
- 들어가기 전
- 카프카 스트림즈를 이용한 데이터 처리
- 카프카 스트림즈의 운영 특성
- 다른 시스템과 비교
- 카파 아키텍쳐
- Kafka Streams : DataFlowProgramming
- ProcessorTopology / Task / Stream Thread
- 스트림과 테이블
- 스트림 / 테이블의 이중성
- KStream / KTable / GlobalKTable
들어가기 전
이 글은 Kafka Streams와 ksqlDB 정복 책을 공부하며 작성한 글입니다.
카프카 스트림즈를 이용한 데이터 처리
카프카는 많은 데이터를 보관하고 있는 녀석이다. 카프카에 저장되어있는 데이터를 이용해서 뭔가를 하려고 했다면 그동안은 카프카 Consumer를 이용해서 데이터를 불러와서 일련의 데이터 핸들링을 진행했다. 그렇지만 이런 부분은 매번 반복되는 부분도 존재했었고 구현의 복잡함도 존재했다. 이런 부분을 해결하기 위해서 카프카 스트림즈가 개발되었다.

카프카 스트림즈는 다음 위치에서 역할을 가지고 처리한다. 카프카 스트림즈는 복잡한 데이터 핸들링의 처리와 반복되는 부분을 DSL과 Processor API로 추상화를 해주었다. 이 기능들은 일반 Java 개발자들이 이해하기 편리하므로 개발 생산성이 많이 올라가게 되었다. 뿐만 아니라 Kafka Streams는 확장성, 신뢰성, 유지 보수성을 모두 고려해서 작성된 스트림 처리 프레임워크이기 때문에 쉽게 사용할 수 있다.
카프카 스트림즈의 운영 특성
카프카 스트림즈의 운영 특성을 확장성, 신뢰성, 유지 보수성 관점에서 살펴보고자 한다.
확장성
시스템 부하가 증가했을 때 이에 잘 대처할 수 있다면 확장성이 있다고 볼 수 있다. 카프카 스트림즈는 StreamTask, StreamThread 개념을 도입하고 이를 통해서 부하에 탄력적으로 대응하며 확장성을 보장한다. 아래 내용을 살펴보면 이해할 수 있다.
- 카프카 토픽 파티션은 증설할 수 있다. 카프카 스트림즈의 작업 단위는 하나의 토픽 파티션에 대응된다.
- 따라서 토픽 파티션을 증설해서 카프카 스트림즈의 작업량을 증가시킬 수 있다.
- 컨슈머 그룹을 이용하면, 카프카 스트림즈 클러스터를 구성해서 협업할 수 있다.
다음과 같이 예를 들어서 생각하면 좀 더 쉬울 수 있다. 32개의 파티션 가진 토픽이 있고 하나의 카프카 스트림즈 인스턴스가 처리하고 있다고 가정해보자. 그러면 카프카 스트림즈 1개는 32개의 파티션을 처리하고 있다. 만약 처리 속도를 늘리고 싶다면, 카프카 스트림즈 인스턴스를 증가시켜주면 된다. 카프카 스트림즈를 8개로 늘려준다면, 카프카 스트림즈 1개당 4개의 토픽 파티션을 처리할 수 있게 된다.
신뢰성
카프카 스트림즈는 컨슈머 그룹을 이용한다. 컨슈머 그룹은 장애가 발생했을 때, '리밸런싱'을 이용해서 내결함성을 가진다. 카프카 스트림즈도 장애가 발생하면 컨슈머 그룹의 '리밸런싱' 기능을 이용해서 장애에 대응한다. 예를 들어 하나의 카프카 스트림즈 인스턴스에 장애가 발생하면, 이 카프카 스트림즈 인스턴스가 대응하던 StreamTask를 다른 카프카 스트림즈 인스턴스에 재분배해서 작업을 진행할 수 있다. 또한, 장애가 발생했던 카프카 스트림즈 인스턴스가 복구되면 자동으로 다시 토픽 파티션을 재분배해준다.
유지 보수성
카프카 스트림즈는 자바 라이브러리다. 일반 자바 개발자가 보기에 편리한 코드로 되어있으므로 문제 해결과 버그 수정이 다른 데이터 처리 플랫폼에 비해 상대적으로 쉽다.
다른 시스템과 비교
카프카 스트림즈는 스트리밍 처리 분야에서 활약하고 있다. 카프카 스트림즈와 다른 스트림 처리 기술들의 차이점을 살펴보려고 한다. 배치 모델과 처리 모델 관점에서 한번 살펴본다.
다른 시스템과 비교 : 배치 모델
플링크, 스파크 스트리밍 처리를 위해서는 스트림 처리 프로그램을 제출하고 실행할 때 전용 클러스터를 필요로 한다고 한다. 이는 많은 복잡성과 오버헤드를 발생시킨다고 한다. 그래서 시작할 때 어려움이 존재한다고 한다.
