스프링 조회수 구현하기
- Spring/Spring
- 2023. 8. 13.
들어가기 전
조회수는 별거 아닌 기능인 것처럼 생각되지만, 이번에 구현해보려고 할 때 정말 어려운 작업이라는 것을 느꼈다. 특히 다음 관점에서 어렵다. 아래에서는 여러 버전을 구현하고 테스트 하면서 결론을 하나씩 정리해보고자 한다.
- 동시성 문제
- 실시간 반영성 문제
- 정확성 문제
요구 사항
- 가능한 실시간으로 업데이트 되어야 함.
- 한 명이 하나의 가게를 하루에 여러 번 조회해도 가게의 조회수는 단 한 번만 증가해야 함.
- 조회수 기능이 동작하지 않더라도 어플리케이션은 동작해야 함.
내가 구현한 조회수 기능의 요구 사항은 다음과 같다.
결과 검증 코드
많은 요청이 동시에 들어왔을 때 발생할 수 있는 동시성 문제 / 성능 문제를 확인하기 위해 아래 파이썬 코드를 이용했다. aiohttp와 asyncio를 이용해 비동기 요청을 Step Function 형태로 보냈다.
각각 10, 100, 1000, 10000, 100000번씩 동일한 요청을 보내서 동시성 문제 / 성능 문제를 평가한다. 예를 들면 아래와 같이 요청을 보낸다.
- customer_id = 10000, store_id = 1에 대해서 10번 조회
- customer_id = 10001, store_id = 2에 대해서 100번 조회
- customer_id = 10002, store_id = 3에 대해서 1000번 조회
- customer_id = 10003, store_id = 4에 대해서 10000번 조회
async def same_customer_same_store(ex, customer_id, store_id):
async with aiohttp.ClientSession() as session:
# print('create task.')
tasks = [session.get(f'http://localhost:8080/tx1/{customer_id}/{store_id}') for _ in range(1, 10**ex)]
# print('task completed')
result = [await t for t in tasks]
# print('end')
async def async_main():
for customer_id, store_id, ex in zip([10000, 10001, 10002, 10003], [1, 2, 3, 4], [1,2,3,4]):
print(f'test_start. iteration = {ex}')
s = time.time()
await same_customer_same_store(ex, customer_id, store_id)
e = time.time()
print(f'request count = {10**ex}. spend time = {e - s}')
asyncio.run(async_main())
쿠버네티스 클러스터 환경
수평 스케일링 상태를 평가하기 위해 우리 집에 가내 수공업 쿠버네티스 클러스터를 구성해서 평가를 진행했다. 쿠버네티스 환경은 다음과 같다.
- 클러스터 구성
- 워커 : 3대
- 마스터 : 1대
- 사양 : 라즈베리파이4B 8GB. MicroSD 128GB
요청이 전달되는 방법은 아래와 같다. 실제로 .com 도메인을 하나 파서 DNS Query가 직접적으로 이루어져서 마스터 노드에 요청이 전달된다. 마스터 노드에 전달된 후에 nginx → Ingress Contrller → Pod 순으로 네트워크 Hop을 타게 된다.
