분산 프로토콜 : SWIM
- Distributed System
- 2023. 12. 16.
1. 클러스터란 무엇인가?
사용자 관점에서 클러스터는 '단일 머신'처럼 보이도록 만들어준다. 여러 서버가 상호 연결된 클러스터는 새로운 서버가 추가되거나 제거되기도 하는데, 클러스터는 이런 개념들을 '단일 머신'으로 추상화해준다. 이 덕분에 클라이언트는 클러스터에서 발생할 수 있는 여러 복잡한 시나리오들을 고려하지 않을 수 있다.
그러나 클러스터가 이런 추상화를 제공해주기 위해서는 클러스터가 구현해야하는 프로토콜과 책임이 존재한다. 아래에서는 클러스터가 일반적으로 구현해야하는 것들을 의미한다.
2. 클러스터 0계층
아래 항목들은 위 추상화를 보장하기 위해 클러스터가 고려하고 구현해야 할 가장 기본적인 부분이다.
2.1 어떻게 클러스터에 조인할까?
클러스터에 조인하려는 새로운 서버 노드가 있다면, 이미 클러스터의 멤버 노드들과 통신하는 방법을 알아야 한다. 그래야 클러스터에 'Join' 요청을 보낼 수 있다. 어디서 그런 정보를 찾을 수 있을까?
- 서버 노드를 기동할 때, 컨택 포인트 리스트를 Configuration Parameter로 제공. (yaml 등..)
- Etch, Zookeeper 같은 써드파티로 Node Registry를 구축. 서버 노드가 기동할 때, Node Registry에 질의.
- 호스트 환경에서는 k8s DNS, mDNS 서비스등을 이용할 수 있음.
2.2 클러스터에 속한 다른 노드를 어떻게 알 수 있을까?
이 문제를 다루는 주요한 주제는 멤버쉽 프로토콜이다. 동적 클러스터에서는 Active discovered 노드를 추적하고, 노드가 가입/탈퇴하면 이를 업데이트하고 가십(전파)하는 방식으로 수행된다. 여기서 많은 결정은 배포 시나리오에 따라 달라진다. 예를 들어 동일 IDC 내에서 클러스터를 구성하는 서비스는 모바일 디바이스 메시와는 다른 특성을 가져야만 한다.
- 동일 IDC 센터에서 동작하는 일반적인 백엔드 서비스 클러스터
- SWIM 프로토콜 적합. 모든 노드가 클러스터 전체 정보를 알고 있고, 직접 서로의 상태를 체크.
- 규모가 큰 클러스터 (수천개 이상이거나, 여러 IDC 센터에서 동작)
- HaParView 프로토콜 적합. 노드는 클러스터의 일부 상태만 알고 있으므로 확장에 유리.
2.3 한 노드에서 다른 노드로 메세지를 보내려면?
일반적으로 이 부분 역시 멤버십 프로토콜의 책임이다.
- IDC 기반 시스템 시나리오 : 모든 노드가 다른 모든 노드에 연결될 수 있다는 보수적인 가정을 할 수 있음.
- 다른 시나리오 : 네트워크 특성상, 일부 노드가 다른 노드에 연결되지 못할 수도 있음.
일반적으로 IDC 기반 시스템 시나리오에서 동일한 Private Subnet에서는 서로 접근할 수 있다고 보는 편이다. 보안적인 문제도 없을 것이고, 같은 IDC이니 Latency 문제 또한 없을 것이기 때문이다. 반면 다른 시나리오에서는 보안(Firewall)이나 NAT 등의 문제로 노드끼리 연결되지 못할 수도 있을 것이다.
모든 노드끼리 연결된 단순한 경우에는 노드 간 메세지 전송을 위해 TCP 프로토콜만 사용하면 되지만, 그렇지 않은 경우에는 노드 간 메세지 전송을 단순히 할 수가 없다. 따라서 멤버쉽 프로토콜은 보다 복잡한 방식으로 메세지 전송을 할 수 밖에 없다.
2.4 죽은 노드를 어떻게 감지할 수 있을까?
이것은 Failure Detection(실패 감지)로 알려져 있다. 가장 많이 알려진 방법은 timeout 이내에 ping ↔ ack를 주고 받거나, 모든 Connection이 주어진 시간 간격 이내에 Heartbeat 메세지를 보내는 것이다.
