ksqlDB : 실시간 스트림 처리의 동작 방식
- Kafka eco-system/ksqlDB
- 2022. 10. 14.
들어가기 전
Stream이라는 것은 이벤트가 도착했을 때, 이벤트를 계산하기 위한 프로그래밍 패러다임이다. 대전제는 아래와 같다.
- Kafka는 Kafka Broker에 Topic에 이벤트를 저장한다.
- ksqlDB는 Stream에 이벤트를 저장한다.
이 때 Stream이라는 것은 Persistence Query에 의해서 정의된 schema가 존재하는 Topic이다. 이 Topic 역시 Kafka Broker에 저장된다.
CREATE STREAM readings (
sensor VARCHAR KEY,
location VARCHAR,
reading INT
) WITH (
kafka_topic = 'readings',
partitions = 3,
value_format = 'json'
);이 명령어를 ksqlDB-Cli에서 실행해보자. 실행하는 순간 다음의 일이 일어난다.
- 이 스트림에 대한 토픽이 브로커에 없는 경우, ksqlDB-Sever는 Kafka Broker를 호출해서 토픽을 새로 생성한다.
- Column의 형태, 직렬화 형태 같은 Stream 메타 데이터는 ksqlDB의 Command Topic에 저장된다. (이 토픽도 생성된다)
- 각 ksqlDB-Server는 command Topic 정보를 Local Metadata 저장소로 구체화하여 저장해둔다.
하나하나 살펴보면 다음과 같다.

ksqlDB 자체를 띄우기만 했을 때는 다음 토픽만 생성된다.

그리고 Stream을 생성해도 카프카 브로커에 뭔가 새로운 것이 생기지는 않는다. 왜냐하면 위 쿼리를 사용했을 때 Persistence Query가 저장되지 않기 때문이다. 이렇게 ksqlDB 서버를 띄우고 스트림을 생성했을 때의 상태는 다음과 같다.

스트림에 행 삽입
Kafka는 레코드를 브로커에 저장해둔다. ksqlDB Server에서도 Insert 문을 이용해서 Kafka Broker에게 직접 메세지를 전달할 수 있다.
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-1', 'wheel', 45);
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-2', 'motor', 41);
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-1', 'wheel', 42);
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-3', 'muffler', 42);
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-3', 'muffler', 40);
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-4', 'motor', 43);
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-6', 'muffler', 43);
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-5', 'wheel', 41);
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-5', 'wheel', 42);
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-4', 'motor', 41);
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-7', 'muffler', 43);
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-8', 'wheel', 40);
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-9', 'motor', 40);
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-9', 'motor', 44);
INSERT INTO readings (sensor, location, reading) VALUES ('sensor-7', 'muffler', 41);위 명령어를 이용하면 ksqlDB Server는 Kafka Broker에게 메세지를 전송한다. 이 때 전송은 다음 순서로 동작한다.
- ksqlDB 서버는 스트림에 정의된 Schema에 적합한지 확인한다. 이 때 잘못된 형식은 거부된다.
- Schema에 적합하면 서버는 레코드를 만들고 스트림 선언에 사용했던 형식대로 직렬화한다.
- ksqlDB Server는 Kafka Producer를 이용해서 Kafka Broker Topic에 전송한다.
여기서 주의해야 할 점은 ksqlDB Server에서 생성한 스트림은 모두 브로커의 토픽에 저장된다는 것이다. 또 한 가지 유의할 점은 스트림을 선언하는 시점에 Key를 선언했다는 것이다.
- ksqlDB 서버는 스트림에 선언했던 Key를 바탕으로 파티셔닝을 한다.
- ksqlDB 서버는 Insert를 할 때 Key / Value 형식으로 구성된다.
이런 형식으로 동작하기 때문에 ksqlDB의 Stream이 보낸 것은 모두 Key / Value 형식으로 카프카의 브로커에 저장되게 된다.
스트림 변환
처음에 토픽으로부터 스트림을 만들고, 이 스트림으로 또 다른 스트림을 만들 수도 있다. 이렇게 하나의 스트림에서 또 다른 스트림을 만들게 되면 Persistence Query가 생성되고, Persistence Query는 내부적으로 동작하며 부모 스트림에서 발생하는 변경점에 대한 실시간 스트림 처리를 해준다. 이런 종류는 Kafka를 이용해도 충분히 할 수 있다. 예를 들어 Consumer로 읽고, Schema Registry로 처리해서, Producer로 다시 제공해주는 형태가 된다. 그렇지만 이런 경우 관리할 부분이 많아진다.
set 'auto.offset.reset' = 'earliest';
CREATE STREAM clean AS
SELECT sensor,
reading,
UCASE(location) AS location
FROM readings
EMIT CHANGES;위와 같이 스트림에서 새로운 스트림을 생성하면 Persistence Query가 생성되고, 이에 따라서 부모 스트림의 변환에 따라 실시간 스트림에 반영된다. Persistence Query를 생성하면 다음과 같이 동작한다고 한다.
