selectKey((key, value) -> value.getCustomerId()).
split(Named.as("Branch-")).
branch((key, purchase) -> purchase.getDepartment().equalsIgnoreCase("coffee"), Branched.as("coffee")).
branch((key, purchase) -> purchase.getDepartment().equalsIgnoreCase("electronics"), Branched.as("electronics")).noDefaultBranch();
KStream<String, Purchase> coffeeStream = branches.get("Branch-coffee");
KStream<String, Purchase> electronicStream = branches.get("Branch-electronics");먼저 Soruce Stream에서 브랜치 스트림으로 분기해야한다. 책에서는 분기를 위해 Branch() 메서드를 이용했으나 deprecated 되었다. 그래서 나는 split() 메서드를 이용했다.
이 때 주의해야 할 점은 Source Stream에는 Key가 없기 때문에 브랜치를 분기하는 과정에서 파티셔닝을 하게 되면 Round Robin으로 동작한다는 것이다. 따라서 하나의 CustomerId가 여러 파티션에 존재할 수 있다. 이 부분을 해결하기 위해서는 두 가지 방법으로 처리할 수 있다.
- selectKey()를 이용해서 Stream의 Key를 설정한 다음 브랜치를 분기한다.
- 분기할 때 StreamPartitioner()를 구현해서 CustomerId의 Hash 값에 모듈러 연산을 해서 파티셔닝 한다.
위에서는 selectKey()를 이용해서 구현했다.
새로운 키를 생성하는 메서드 (selectKey(), map, transform)은 호출할 때마다 내부에 Boolean Flag가 True로 설정된다. True인 경우는 새롭게 생성되는 KStream 인스턴스가 리파티셔닝이 필요하다는 것을 의미한다. 따라서 Flag가 True인 경우에는 자동으로 리파티셔닝 처리가 된다.
4.4.3 Join 구성하기
Join은 ValueJoiner를 생성하는 단계와 Join을 실행하는 단계로 나누어진다.
ValueJoiner 구현
Join을 구현하기 위해서는 ValueJoiner() 인터페이스를 클래스를 구현해야한다. ValueJoiner는 V1, V2 타입의 객체를 각각 받아서 R 타입의 객체를 반환하는 클래스가 된다. 아직까지 내부구조를 살펴보지는 않았지만 실제 동작은 다음에 가깝지 않을까 한다.
- Time Window 내에 있는 V1 / V2 타입의 모든 객체가 전달된다.
- V1에 대해 기본적으로 모든 V2가 전달된다. 따라서 하나의 V1은 모든 V2에 대해서 Joiner 객체를 생성하는 역할을 한다.
- 이 때 V1 + V2 하나의 레코드에 대해서 객체를 생성하는 역할을 하는 것이 ValueJoiner 클래스다.
위의 내용을 바탕으로 ValueJoiner 클래스를 생성하면 다음과 같다.
public class PurchaseJoiner implements ValueJoiner<Purchase, Purchase, CorrelatedPurchase> {
@Override
public CorrelatedPurchase apply(Purchase purchase1, Purchase purchase2) {
CorrelatedPurchase.Builder builder = CorrelatedPurchase.newBuilder();
String customerId1 = purchase1 != null ? purchase1.getCustomerId() : null;
Date purchaseDate1 = purchase1 != null ? purchase1.getPurchaseDate() : null;
Double purchasePrice1 = purchase1 != null ? purchase1.getPrice() : null;
String itemPurchase1 = purchase1 != null ? purchase1.getItemPurchased() : null;
String customerId2 = purchase2 != null ? purchase2.getCustomerId() : null;
Date purchaseDate2 = purchase2 != null ? purchase2.getPurchaseDate() : null;
Double purchasePrice2 = purchase2 != null ? purchase2.getPrice() : null;
String itemPurchase2 = purchase2 != null ? purchase2.getItemPurchased() : null;
ArrayList<String> purchasedItem = new ArrayList<>();
if (itemPurchase1 != null) {
purchasedItem.add(itemPurchase1);
}
if (itemPurchase2 != null) {
purchasedItem.add(itemPurchase2);
}
builder
.withCustomerId(customerId1 != null ? customerId1 : customerId2)
.withFirstPurchaseDate(purchaseDate1)
.withSecondPurchaseDate(purchaseDate2)
.withItemsPurchased(purchasedItem)
.withTotalAmount(purchasePrice1 + purchasePrice2);
return builder.build();
}
}다음과 같은 형태로 사용할 수 있다.