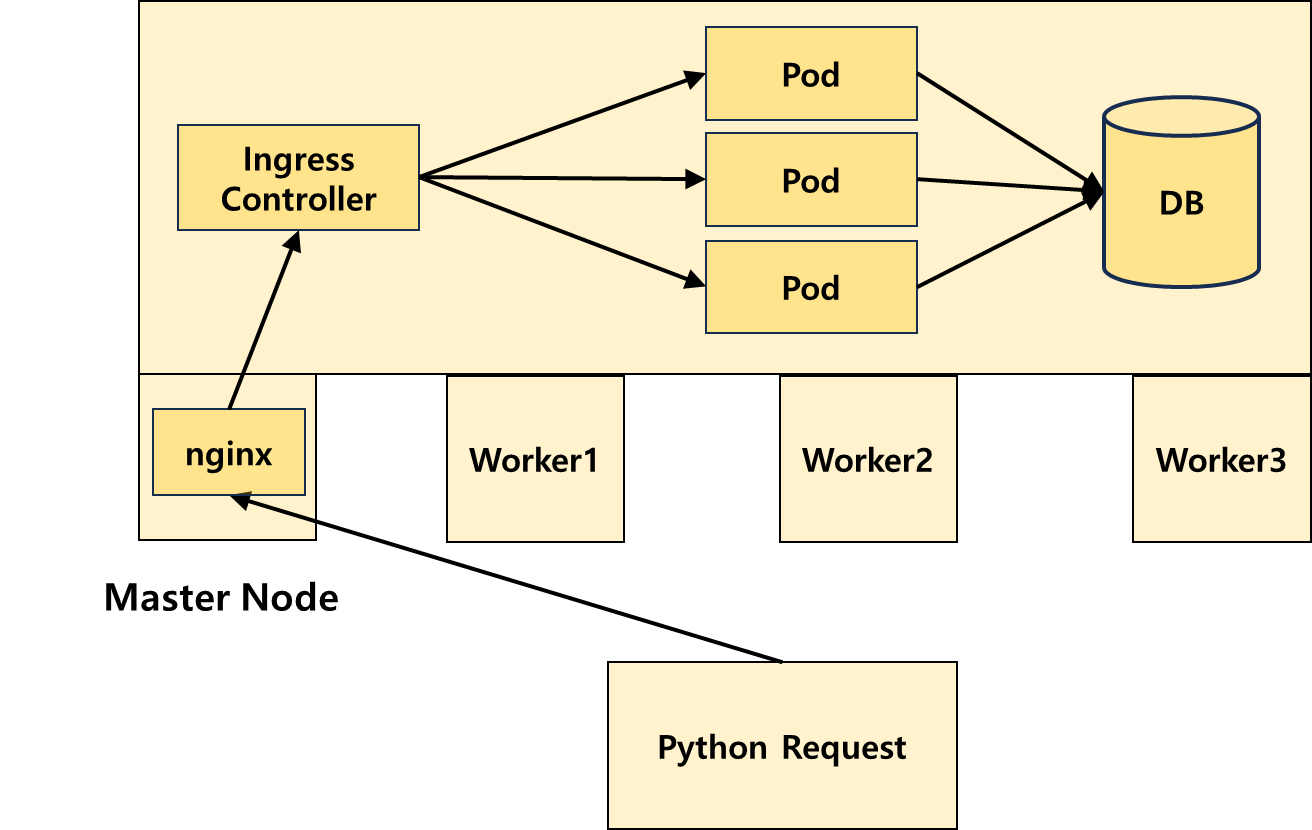
버전1
첫번째 버전은 MySQL의 트랜잭션 격리 수준에 의존하는 방법이다. 이 방법의 장단점은 다음과 같다고 생각한다.
- 장점
- MySQL과 웹 서버 만으로 구현 가능함. 따라서 관리해야 할 컴포넌트가 적다.
- 클라우드 환경에서도 문제없음.
- 단점
- 구현하기 위해서 트랜잭션이 길어짐.
기본적인 조회수 로직은 다음과 같다. 한 Customer가 Store를 조회했을 때, CustomerStoreVisit라는 것을 생성한 이후 DB에 밀어넣는다. CustomerStoreVisit가 생성되었다는 것은 Customer가 Store에 오늘 처음 방문한 것을 의미하기 때문에 true를 리턴하고, 값이 true이면 tx1Update()를 호출해서 조회수를 1개 올려준다.