- ksqlDB 서버는 쿼리의 텍스트 표현을 Kafka Streams Topology로 물리적 실행 계획으로 컴파일 한다.
- Topology는 Daemon으로 실행되어 새로운 Topic의 레코드를 처리할 수 있도록 한다.
아무튼 Persistence Query를 생성하면 show queries()를 이용해서 ksqldb-cli에서 현재 실행되고 있는 Persistence Query를 볼 수 있다. Persistence Query 결과로 새로운 Stream이 생성되는데 이 Stream은 메세지를 저장할 곳이 필요하다. 따라서 Persistence Query의 결과를 저장할 토픽도 동일한 이름으로 Kafka Broker에 생성되게 된다.

실행 환경은 위 그림을 참고할 수 있다. 여기서 참고할 부분은 다음과 같다.
- Persistence Query는 생성되고 계속 진행된다. 여기서 pq1는 Persistence Query1를 의미한다.
- Persistence Query는 스트림의 특정 파티션의 행을 선택한다.
- 각 행은 선택되면 Persistecne Query에 의해서 정의된 스트림 형태(위에서는 Clean)로 다시 변한다. (Topology)
Persistence Query는 스트림의 각 파티션의 어디까지 읽었는지를 offset으로 가지고 있다. 이것은 kafka consumer의 __consumer_offsets과는 다른 것이다. 그렇다면 Persistence Query는 다음에 읽을 입력 파티션은 어떻게 선택할까? 사용 가능한 가장 작은 타임 스탬프를 선택한다고 한다. (https://www.confluent.io/resources/kafka-summit-2020/the-flux-capacitor-of-kafka-streams-and-ksqldb)
또 가능한 작업들
위에서 살펴본 것처럼 ksqlDB는 스트림을 기반으로 이런 저런 일들을 한다. 아래에는 스트림을 이용해서 더 해볼 수 있는 일들을 작성했다.
- 스트림에서 행 필터링
- 여러 작업을 하나로 결합
- 스트림 다시 입력
각각을 하나하나 살펴보면 다음과 같다.
스트림에서 행 필터링
CREATE STREAM high_readings AS
SELECT sensor, reading, location
FROM clean
WHERE reading > 41
EMIT CHANGES;WHERE 절을 이용해서 조건을 만족하는 녀석만 필터링 해서 새로운 스트림을 만들 수 있다.
여러 작업을 하나로 결합
CREATE STREAM high_pri AS
SELECT sensor,
reading,
UCASE(location) AS location
FROM readings
WHERE reading > 41
EMIT CHANGES;여기서는 필터링과 열의 포멧을 바꾸는 두 가지 작업을 한번에 처리하는 스트림을 생성했다. ksqlDB는 쿼리문을 이용해서 이런 부분을 간략히 작성할 수 있다.
스트림 다시 입력
CREATE STREAM by_location AS
SELECT *
FROM high_pri
PARTITION BY location
EMIT CHANGES;필요한 경우 기존의 스트림을 다시 리파티셔닝 해서 사용할 수 있다. 리파티셔닝 한다는 것은 새로운 키를 생성한다는 것이고, 이것은 브로커에 저장될 것이다. 원래 스트림은 사람의 이름으로 파티셔닝 되어있었는데, 만약 내가 지역에 따라 다시 구분해서 보고 싶다면 리파티셔닝 하면서 스트림을 새로 생성할 수 있다.
여러 ksqlDB 스트림 처리에도 괜찮음.
Kafka는 여러 Consumer가 동일한 파티션을 읽어도 충돌 없이 읽을 수 있다. 각각이 __consume_offsets으로 관리되고 있기 때문이다. 마찬가지로 ksqlDB도 하나의 스트림을 여러 스트림이 읽어가도 아무 문제가 없도록 동작한다. ksqlDB는 각 영구 쿼리마다 'Group ID'를 할당하고, 이 'Group ID'를 바탕으로 각 메시지를 수신한다. 따라서 한 스트림을 여러 스트림이 구독해도 아무 문제가 없다.
CREATE STREAM STREAM2 as SELECT * from STREAM1;
CREATE STREAM STREAM3 as SELECT * from STREAM1;예를 들어 위와 같이 STREAM1을 구독하는 STREAM2/STREAM3을 생성해도 아무 문제가 없다. 각 스트림마다 GROUP ID가 할당되고, 이 GROUP ID를 바탕으로 각 Persistence Query는 offsets을 관리해가면서 읽어가기 때문이다.