- Heartbeat은 주로 TCP(L4)에 직접 구현되기도 하고, 때로는 TCP 위(L7)에 Heartbeta을 전송할 수도 있다. 한 가지 문제점은 TCP는 OS에 관리하기 때문에 응답성이 뛰어나지만, Application Layer는 그렇지 않을 수 있다. Application 계층에서는 Deadlock이 발생한다거나 할 수 있기 때문이다.
- 멤버쉽 프로토콜은 자체 Heartbeat 알고리즘을 사용하기도 한다.
- 누락된 Heartbeat은 반드시 그 노드가 죽은 것을 의미하지는 않는다. 예를 들어 Heartbeat을 받는 수신 받는 서버의 메세지큐가 가득차서, 상대방이 Heartbeat을 정상적으로 전송했으나 Accept 하지 못하고 있을 수 있기 때문이다.
최근에 만들어진 프로토콜(SWIM 프로토콜의 확장된 버전인 Phi accural failure dector, LifeGuard)은 위에서 이야기한 Heartbeat을 받는 서버쪽에서 다른 요청을 처리하느라 과부하에 걸린 시나리오를 고려하기도 한다.
3. 더 고려해야 할 부분
위에서는 추상화 된 클러스터를 위한 기본적인 내용들을 고려해보았다. 그러나 위 고려사항만으로는 충분히 동작할 수 없다. 좀 더 복잡한 아래의 내용도 반드시 고려해야만 한다.
3.1 주기적인 네트워크 파티셔닝을 어떻게 감지하고 대응할 수 있을까?
흔히 split-brain 시나리오로 알려진 문제다. 이 시나리오는 다음 이유 때문에 발생할 수 있다.
응답하지 않는 노드와 죽은 노드를 구분할 수 없다.
이런 split-brain 시나리오에서는 클러스터가 두 개 이상으로 분할된다. 이 때 각 노드는 스스로만 살아있다고 믿고 클러스터에 대한 데이터 불일치, 데이터 손상을 유발할 수 있다.
예를 들어 여러 노드로 구성된 클러스터가 있을 때, 일부 노드가 네트워크 파티셔닝으로 다른 노드와 통신할 수 없게 되면, 자신을 제외한 모든 노드는 '죽은 노드'라고 판단할 수 있다. 그러면 각 노드는 스스로가 노드가 1개뿐인 클러스터가 되어 독립적인 형태로 동작한다. 그리고 이 노드들이 가지고 있는 데이터나 상태는 서로 다를 수 있을 것이고, 이 때문에 클러스터 간 노드들의 데이터 불일치 문제가 발생한다.
3.2 서로 다른 노드가 클러스터의 상태를 어떻게 추론하고 결정할 수 있을까?
이 경우는 주로 분산 Database와 같이 데이터 관리를 담당하는 시스템에서 발생한다. 예를 들면 etcd가 있다. 각 노드는 들어오는 요청을 처리해야하는데, 네트워크 파티셔닝등으로 클러스터가 분리되었을 때 각 노드가 내리는 결정이 '서로 상충되는 결정'이 될 수 있다. 이 문제에 대한 일반적인 접근 방식을 살펴보자.
- Conflict 방지 : 일반적으로 노드가 결정을 내리기 전에 시스템 상태에 대한 합의를 도출해야한다는 전제를 이용해 충돌을 방지함. 이를 위해 노드들 사이에 리더를 설정하고 유지해야하며, Node Quorum을 이용해 동기화 해야한다. (Raft, ZAB, Paxos)
- Conflict 발생을 인정하고, Conflict 해결 : 긴 latency나 주기적으로 연결할 수 없는 서버가 많은 환경에서 고려하는 절충안이다. 모든 노드의 합의 없이도 각 노드가 독립적으로 최종 상태를 결정할 수 있게 해준다. 그리고 각 노드가 결정한 결정 사항이 최종적으로는 동일한 결론이 될 수 있도록 충분한 메타 데이터를 보강해준다. (CRDTs)
두번째 방식은 긴 latency가 있는 경우, 모든 Node의 Consensus를 이루는데 네트워크 문제로 실패할 가능성이 매우 크기 때문에 위와 같은 방식이 고려되기도 한다.
3.3 클러스터 내부의 특정 리소스로 요청을 라우팅하는 방법은 무엇일까?
클러스터에 있는 노드들이 각 리소스들을 가지고 있는 상황을 가정해보자. (일반적으로 그렇다)
이 때, 클러스터가 커진다는 것은 클러스터가 보관하는 상태, 리소스 등이 비례해서 커지는 것을 의미한다. 그렇다면 데이터가 너무 많아지기 때문에 단일 노드만이 해당 정보를 가지기에는 무리가 있다. 또한 여러가지 약점(SPOF 등)이 존재할 수 있다. 이런 약점을 극복하기 위해서 여러 노드가 복제본을 가지고 있도록 할 수 있고, 리소스를 분할해서 각 노드에 보관하는 방법을 사용한다.