public boolean tx1(Long customerId, Long storeId) {
Store store = myRepository.findStore(storeId);
Customer customer = myRepository.findCustomer(customerId);
CustomerStoreVisit customerStoreVisitByCondition = myRepository.findCustomerStoreVisitByCondition(customerId, storeId, LocalDate.now());
if (customerStoreVisitByCondition != null) {
log.info("already exist");
return false ;
}
CustomerStoreVisit customerStoreVisit = CustomerStoreVisit.create(customer, store, LocalDate.now());
myRepository.saveCustomerStoreVisit(customerStoreVisit);
log.info("tx1 end");
return true;
}
public void tx1Update(Long storeId) {
LocalDate now = LocalDate.now();
StoreViewCount findSVC = myRepository.findStoreViewCount(storeId, now);
if (findSVC != null) {
findSVC.add();
return;
}
Store store = myRepository.findStore(storeId);
ViewCount viewCount = ViewCount.create(LocalDate.now());
myRepository.saveViewCount(viewCount);
StoreViewCount storeViewCount = StoreViewCount.create(store, viewCount);
storeViewCount.add();
myRepository.saveStoreViewCount(storeViewCount);
}이런 형태로 조회수를 구성한다면 요청 건수당 처리 시간이 얼마나 걸릴까? 서버에 동시 요청이 왔을 때, 동시성 문제가 없는지를 살펴보았는데 각 요청 당 1건씩만 생성된 것을 볼 수 있다. (store_id = 10000, 10001, 10002, 10003)
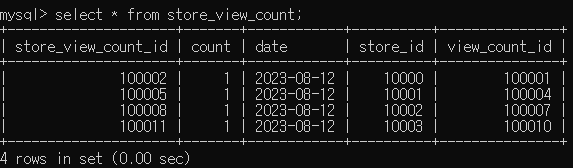
반면 모든 요청에 대해서 클라이언트 (파이썬 테스트 코드)가 응답을 받는데 걸린 시간은 아래와 같다. 서버는 다른 어떠한 트래픽도 받지 않고 이 요청만 받았을 때의 처리 건수다. 그럼에도 불구하고 10,000건을 처리하는데 37초가 걸렸다.
| 요청 건수 | 처리 시간 |
| 10 | 0.34초 |
| 100 | 0.55초 |
| 1,000 | 4.05초 |
| 10,000 | 37.07초 |
이 버전의 테스트 결과는 다음과 같다.
- 동시에 동일한 요청이 여러번 들어왔을 때, 동시성 문제는 없음.
- MySQL 만으로 구현 가능함.
Version1 : 쿠버네티스 환경에서 수평 스케일링 테스트
여러 서버 (수평 스케일링 상황 가정)가 있을 때의 동시성 / 성능을 평가하기 위해서 쿠버네티스 환경에서 평가를 진행했다. 아래는 평가 결과인데 성능 관점에서는 정합성이 없는 결과가 나왔다. 아마 라즈베리파이로 만들어진 노드의 성능 문제 같은 것들이 유효하지 않나 싶다. 그래서 수평 스케일링 테스트는 DB에서 동시성 이슈를 확인하는 용도로만 사용하기로 했다.
| 요청 건수 (서버 1대) | 1회 | 2회 | 3회 |
| 10 | 0.41초 | 0.39초 | 0.37초 |
| 100 | 5.3초 | 4.36초 | 4.95초 |
| 1,000 | 46.49초 | 49.79초 | 47.7초 |
| 요청 건수 (서버 3대) | 1회 | 2회 | 3회 |
| 10 | 3.97초 | 0.75초 | 0.65초 |
| 100 | 8.9초 | 7.3초 | 7.5초 |
| 1,000 | 86.9초 | 76.2초 | 81.65초 |
| 요청 건수 (서버 5대) | 1회 | 2회 | 3회 |
| 10 | 4.80초 | 0.83초 | 0.73초 |
| 100 | 11.44초 | 8.60초 | 7.78초 |
| 1,000 | 85.60초 | 78.72초 | 72.71초 |
오히려 서버 대수가 증가할수록 요청의 응답 결과가 오래 걸리는 것을 확인했다.