Join 실행하기(https://kafka.apache.org/31/javadoc/org/apache/kafka/streams/kstream/JoinWindows.html)
SELECT * FROM stream1, stream2
WHERE
stream1.key = stream2.key
AND
stream1.ts - before <= stream2.ts AND stream2.ts <= stream1.ts + after기본적으로 Join은 다음과 같이 동작한다고 한다. 즉, Stream1의 시간의 ± Window에 들어오는 Stream2 모든 녀석이 Join 대상이 된다. 이 때는 세 가지 경우를 고려할 수 있다. 이 때 JoinWindow 객체를 만들 수 있는데, JoinWindow 객체를 만들 때 사용되는 TimeDifference는 Stream1 기준으로 전/후에 적용되는 녀석이다.
- before = after = time-difference
- before = 0 and after = time-difference
- before = time-difference and after = 0
따라서 위와 같이 세가지 경우가 있을 수 있다. Before를 0으로 만들면, Stream2는 항상 Stream1보다 항상 뒷쪽에 있는 녀석만 나오게 된다. 반대로 After를 0으로 만들면 Stream2는 항상 Stream1보다 앞에 있는 녀석만 나오게 된다. 이 부분은 JoinWindow의 after() / before() 메서드를 이용해서 처리할 수 있다.
PurchaseJoiner purchaseJoiner = new PurchaseJoiner();
JoinWindows twentyMinutesWindow = JoinWindows.ofTimeDifferenceWithNoGrace(Duration.ofMinutes(20));
KStream<String, CorrelatedPurchase> joinedKStream = coffeeStream.join(
electronicStream, purchaseJoiner, twentyMinutesWindow,
StreamJoined.with(stringSerde, purchaseSerde, purchaseSerde));
joinedKStream.print(Printed.<String, CorrelatedPurchase>toSysOut().withLabel("JoinedStream"));Join은 join() 메서드를 이용해서 할 수 있다. join() 메서드에는 3개의 객체가 전달되어야 한다.
- ValueJoiner 객체 : Join을 했을 때, 어떤 객체가 반환되어야 하는지를 지정함.
- JoinWindow : 어느 기간동안의 레코드들을 Join 할지를 결정한.
- StreamJoined : Key , Value1, Value2를 처리할 Sered 제공. 없는 경우 Default값을 사용함.
위의 내용을 반영해서 위와 같은 코드를 작성할 수 있다. 이렇게 되면 Join Stream은 생성되지만, 한 가지 문제점은 Join Stream은 각 레코드들의 순서는 고려하지 않는다. 즉 20분 이내에만 있으면 모두 Join이 되는 것이다. 예를 들어 Value1이 10시에 생성되었다고 해보자. 그럼 이 때 Value1은 Window가 20분이기 때문에 09:40 ~ 10:20에 발생한 Value2들이 Value1의 조인 대상이 된다는 것을 의미한다. 그렇지만 이벤트의 순서까지 고려하고 싶을 경우가 있다. 그런 경우에는 아래의 메서드를 이용할 수 있다.
// After 메서드
JoinWindows twentyMinutesWindow = JoinWindows.ofTimeDifferenceWithNoGrace(Duration.ofMinutes(20))
.after(Duration.ofMillis(5000));
// Before 메서드
JoinWindows twentyMinutesWindow = JoinWindows.ofTimeDifferenceWithNoGrace(Duration.ofMinutes(20))
.before(Duration.ofMillis(5000));기본적으로 After / Before의 값은 TimeDifference와 동일하다. 이 때 after() 메서드를 이용하면 After가 TimeDiffence에서 해당 값으로 변경된다. 위의 상황을 바라보면 좌측 Stream을 기준으로 [- 20:00 ~ , + 00:05] 상태의 값만 우측 스트림에서 가져온다는 것을 의미한다.
