SpringBatch : JpaCursorItemReader
- Spring/Spring Batch
- 2022. 3. 13.
이 글은 인프런의 정수원님의 강의를 복습하며 작성한 글입니다.
JpaCusorItemReader
스프링 배치에서는 JPA를 활용한 Cursor 방식의 Itemreader를 제공한다. JPA에서는 Entity Manager를 활용해 DB와의 접근이 이루어지기 때문에 JPAItemReader를 사용할 때는 EntityManager를 할당해주어야 한다.
JpaCursorItemReader의 API
JpaCursorItemReader는 JpaCursorItemReaderBuilder를 통해 만들어진다. Builder는 JpaCursorItemReader의 설정값을 설정하기 위해 여러가지 API를 지원하고, 우리는 이 API를 통해 JpaCursorItemReader를 만들어야한다.
- name : JpaCursorItemReader의 이름을 지정해준다.
- entityManagerFactory : EntityManager를 만들 EntityManagerFactory를 지정해야한다. DI로 받으면 됨.
- queryString : JPQL 문법을 작성한다.
- parameterValues : JPQL에서 사용하는 쿼리 파라미터를 작성한다. <String, Object> 형식의 Map을 줘야함.
- maxItemCount : 한번에 가져올 최대 아이템 갯수를 설정한다.
- currentItemCount : 조회할 Item의 시작 위치를 설정한다.
- build : 설정값을 바탕으로 ItemReader를 만든다.
위의 API를 사용해서 Builder를 통해 ItemReader를 만들고 이걸 ChunkStep에 넘겨주면 된다.
JpaCursorItemReader API 사용 시 주의사항
JPQL 문을 작성할 때 조심해야한다. JPA에 익숙한 나는 JPQL을 작성할 때, 대소문자의 구분에 민감하지 않다. 그런데 여기서 사용되는 JPQL문은 반드시 Entity와 Column들의 대/소문자를 정확히 구분해서 사용해야한다.
.queryString("select c from Customer c where firstName like :firstname")위가 한 가지 예시다. 예를 들어 저기서 Customer를 customer로 바꾸면 Exception이 발생한다. firstName도 firstname으로 바꾸게 되면 Exception이 발생한다. 따라서 이 부분은 명확히 인지하고 Query문을 작성해야한다.
parameterValues에는 Map을 전달해야한다. JdbcCursorItemReader는 Map이 아니라 객체, 리스트 형태로 전달해야했던 것과 다르다.
JpaCursorItemReader의 순서도

JpaCursorItemReader의 순서도는 다음과 같이 동작한다. JpaCursorItemReader는 ItemStream, ItemReader 인터페이스를 모두 구현하고 있고, 각각 Open / Close를 통해 DB 연결을 열어준 다음에 read를 통해 JPQL 문을 실행해서 값을 가져온다.
- Step이 실행된다. 이 때 AbstractStep.execute() 내의 open 메서드를 호출한다. open 메서드를 통해 EntityManager, Query문, ResultStream을 만들어둔다.
- open 메서드 호출 후, ChunkOrientedTaskLet은 chunkProvider를 통해 Item을 받는다.
- Item을 받을 때, JpaCursorItemReader는 JPQL문을 작성해, Builder에서 설정한 maxItemCount만큼의 Item을 한번에 가지고 온다.
- 가지고 온 데이터를 ResultStream에 저장해둔다.
- ResultStream에 저장해둔 데이터를 Iterator를 통해 하나씩 꺼내온다.
JpaCursorItemReader는 여러번 DB Connection을 맺지 않고, ItemCursorReader에 설정된 maxItemCount만큼 한 번에 값을 가지고 와 ResultStream에 저장해둔다. JdbcCursorItemReader는 데이터를 가져오는 기간동안 DB Connection이 되어있고, fetch Size만큼 값을 가져와서 그만큼 DB 커넥션이 오래 연결된다.
반면 JPA는 DB Connection이 단 한번에 이루어지니 JdbcCursorItemReader에 비해서는 좀 더 성능이 빠르지 않을까? 라는 생각이 든다. 이건 나중에 테스트 코드를 작성해서 확인해봐야 할 것 같다.
+ 결론적으로는 같을 수도 있을 것 같다. 데이터를 가져오는 것은 DB에 단 한번 연결을 하지만, STEP은 Chunk 단위로 Transaction을 Commit하기 때문에 데이터가 같다면, Commit 횟수는 똑같을 것이기 때문이다. 그렇지만, 데이터를 가져올 때, Connection Time을 조금 더 짧아서 좋을 것 같다.
MaxItemCount의 의미
MaxItemCount는 Reader가 읽어올 수 있는 최대값을 의미한다. 예를 들어 테이블에 10,000개의 데이터가 있다고 했을 때, MaxItemCount가 1,000이고, Chunk가 10이면, MaxItemCount 1,000개에 대한 값만 처리를 한다. 예를 들어 이런 상황에서 ItemWriter가 DB에 값을 밀어넣는 상황이라고 가정하면, 실제로 DB에는 1,000개의 데이터만 들어가게 된다.
결론을 정리하면 다음과 같다고 이해를 하면 될 것 같다
- Chunk : 한번에 처리할 단위의 데이터 크기
- maxItemCount : 처리할 데이터의 전체 크기. DB에 30,000개가 있을 때, 이 값을 10,000으로 설정하면 실제 결과물은 10,000개만 만들어진다.
JpaCursorItemReader 코드 따라가보기