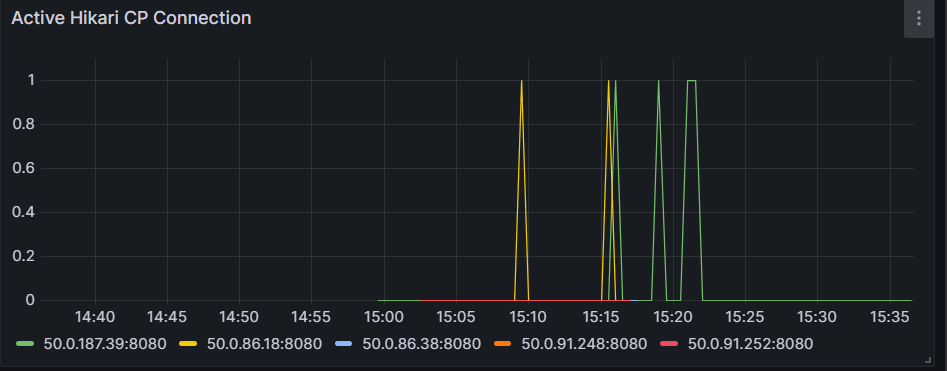
서버에 동시에 요청을 보냈을 때, 서버 5대를 통틀어서 Hikari Connection Pool의 Active Connection은 1개였다는 것이다. 그렇지만 서버에서는 요청을 받아서 DB에서 열심히 쿼리를 처리한 로그가 남아있다. 이게 좀 의아한 거 같다. MySQL 프로세스 리스트를 살펴봐도 각 요청마다 클라이언트 쓰레드가 생성되어 정상적으로 요청을 처리하는 것을 확인했다. 아마도... 쿠버네티스의 리소스 문제인 듯?
버전2
버전2는 ConcurrentLinkedQue를 이용한다. 요청에 대한 응답을 빠르게 처리하는 대신 Eventually Consistency를 이루는 방법이다. 조회수 카운트라는게 비즈니스적으로 중요한 것이기 아니기 때문에 '결과적으로 동기화' 되는 방법은 사용자 경험을 개선할 수 있는 좋은 방법이 될 것이라 생각한다.
ConcurrentLinkedQue는 내부적으로 CAS(Compare And Set) 연산을 사용해서 동기화를 보장한다. 전통적인 락을 이용할 때는 syncronized와 같은 키워드를 이용해 특정 코드 블록에 하나의 스레드만 접근하는 방식으로 구현되다보니 동시성 문제는 해결할 수 있지만 처리 속도가 느리다.
CAS를 이용해서 동시성 문제를 해결할 때는 다음과 같이 처리한다.
- 현재 메모리에 저장된 값과 예상되는 값이 일치한다면, 메모리에 저장된 값을 새로운 값으로 업데이트를 한다.
- 만약 일치하지 않는다면 일치할 때 까지 무한루프를 돌면서 확인한다.
ConcurrentLinkedQue의 단점은 동시에 너무 많은 업데이트 시도가 있는 경우 CAS 연산에 빈번히 실패할 것이라는 것이다. 이 경우CAS 연산이 성공할 때까지 무한 루프를 돌텐데, CAS 연산이 비이상적으로 많아질 수 있다. 이 때 오버헤드가 크게 발생할 수 있다는 것을 알고 있어야 한다.
컨트롤러의 로직은 다음과 같이 변경된다. viewCounter의 visit() 메서드를 호출해서 특정 손님이 특정 가게를 조회했다는 것을 이벤트를 메서드에 넘겨준다.
@GetMapping("/v2/tx1/{storeId}/{customerId}")
public String tx(@PathVariable Long storeId, @PathVariable Long customerId) {
// log.info("storeId = {}, customerId = {}", storeId, customerId);
memoryViewCounter.visit(customerId, storeId);
return "ok";
}viewCounter는 다음과 같이 구현했다.
- visit() 메서드가 호출되면, ConcurrentLinkedQue에 손님 + 사용자 정보를 밀어넣고 끝.
- @Scheduled 어노테이션에 의해 10초에 한번씩 commit() 메서드가 호출됨.