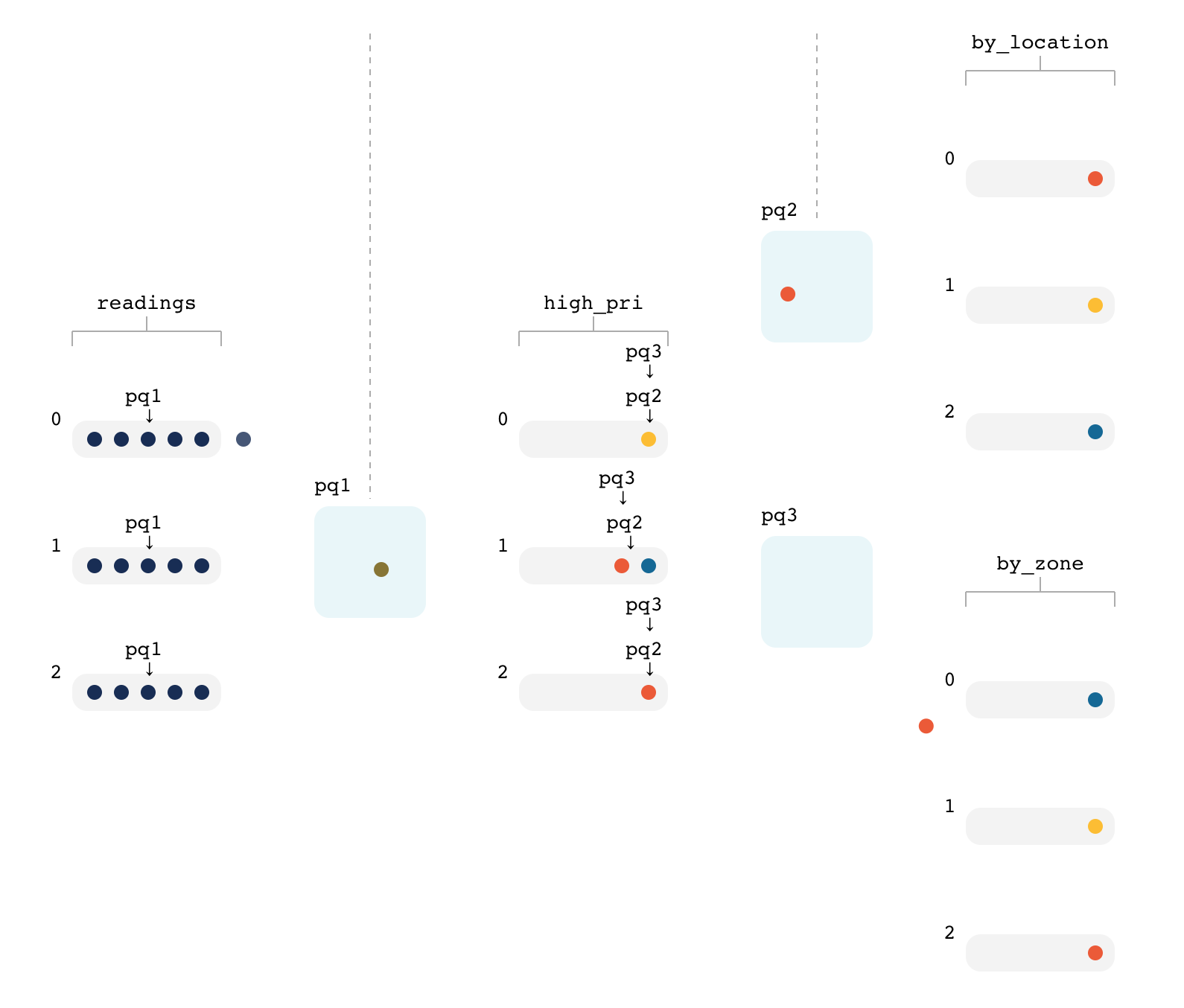
위의 이미지에서 볼 수 있듯이 p2, p3는 서로 다른 오프셋을 가지고 읽고 있다.
출처
'Kafka eco-system > ksqlDB' 카테고리의 다른 글
| ksqlDB : ksqlDB의 간단한 구조 및 배포 모드 (0) | 2022.10.15 |
|---|---|
| ksqlDB : Materialized View (0) | 2022.10.14 |
| ksqlDB : Window 정리 (0) | 2022.10.12 |
| ksqlDB : ksqlDB의 Join (1) | 2022.10.11 |
| ksqlDB : Repartition (0) | 2022.10.10 |