그런데 이 상황에서 클라이언트가 특정 리소스가 필요해서 어떤 노드에게 요청을 보냈다면, 이 정보를 어떻게 찾아서 반환할 수 있을까?
- Naive한 방법
- 해당 리소스의 복제본이 클러스터 내에 R개 있고, 클러스터 전체 노드 수가 N개 일 때 (N/R) + 1번 요청을 보냈을 때, 리소스에 도착할 수 있어야 한다.
- 불필요한 쿼리가 많이 발생하기 때문이 비효율적이다.
- 중앙 저장소 이용
- 모든 엔티티의 정보를 중앙 저장소에 저장한다.
- 중앙 저장소에서 해당 리소스를 가진 노드를 찾은 후에, 노드에 요청을 보낸다.
- 중앙 저장소가 SPOF가 될 수 있다.
- 큰 클러스터는 많은 리소스를 가지고, 리소스 ID 단건 - 노드 ID로 맵핑하기 때문에 클러스터 확장성에 문제를 가져온다.
- 중앙 저장소 + 파티셔닝
- 데이터를 파티션 단위로 묶고, 중앙 저장소에서는 (Partition ID - Node ID) 형태로 저장한다.
- 특정 노드는 특정 파티션의 데이터를 가지고 있다.
- 중앙 저장소에서 해당 리소스를 가진 노드를 찾은 후에, 노드에 요청을 보낸다.
- 클러스터가 커져도, 데이터가 파티션 단위로 압축되기 때문에 확장 가능한 설계다.
- 분산 해시 테이블 (Distirubted Hash Table)
- 특정 Key를 특정 해시 함수로 Hashing하여 어떤 노드가 어떤 키를 담당할지 결정한다.
- 각 노드는 필요한 데이터의 해시값을 구하면, 어떤 노드가 그 값을 담당하는지 알 수 있다. (Consistent Hash 같은 것들)
- 중앙 저장소가 필요없어서 구조 자체는 단순해짐.
- 노드가 추가/제거될 때 전체 Hash Ring을 재배열하는 비용이 커짐.
4. SWIM 프로토콜
SWIM 프로토콜은 멤버십 프로토콜의 일종이다.
4.1 SWIM 프로토콜 이론
SWIM 프로토콜을 구현하기 전에 먼저 고려해야 할 시나리오들은 다음과 같다.
- 새로운 노드가 클러스터에 참여하려고 한다. 어떻게 참여를 허가하고, 클러스터 멤버들에게 새로운 노드의 참여 정보를 알릴 수 있을까?
- 멤버가 클러스터에서 Graceful하게 떠나려고 한다. 어떻게 이 정보를 전파할 수 있을까?
- 어떤 멤버가 갑자기 종료되거나 연결할 수 없다. 어떻게 다른 멤버들에게 이 사실을 전파할 수 있을까?
1~2번은 매우 간단하다. 그러나 3번 시나리오 때문에 구현이 복잡해진다. 같은 IDC 센터에 있는 노드라도, 특정 노드끼리 연결된 구간이 실패할 수 있으며, 다른 노드들은 해당 노드에 접근할 수 있다. 이런 경우가 있기 때문데 어떤 멤버가 한번 응답하지 않더라도 바로 클러스터에서 제외하는 것은 바람직하지 않다. 만약 한번 응답하지 않는다고 노드를 클러스터에서 제외한다면, 그 클러스터는 매우 불안정한 클러스터가 될 것이다.
이런 우려사항은 다음을 고려해보면 해결할 수 있다.

어떤 노드는 다른 임의의 노드에게 HeartBeat을 보낼 수 있다. 예를 들어 A -> C로 Ping 메세지를 보내고, Timeout이 발생하기 전에 C -> A로 ACK 메세지가 올 것을 예상한다. 이 경우, A는 C가 여전히 정상적으로 동작한다고 판단할 수 있다.

A -> C로 Ping 요청을 보냈는데, C -> A로 ACK가 Timeout이 발생했다. 한번 응답을 못했다고 해서 응답못한 노드를 클러스터에서 매번 제외하면 불안정한 클러스터가 될 것이다. 따라서 아직까지는 C를 '죽은 노드'로 판단하지 않을 것이다. 대신에 모든 클러스터 멤버 (C 포함)에게 'Suspect C'라는 메세지를 전송한다.