- commit() 메서드에서는 최대 1만개의 Event를 꺼낸 다음에 DB에 조회수 업데이트를 함.
@Component
@Slf4j
public class MemoryViewCounter implements ViewCounter {
private final ConcurrentLinkedQueue<String> eventQue;
private final ViewCounterV2 viewCounter;
...
@Override
public void visit(Long customerId, Long storeId) {
String event = String.format(VALUE_FORMAT, customerId, storeId);
this.eventQue.add(event);
}
@Override
public void commit() {
HashSet<String> eventSet = new HashSet<>();
for (int i = 0; i < 10000; i++) {
String poll = eventQue.poll();
if (poll == null) {
break;
}
eventSet.add(poll);
}
eventSet.stream()
.map(EventDto::create)
.filter(eventDto -> viewCounter.tx1(eventDto.getCustomerId(), eventDto.getStoreId()))
.forEach(eventDto -> viewCounter.tx1Update(eventDto.storeId));
}
@Scheduled(cron = "*/10 * * * * *")
public void called() {
log.info("eventQue Size = {}", eventQue.size());
commit();
}
...
}이렇게 구현하면 요청에 대한 응답 속도가 빨라진다. 반면 조회수의 동기화는 10초에 한번씩 이루어진다. 단순 요청은 API 호출을 했을 때 로그 한 줄만 남기는 작업인데, 비교군을 등록하기 위해서 추가했다.
버전2는 조회수가 10초에 한번씩 동기화 되지만, 단순 요청만 한 경우와 비교해봤을 때, 요청 처리 시간이 거의 차이가 나지 않는 것을 확인했다. V1과 비교했을 때, V2는 준수한 성능을 보여준다.
| 요청 횟수 | V1 | V2 | 단순 요청만 한 경우 |
| 10 | 0.14초 | 0.19초 | 0.03초 |
| 100 | 1.17초 | 0.23초 | 0.15초 |
| 1,000 | 11.13초 | 1.6초 | 1.16초 |
| 10,000 | 102.07초 | 11.8초 | 11.3초 |
| 100,000 | - | 121.5초 | 117.0초 |
그런데 버전2는 동시성 문제가 존재했다. 수평 스케일링 환경에서 요청을 여러 서버에 분산 시켜서 처리할 경우, 아래에서 볼 수 있듯이 DB에서 동시성 이슈가 발생하는 것을 확인했다. 예를 들어 10002번 store_id는 단 1개의 store_view_count 행이 존재해야하는데, 3개의 행이 존재하는 것을 볼 수 있다.
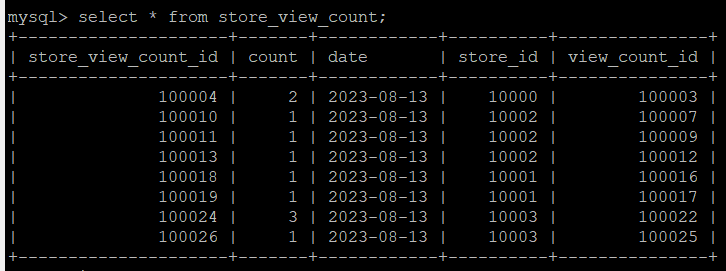
왜 그럴지를 따져는데, 트랜잭션이 나눠져 있었기 때문이다. 현재는 트랜잭션이 2개로 나누어져서 tx1()이 만족되는 경우, update() 메서드를 호출하면서 DB에 값을 저장한다. 그렇지만 원자적으로 동작하지 않기 때문에 데이터 정합성이 무너지는 것이다.