Co-Partitioning(코파티셔닝)
Kafka Streams에서 Join을 하려면 Join 대상이 모두 코파티셔닝(Co-Partitioning) 되어있어야만 한다. 코파티셔닝의 의미는 다음과 같다. 단, GlobalKTable 인스턴스는 Join 할 때 리파티셔닝이 필요하지 않ㄴ다.
- Join 대상들이 동일한 Key를 가진다.
- Join 대상들이 동일한 파티션 갯수를 가진다. 파티션 갯수가 다를 경우 ToplogyBuilderException 발생함.
- Join 대상들이 동일한 파티션 분배 전략으로 파티셔닝 되어있어야한다.
코파티셔닝이 필요하기 때문에 Join을 호출하면 리파티셔닝이 필요한지 점검한다.
Map<String, KStream<String, Purchase>> branches = purchaseKStream.selectKey((key, value) -> value.getCustomerId()).
split(Named.as("Branch-")).
branch((key, purchase) -> purchase.getDepartment().equalsIgnoreCase("coffee"), Branched.as("coffee")).
branch((key, purchase) -> purchase.getDepartment().equalsIgnoreCase("electronics"), Branched.as("electronics")).noDefaultBranch();
KStream<String, Purchase> coffeeStream = branches.get("Branch-coffee");
KStream<String, Purchase> electronicStream = branches.get("Branch-electronics");위의 경우 SelectKey를 했기 때문에 coffeeStream / electronicStream은 각각 리파티셔닝이 된다.
4.4.4 그 밖의 조인 옵션
- join()
- leftJoin()
- rightJoin()
위의 메서드를 이용해서 Join을 할 수 있다. 이 때 join()은 Inner Join을 의미하고 나머지 Join은 OuterJoin을 의미한다. 각각의 출력되는 경우는 다음과 같다.
| 둘다 존재할 때 | 왼쪽만 존재할 때 | 오른쪽만 존재할 땍 | |
| join() | O | X | X |
| leftJoin() | O | O | X |
| rightJoin() | O | O | O |
여기서 이야기 하는 출력은 DownStream으로 Join 결과를 보내주는지를 의미한다.
4.5 Kafka Streams의 Timestamp(타임스탬프)
- Stream Join
- Change Log Update
- Processor.punctutate()
타임 스탬프는 위의 경우에 주로 사용된다.
| 항목 | 내용 |
| EventTime | 이벤트가 발생했을 때 설정한 타임스탬프다. 예 : ProducerRecord가 생성되었을 때의 시간 |
| Ingestion Time | 메세지가 처음으로 Log에 들어간 타임스탬프. 예 : Broker의 TopicPartition의 .log 파일에 메세지가 append된 시간. |
| Processing Time | 메세지가 처음으로 Stream에서 처리되기 시작했을 때 |
또한 타임 스탬프는 다음과 같이 3개의 종류로 나눌 수 있다.
기본적으로 TimeStamp는 서로 다른 시간대가 아닐 가능성이 높다. 왜냐하면 한국에서 발생한 데이터가 미국에서 사용될 수도 있기 때문이다. 따라서 TimeZone은 UTC 표준 시간대를 사용하는 것이 권장된다.
또한 어떤 Timestamp를 사용하고 있는지를 확인할 수 있고, 어떤 TimeStamp를 사용하도록 할지도 설정할 수 있다. 이 설정 값은 다음에서 확인하고 설정할 수 있다.
props.setProperty(StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG, FailOnInvalidTimestamp.class.getName());아래에 설정값으로 원하는 Class를 설정해줄 수 있다. 그러면 기본적으로 Kafka Streams에서는 위의 설정값을 바탕으로 처리를 해준다.