각 노드들은 의심스러운 노드 C가 특정 시간 내에 확인되길 바라며 타이머 Alive(C)를 셋팅한다. 만약 타이머 Alive(C)가 Timeout 되기 전에 정보를 받으면 '의심스러운 노드 리스트'에서 C를 제거할 것이다.
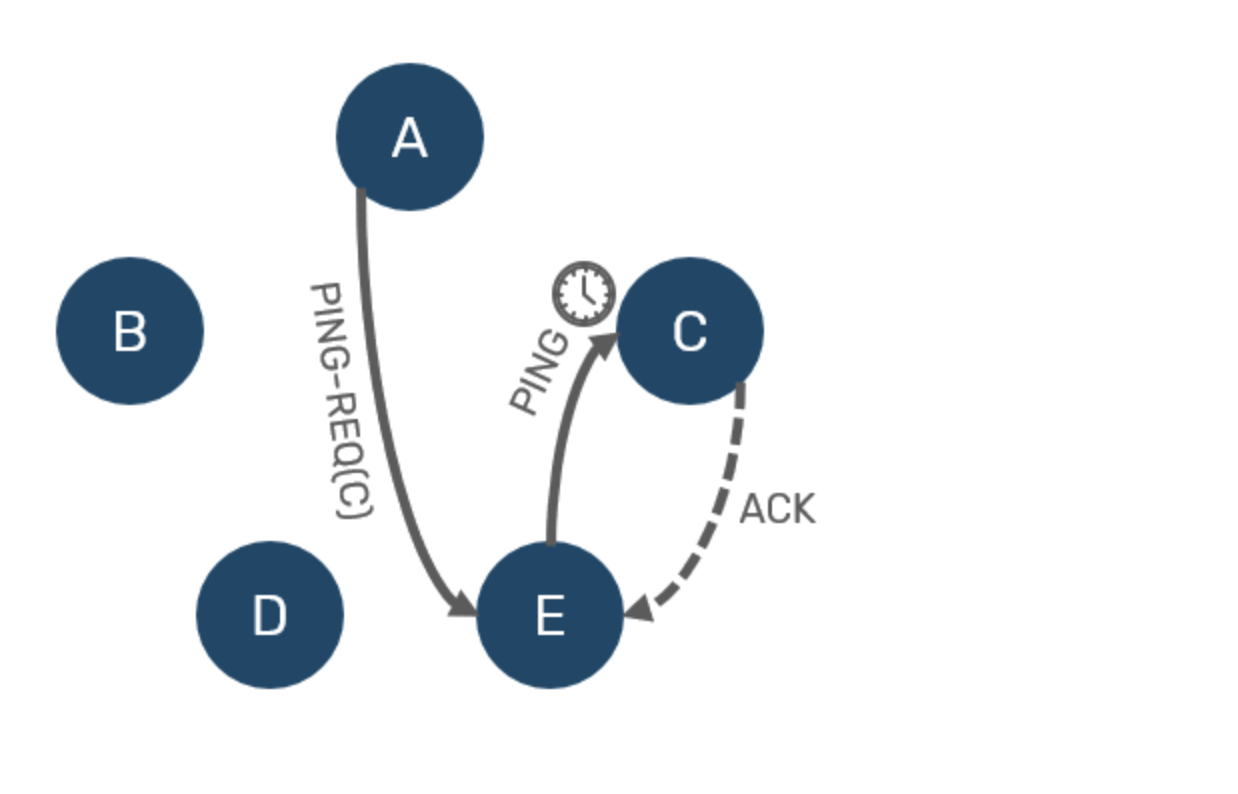
이제 C가 살아있는지 확인이 필요하다. 이 때, A는 '의심스럽지 않는 노드'들 중에서 하나를 뽑아, 그 노드에게 C가 정상인지 대신 확인해달라는 메세지인 PING-REQ(C)를 전송한다. 이 때, E가 C로 Ping을 보낼 것이고 C가 E에게 ACK하면, C는 살아있고 A - C 네트워크 구간에 문제가 있었을 뿐이라는 것을 알게 된다.

반면 E가 C에게 ACK를 받지 못하면, A / E가 더블체크한 것이기 때문에 모든 클러스터 멤버들에게 'C'는 죽은 노드라고 알릴 수 있다.