public boolean tx1(Long customerId, Long storeId) {
Store store = myRepository.findStore(storeId);
Customer customer = myRepository.findCustomer(customerId);
CustomerStoreVisit customerStoreVisitByCondition = myRepository.findCustomerStoreVisitByCondition(customerId, storeId, LocalDate.now());
if (customerStoreVisitByCondition != null) {
log.info("already exist");
return false ;
}
CustomerStoreVisit customerStoreVisit = CustomerStoreVisit.create(customer, store, LocalDate.now());
myRepository.saveCustomerStoreVisit(customerStoreVisit);
log.info("tx1 end");
return true;
}
public void tx1Update(Long storeId) {
LocalDate now = LocalDate.now();
StoreViewCount findSVC = myRepository.findStoreViewCount(storeId, now);
if (findSVC != null) {
findSVC.add();
return;
}
Store store = myRepository.findStore(storeId);
ViewCount viewCount = ViewCount.create(LocalDate.now());
myRepository.saveViewCount(viewCount);
StoreViewCount storeViewCount = StoreViewCount.create(store, viewCount);
storeViewCount.add();
myRepository.saveStoreViewCount(storeViewCount);
}예를 들어 다음 시나리오에서는 데이터 정합성이 반드시 무너진다.
- 서버1 : 요청받음. (customer 1, store 2)
- 서버2 : 요청받음. (customer 1, store 2)
- 서버1 : customer1, store2에 대한 customer_store_view 있는지 확인. → 없음
- 서버2 : customer1, store2에 대한 customer_store_view 있는지 확인. → 없음
- 서버1 : update
- 서버 2 : update
버전 2를 정리하면 다음과 같다.
- API 요청에 대한 응답 시간은 아주 빨라짐.
- DB에서 동시성 이슈가 발생함.
- 트랜잭션이 2개로 나누어져 원자적으로 이루어져야 하는 일이 원자적으로 이루어지지 않음. 따라서 DB의 정합성 문제가 발생함.
- 엄밀히 말하면 이 문제는 버전1부터 있었을 것이나 워낙 처리 속도가 늦어서 눈에 보이지 않았던 문제였던 것으로 추정됨.
그렇다면 트랜잭션을 원자적으로 가져가면서 문제를 해결할 수 있을 것으로 보인다.
버전3
세번째 버전은 MySQL의 네임드 락을 이용해서 원자적 연산을 구현하는 것이다. 아래와 같이 구현해 볼 수 있다.
- 연산을 시작하기 전에 <customer_id>-<store_id>로 구성된 네임드락을 MySQL에서 얻는다. 얻을 때까지 대기하고, 얻지 못하면 에러를 발생시킨다.
- 네임드락을 얻은 상태에서 Customer_Store_View가 있는지 확인한다. (오늘 방문한 적이 있는지 확인). 있다면 종료, 없다면 다음 단계 진행.
- Customer_Store_View를 만들어서 넣어주고, Store_View_Count를 업데이트 한다.
- 트랜잭션을 마무리 할 때 네임드락을 해제한다.
public void tx1(Long customerId, Long storeId) {
Store store = myRepository.findStore(storeId);
Customer customer = myRepository.findCustomer(customerId);
// 네임드락 획득
final String lockName = customerId + "-" + storeId;
boolean acquireLock = false;
for (int i = 0; i < 10; i++) {
acquireLock = myRepository.acquireNamedLock(lockName);
if (acquireLock) {
log.info("get lock");
break;
}
}
if (!acquireLock) {
throw new RuntimeException("fail to get Lock");
}
LocalDate now = LocalDate.now();
CustomerStoreVisit customerStoreVisitByCondition =
myRepository.findCustomerStoreVisitByCondition(customerId, storeId, now);
if (customerStoreVisitByCondition != null) {
log.info("already exist. release lock.");
// 네임드락 반납
myRepository.releaseNamedLock(lockName);
return;
}
CustomerStoreVisit customerStoreVisit = CustomerStoreVisit.create(customer, store, now);
myRepository.saveCustomerStoreVisit(customerStoreVisit);
addStoreViewCount(storeId, now, store);
// 네임드락 반납
myRepository.releaseNamedLock(lockName);
log.info("release lock");
}
private void addStoreViewCount(Long storeId, LocalDate now, Store store) {
StoreViewCount findSVC = myRepository.findStoreViewCount(storeId, now);
if (findSVC != null) {
findSVC.add();
return;
}
ViewCount viewCount = ViewCount.create(now);
myRepository.saveViewCount(viewCount);
StoreViewCount storeViewCount = StoreViewCount.create(store, viewCount);
storeViewCount.add();
myRepository.saveStoreViewCount(storeViewCount);
}버전 3의 성능을 확인해보면 아래와 같다. 결론부터 이야기 하면 버전2와 버전3를 비교했을 때, API 응답이 오기까지 걸리는 시간은 동일하다.