Step이 실행되게 되면, AbstractStep.exeucte()로 온다. 여기서 open()을 호출한다.

taskletStep.open() 메서드로 넘어오게 된다. 이 메서드에서는 stream.open()을 하게 된다.

CompositeItemStream.open()으로 넘어오게 된다. 여기서는 내부적으로 가지고 있는 Streames를 for문을 돌리면서 각 stream에 대한 open 메서드를 실행해준다.

AbstractItemCountingItemStreamItemReader.open()로 넘어오게 된다. 여기서는 doOpen() 메서드를 실행하는데, 이 메서드는 이 클래스의 구현체에서 실행한다. 이 클래스의 구현체인 JpaCursorItemReader로 넘어가게 된다.

JpaCursorItemReader.doOpen()으로 넘어온다. 여기서 EntityManager를 만들고, 그걸 바탕으로 query를 만들고, resultStream을 만드는 것을 볼 수 있다.
open을 다 처리하면, AbstractStep.Execute()로 다시 넘어온다. 여기서 doExecute() 메서드를 하게 된다.

chunkOrientedTasklet.execute()로 넘어오게 된다. 여기서 chunkProvider.provide 메서드를 따라 ItemReader를 이용해 item을 불러오게 된다.
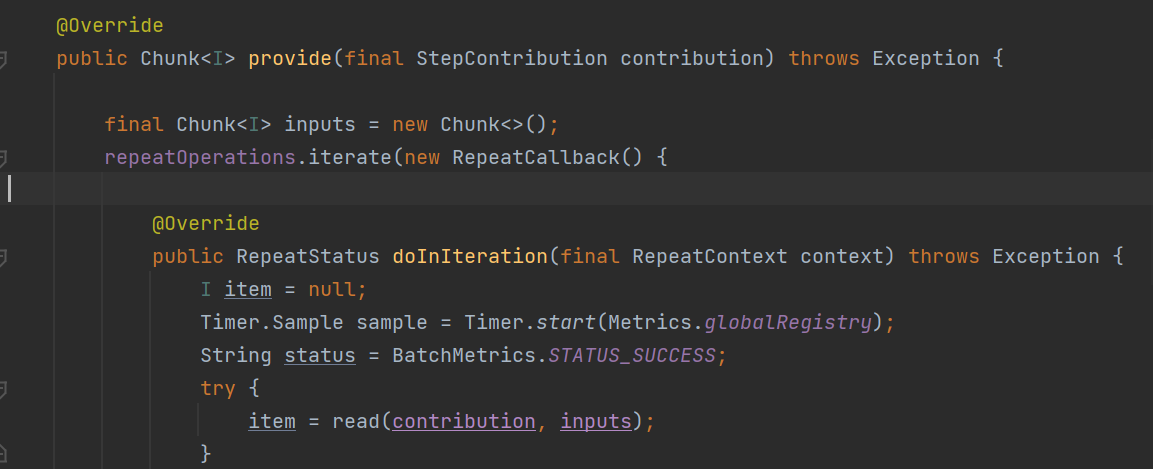
SimpleChunkProvider.provide()는 내부적으로 RepeatTemplate을 가진다. repeatTemplate을 가지면서, read 메서드를 통해 Item을 읽어오는 것을 확인할 수 있다.