그러나 DEAD(C)라는 메세지가 'C'가 실제로 죽은 상태라는 것을 의미하지는 않는다. 의심 노드 C가 제 때 응답하지 못한 이유는 '실제로 죽은 것' 외에도 다음 코너 케이스들이 존재할 수 있다.
- 다른 요청을 처리하느라 너무 바빠 HeartBeat에 너무 늦게 응답함.
- JVM Stop the world로 인해 응답 속도가 느려짐.
- Split Brain으로 인한 현상
- 이미 A,E와 B,C,D로 클러스터가 나눠졌을 수도 있음. A는 C가 죽었다고 판단, C는 A가 죽었다고 판단.
- 즉, C는 모르는 노드 A에게 PING 요청이 왔기 때문에 응답하지 않았을 수도 있음.
궁극적으로는 100% 신뢰할 수 있는 Failure Detection은 존재하지 않는다. 개선할 수 있는 방법은 Fales Alert을 줄이고, 죽은 노드를 감지하는데 걸리는 시간을 줄이는 것이다. 그러나 이 둘은 일반적으로는 Trade-Off 관계를 가진다.
위에서 언급한 시나리오 중 일부는 Lifeguard 프로토콜을 이용해 일부 보완할 수 있다.
5. SWIM 프로토콜 - 구현
조금 쉬운 구현을 위하 몇 가지 시나리오를 단순화한다. 이것은 SWIM 프로토콜을 더 쉽게 이해하는데 도움을 줄 수 있다.
- PING - ACK 메세지에 Sequential 번호 추가
- Sequential 번호는 죽은 노드가 부활하는 것을 방지하기 위해 필요하다.
- A 노드 -> B노드로 PING1을 보냄.
- B노드는 ACK1을 응답했으나, A 노드에 아직 도달하지 않음.
- A 노드 -> B노드로 PING2를 보냄.
- B노드는 죽어서 ACK2를 보낼 수 없다.
- 뒤늦게 ACK1이 A 노드에게 전달된다. 이 때, 죽은 노드 B는 살아있다고 판단된다.
- Sequential 번호는 죽은 노드가 부활하는 것을 방지하기 위해 필요하다.
- PING을 보낼 때 마다, MemberShip State를 함께 가십(전파)한다.
최적화 된 방법은 아니지만, 클러스터 규모가 작을 때는 잘 동작할 것이다. 좀 더 최적화 한다면, 현재 노드가 알고 있는 Membership State를 해싱해서 PING에 포함시켜서 보낸다. 그리고 ACK를 하는 노드는 자신이 알고 있는 Membership State의 해시와 다른 경우, ACK에 Membership State를 포함해서 보내는 방식이 될 수 있다.
F#으로 작성된 원본 코드는 이곳에서 확인할 수 있다.
6. SWIM 프로토콜 구현 전제조건
실제 노드 간 통신은 TCP 프로토콜을 통해서 이루어질 것이다. 그러나 실제 통신을 고려한다면, SWIM 프로토콜에서 TCP Handshake, 데이터의 직렬화/역직렬화 등을 구현해야한다. 이런 이유 때문에 SWIM 프로토콜을 구현하는 것보다 주변의 중요하지 않은 것들을 구현하는데 많은 시간이 걸릴 것이다.
이런 구현의 복잡성을 제거하고, 프로토콜 자체에만 집중하기 위해서 Actor 모델을 기반으로 프로세스 통신을 모사하고 SWIM 프로토콜을 구현할 것이다. 원문에서는 F#의 Akka.NET/Akkling이 사용되는데, 이 글에서는 erlang으로 포팅하여 구현하고자 한다.
멤버쉽 프로토콜
클러스터를 구성하는 노드들이 서로 인식하고, 노드가 추가/제거 될 때 이를 전파하는 프로토콜을 의미한다. 멤버쉽 프로토콜은 클러스터의 확장성(Scalability), 안정성(Fault Tolerance), 성능(Performance)에 영향을 미친다. 여러가지 기준에 의해서 멤버쉽 프로토콜은 분류될 수 있다.
- static cluster : 미리 정해진 구성 목록이 있음.
- dynamic cluster : 노드가 실시간으로 추가/제거되며 이를 자동으로 감지하여 반영
또 다른 기준으로는 클러스터 상태 정보를 어떻게 가지고 있느냐도 기준이 될 수 있다.