| 요청 횟수 | V2 | V3 | 단순 요청만 한 경우 |
| 10 | 0.19초 | 0.16초 | 0.03초 |
| 100 | 0.23초 | 0.22초 | 0.15초 |
| 1,000 | 1.6초 | 1.56초 | 1.16초 |
| 10,000 | 11.8초 | 12.01초 | 11.3초 |
| 100,000 | 121.5초 | 122.41초 | 117.0초 |
데이터 정합성 문제는 해결되는 것을 확인할 수 있다. 아래 결과에서 확인할 수 있듯이, 특정 손님이 해당 가게를 몇번 방문하건, 단 한번만 조회수가 올라가는 것을 볼 수 있다.
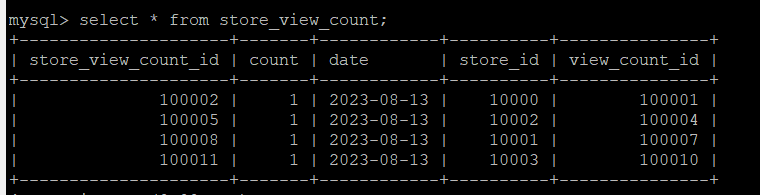
그렇다면 버전 3은 항상 좋은 방법일까? 버전 3의 한계점은 다음과 같다.
네임드락을 얻어야 함
DB마다 네임드락을 지원하지 않거나, 얻는 문법이 다를 수 있음. JPA를 이용해 네임드 락을 얻을 때, Native Query를 작성했음. JPA 자체가 DB 기술로부터 분리되기 위해 사용되는 기술이지만, 어떤 DB를 쓰느냐에 따라 쿼리를 수정해야 함.
수평 스케일링에 약함
손님 1번이 가게 10번을 1000번 조회했고, 이 요청은 1000대의 서버에 각각 요청되었다고 가정해보자. 그러면 스케쥴러가 조회수를 업데이트 할 때, '1-10'이라는 네임드락을 1000번 얻으려고 할 것이다. 이런 요청이 많아지면 많아질수록 스케쥴러가 네임드 락을 얻기 위해 대기를 하면서 트랜잭션이 길어진다. 결과적으로 모든 스케쥴러는 조회수를 업데이트하는데 더 많은 시간이 필요하게 될 것이다.
CAS 문제
여전히 ConcurrentLinkedQue의 CAS 실패에 따른 Overhead는 존재한다. 요청이 많이 오는 경우 ConcurrentLinkedQue에 계속 값을 추가하려고 할텐데, 요청 횟수가 증가할수록 CAS의 실패는 증가한다. 수평 스케일링을 통한 부하 분산으로 ConcurrentLinkedQue의 CAS 실패 비율을 줄일 수는 있지만, 위에서 언급한 문제에 걸리게 됨.
버전4
레디스를 이용한 분산락.
네임드락
'Spring > Spring' 카테고리의 다른 글
| 스프링 부트 - 자동구성 1 (0) | 2023.09.14 |
|---|---|
| Spring : EventPublishing을 통한 객체 간 결합 약화 (0) | 2023.08.27 |
| Spring Tomcat 관련 테스트 (0) | 2023.07.30 |
| Spring : 동일 타입 여러 스프링 빈 주입 받기 (0) | 2023.02.07 |
| Spring DB : 스프링 트랜잭션 전파 기본 (1) | 2023.02.01 |