4.5.1 TimeStampExtractor
기본적으로 제공되는 TimeStampExtractor는 메세지의 메타데이터에 존재하는 TimeStamp를 추출한다. 이 TimeStamp는 Producer, Broker가 설정한 타임 스탬프다. 그리고 이 Time Stamp는 Kafka Streams가 Consumer로 메세지를 poll() 해왔을 때의 ConsumerRecord()의 TimeStamp를 가져온다.
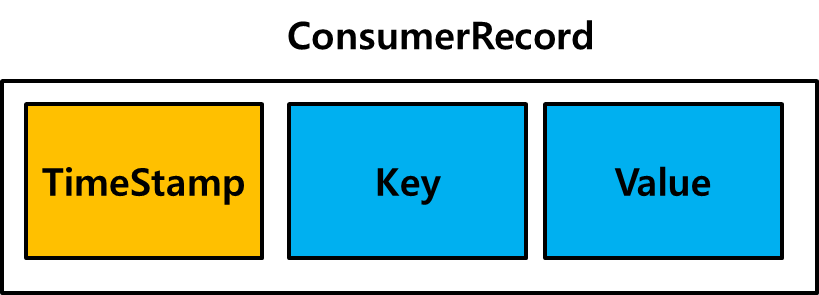
TimeExtractor는 ConsumerRecord에서 TimeStamp를 추출해온다. 기본적으로는 CreatedTime(ProducerRecord 생성 시점)을 가져온다. 그렇지만 logAppendTime(Broker의 log 파일에 저장되었을 때)를 기준으로도 사용할 수 있다.
abstract class ExtractRecordMetadataTimestamp implements TimestampExtractor {
@Override
public long extract(final ConsumerRecord<Object, Object> record, final long partitionTime) {
final long timestamp = record.timestamp();
if (timestamp < 0) {
return onInvalidTimestamp(record, timestamp, partitionTime);
}
return timestamp;
}
public abstract long onInvalidTimestamp(final ConsumerRecord<Object, Object> record,
final long recordTimestamp,
final long partitionTime);
}기본적으로 TimeExtractor는 ExtractRecordMetadataTimeStamp 추상 클래스를 구현해서 사용할 수 있다. 위의 추상 클래스의 onInvalidTimeStamp를 구현해서 사용할 수 있다.
- FailOnInvalidTimeStamp : 유효하지 않은 타임스탬프의 경우 예외를 발생시킴.
- LogAndSkipOnInvalidTimeStamp : 유효하지 않은 타임스탬프를 반환하고, 유효하지 않은 타임스탬프로 인해 레코드가 삭제된다는 경고 메세지를 남김.
- UsePreviousTimeOnInvalidTimeStamp : 유효하지 않은 타임스탬프의 경우 마지막으로 추출한 유효한 타임 스탬프를 반환함.
위는 ExtractRecordMetadataTimeStamp 추상 클래스를 구현한 TimeExtractor 클래스들이다.
4.5.2 WallclockTimeStampExtractor
이 클래스는 ConsumerRecord의 메타 데이터에서 TimeStamp를 반환하지 않는다. 대신 System.currentTimeMillis() 메서드를 호출해서 반환한다.
4.5.3 사용자 정의 TimestampExtractor
public class TransactionTimestampExtractor implements TimestampExtractor {
@Override
public long extract(ConsumerRecord<Object, Object> record, long partitionTime) {
Purchase value = (Purchase) record.value();
return value.getPurchaseDate().getTime();
}
}
사용자 정의 TimeStampExtractor는 TimestampExtractor 인터페이스를 구현해서 사용할 수 있다. 사용자 정의 TimeStampExtractor가 필요한 경우는 CreatedTime이나 logAppendTime 말고 다른 시간을 Stream 처리에 써야하는 경우다.
예를 들어 위의 경우는 메세지가 생성된 시간보다는 실제 구매 시간이 좀 더 중요하다. 따라서 스트림 처리할 때 실제 구매 시간을 Timestamp으로 뽑아서 전달해주고, 그 시간을 기준으로 처리를 할 수 있도록 해야한다.