SimpleChunkProvider.doRead()로 와서 itemReader.read()를 통해 itemReader에서 직접 item을 하나씩 가져오게 된다.
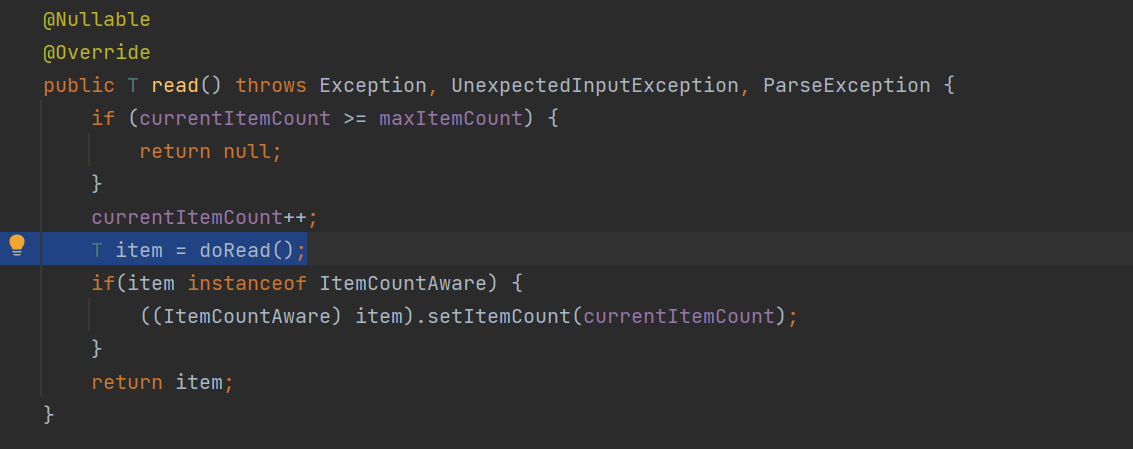
AbstractItemCountingItemStreamItemReader.read()로 넘어오면 여기서 doRead() 메서드로 넘어간다. doRead() 메서드는 이 추상 클래스의 구현체 메서드다.

iterator가 다음을 가지는지 보고, 다음이 있을 경우 iterator.next() 메서드를 이용해 Item을 불러오게 된다. 이렇게 되면 ItemReader의 역할은 끝이 난다. 나머지는 Processor / Writer를 통해 처리가 일어난다.
테스트 코드
GitHub - chickenchickenlove/springbatchstudy
Contribute to chickenchickenlove/springbatchstudy development by creating an account on GitHub.
github.com
테스트 코드 실행 결과 → JPA Query는 나가는지?

내가 궁금했던 부분은 JpaItemReader에서 실제로 JpaQuery문이 나가는지가 궁금했다. Hibernate 속성을 켜고 Select 쿼리가 나가는지를 확인했는데, 실제로 값이 나가는 것이 확인되었다. 그리고 Select 쿼리문은 딱 하나만 나갔다.
return new JpaCursorItemReaderBuilder<Customer>()
.name("jpaCursorItemReader")
.entityManagerFactory(emf)
.queryString("select c from Customer c")
// .queryString("select c from Customer c where firstName = :firstname")
// .queryString("select c from Customer c where firstName like :firstname")
// .parameterValues(paramMap)
.maxItemCount(100)
.currentItemCount(10)
.build();
}의아했던 부분은 maxItemCount / currentItemCount에 설정된 값이 Query 문에는 전혀 들어가지 않는 것이 보인다. 따라서 이런 ItemCount는 DB SQL 문에서 처리를 해주는 것이 아니라, 가져온 데이터를 ResultStream으로 가공할 때 처리가 되는 것으로 짐작할 수 있다.
'Spring > Spring Batch' 카테고리의 다른 글
| SpringBatch : JpaPagingItemReader (0) | 2022.03.13 |
|---|---|
| Spring Batch : JdbcPagingItemReader (1) | 2022.03.13 |
| Spring Batch : JdbcCursorItemReader (0) | 2022.03.13 |
| Spring Batch : Step 도메인 이해 (0) | 2022.03.09 |
| Spring Batch : Job 도메인 이해 (0) | 2022.03.09 |