- Full Membership : 각 노드가 전체 클러스터의 상태를 알고 있고, 모든 노드가 서로 직접적인 연결을 유지함. (SWIM 프로토콜)
- Partial Membership : 각 노드가 클러스터의 일부만 알고 있음. 클러스터 크기가 매우 커질 경우, 모든 노드가 클러스터 전체 정보를 유지하는 것은 어렵기 때문(확장성 관점에서 좋음). 대표적인 예로 HyparView 프로토콜.
-module(swim_node).
-behavior(gen_server).
%% API
-export([start_link/2]).
% gen_server callback
-export([init/1, handle_call/3, handle_cast/2, handle_info/2]).
-export([main/0]).
% 5s
-define(DEFAULT_INIT_JOIN_TIMEOUT, 50000).
-record(?MODULE, {
my_state = init,
my_self = undefined,
actives = #{},
suspects = #{},
try_join_timer = undefined
}).
main() ->
swim_node:start_link([], 'A'),
timer:sleep(1000),
swim_node:start_link(['A'], 'B'),
% There are potential concurrency problem.
% Because 'B'는 is not a cluster member yet.
% So, Process 'C' may fail to find Node 'B'.
swim_node:start_link(['A', 'B'], 'C').
%% swim_node:start_link(['A', 'B'], 'C').
start_link(ClusterNodes, MyAlias) ->
ClusterNodesWithPid = [whereis(ClusterNodeAlias) || ClusterNodeAlias <- ClusterNodes],
gen_server:start_link(?MODULE, [ClusterNodesWithPid, MyAlias], []).
init([ClusterNodes, MyAlias]) ->
io:format("[~p] swim_node [~p] try to intialized ~n", [self(), self()]),
erlang:register(MyAlias, self()),
ActiveCluster = case ClusterNodes of
% 클러스터의 첫번째 노드일 때,
[] -> #{self() => 1};
ClusterNodes ->
Msg = {init, ClusterNodes},
erlang:send_after(0, self(), Msg),
#{}
end,
State = #?MODULE{my_self=self(), actives=ActiveCluster},
{ok, State}.
% 모르는 메세지
handle_call(_, _From, _State) ->
{reply, _State, _State}.
% 클러스터 조인 요청을 할 때
handle_info({init, KnownClusterNodes}, State) ->
MaybeTimer = case KnownClusterNodes of
[] -> error(failed_to_join);
[Node | Rest] ->
Msg = {join, self()},
gen_server:cast(Node, Msg),
{ok, Timer} = timer:send_after(?DEFAULT_INIT_JOIN_TIMEOUT, {init, Rest}),
Timer
end,
NewState = State#?MODULE{try_join_timer=MaybeTimer},
{noreply, NewState};
handle_info(_Msg, State) ->
{noreply, State}.
% 클러스터 조인 요청을 받음.
handle_cast({join, TryToJoinPid}, State) ->
io:format("[~p] swim_node [~p] receive join request from ~p ~n", [self(), self(), TryToJoinPid]),
#?MODULE{actives=Actives} = State,
NewActives = maps:put(TryToJoinPid, 1, Actives),
GossipMsg = {joined, NewActives},
lists:foreach(
fun
(Pid) when Pid =/= self() -> gen_server:cast(Pid, GossipMsg);
(_Pid) -> ok
end, maps:keys(NewActives)),
NewState = State#?MODULE{actives=NewActives},
{noreply, NewState};
% 클러스터 Active의 상태가 변화함. Gossip
handle_cast({joined, NewActives}, #?MODULE{try_join_timer=PreviousTimer}=State) ->
io:format("[~p] swim_node [~p] receive joined gossip~n", [self(), self()]),
timer:cancel(PreviousTimer),
#?MODULE{actives=Actives} = State,
UpdatedActives = maps:merge(Actives, NewActives),
NewState = State#?MODULE{actives=UpdatedActives, try_join_timer=undefined},
{noreply, NewState};
handle_cast(_Msg, State) ->
{no_reply, State}.
'Distributed System' 카테고리의 다른 글
| 분산 컴퓨팅 10. 벡터 시계와 스냅샷 찍기 (0) | 2024.03.17 |
|---|---|
| 분산 컴퓨팅 3. 시간 동기화 문제와 논리적 시계 (램포트 시계) (0) | 2024.03.17 |
| 분산 컴퓨팅 2. 중재자와 2단계 커밋 프로토콜 (0) | 2024.03.10 |
| 분산 컴퓨팅 1. 분산 컴퓨팅이란 무엇인가? (0) | 2024.03.10 |
| 분산 프로토콜 : plum tree (0) | 2023.12.14 |