Log의 Delete / Compact 정책은 Log의 TimeStamp를 기준으로 동작한다. 사용자 정의 설정 TimestampExtractor를 이용할 경우, 이 녀석이 제공한 타임스탬프가 ChangeLog와 DownStream Topic 메세지의 타임 스탬프가 될 수 있다. 따라서 사용자 정의 설정 타임스탬프 추출기가 생성한 타임스탬프에 따라 Log의 Delete / Compact 정책이 제공될 수 있다는 것을 의미한다.
사용자 정의 TimestampExtractor를 사용할 때 주의점은 위와 같다.
4.5.4 TimestampExtractor 명시하기
// 전역 설정
props.setProperty(StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG,
FailOnInvalidTimestamp.class.getName());
// 특정 녀석에게만 제공
streamsBuilder.stream(sourceTopic, Consumed.with(stringSerde, purchaseSerde)
.withTimestampExtractor(new TransactionTimestampExtractor()))TimeStamp는 위와 같이 전역 설정 / 개별 설정을 하는 방법이 존재한다. 개별 설정은 Consuemd.withTimestampExtractor()를 이용해서 제공할 수 있고, 개별 설정이 되면 이 녀석을 사용한다. 전역 설정을 할 때는 setProperty()를 통해서 설정해서 전달해주면 된다.
알아두기
StateStore : 파티션은 StreamTask에 할당된다. 각 StreamTask는 각각 자신의 StateStore를 가진다.
리파티셔닝 : 리파티셔닝을 수동으로 하는 것은 권장되지 않는다. 내부 토픽을 쓸데없이 많이 생성할 경우 오버헤드가 발생하기 때문이다. 이보다는 mapValues(), transformValues() 등을 이용해서 내부적으로 필요한 경우에만 리파티셔닝이 일어나도록 한다.
ChangeLog : ChangeLog는 Compact 형태로 저장된다.
StateStore의 내결함성은 ChangeLog로 구현된다. Local에서 사용되고 있는 StateStore는 캐싱하고 있는데, 이게 Flush 되는 순간 Kafka Broker에 해당 StateStore에 대한 ChangeLog가 생성된다. 이 ChangeLog는 기본적으로 Compact 형식으로 StateStore의 메세지를 저장해둔다. 만약 Kafka Streams 서버가 죽어서 StateStore가 다 날아간 경우, 재기동하면 StateStore는 ChangeLog의 최신 Key / Value 값을 읽고 마지막 Commit 상태로 복구된다.
StateStore의 지역성은 StateStore가 각 서버의 StreamTask마다 생성되는 것을 의미한다. StateStore는 각 서버의 StreamTask에 생성되기 때문에 클러스터끼리 공유해서 사용할 수 없다. 또한 StreamTask는 하나의 쓰레드가 생성하는 것이기 때문에 프로세스 / 쓰레드에게서 격리된다. 즉, StateStore는 지역성을 가진다.
StateStore는 인 메모리에 구축되는 경우도 있다. 그렇지만 Persistent 타입의 StateStore를 사용하는 경우 Local 스토리지의 일부 공간을 할당해서 RocksDB를 사용한다.
새로운 키를 생성하는 메서드 (selectKey(), map, transform)은 호출할 때마다 내부에 Boolean Flag가 True로 설정된다. True인 경우는 새롭게 생성되는 KStream 인스턴스가 리파티셔닝이 필요하다는 것을 의미한다. 따라서 Flag가 True인 경우에는 자동으로 리파티셔닝 처리가 된다.
'Kafka eco-system > KafkaStreams' 카테고리의 다른 글
| Kafka Streams : Process 과정에서의 레코드 (0) | 2022.10.30 |
|---|---|
| Kafka Streams : KTable과 Cache 내부동작 (0) | 2022.10.25 |
| KafkaStreams : StateStore (0) | 2022.10.24 |
| Kafka Streams : StreamTask가 생성되는 과정 (0) | 2022.10.22 |
| Kafka Streams : Source 토픽에서 메세지 가져오기 (0) | 2022.10.22 |