카프카 스트림즈는 자바 라이브러리로 구현되었고, 클러스터 관리가 필요없으므로 손쉽게 시작할 수 있다. 독립적으로 동작하기 때문에 모니터링, 패키징, 코드 배치에 있어 자유도가 높고 기존 시스템과 빠른 통합이 가능해진다.
다른 시스템과 비교 : 처리 모델
Apache Spark는 스트림을 처리할 때, 마이크로 배치를 이용해서 처리한다고 한다. 이것은 수신한 스트림을 일정 단위로 모은 다음에 처리해서 DownStream으로 보내주는 형태를 의미한다. 따라서 일부 지연 시간이 발생할 수 있다. 반대로 Kafka Streams는 하나의 이벤트를 depth-first로 처리해주는 형태다. 따라서 마이크로 배치에 비해 낮은 지연 시간이 기대된다.
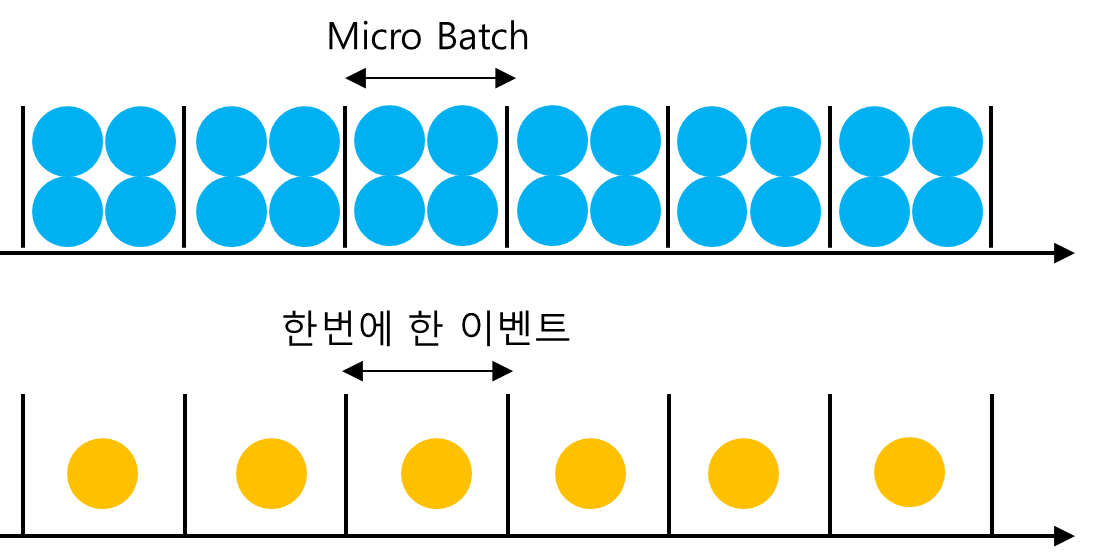
마이크로 배치를 사용하는 프레임워크들은 긴 지연 시간을 이용하는대신 높은 처리율을 얻는다. 카프카 스트림즈는 마이크로 배치가 아니기 때문에 다른 방식으로 높은 처리율을 얻는다. 카프카 스트림즈는 데이터를 좀 더 여러 파티션으로 나누어서 높은 처리율을 유지하면서 지연 시간을 줄이는 형태로 가져갈 수 있다.
카파 아키텍쳐
카프카 스트림즈는 스트리밍 처리에만 초점을 맞추고 있고, 이런 아키텍쳐를 카파 아키텍쳐라고 부른다. 반면 플링크, 스파크는 일괄 처리와 스트림 처리를 모두 지원하는데 이런 아키텍쳐를 람다 아키텍쳐라고 부른다.
- 람다 아키텍쳐 : 스트림 + 일괄 처리 지원
- 카파 아키텍쳐 : 스트림 처리만 지원
카파 아키텍쳐는 다음과 같은 특징을 가진다고 한다.
- Relation, Table은 일급 시민이다 따라서 각 Relation, Table은 독립적인 정체성을 가진다.
- Relation은 다른 Relation으로 변환이 가능하다.
- 임의로 Relation을 쿼리할 수 있다.
Kafka Streams : DataFlowProgramming
Kafka Streams : DataFlowProgramming - ProcessorTopology
카프카 스트림즈는 DFP(Data Flow Programming) 패러다임을 이용한다. 이 패러다임은 데이터의 입력 / 처리 / 출력 단계를 조합해서 프로그램을 표현하는 데이터 중심적인 방법이다. 방향성 비순환 그래프 - DAG(Directed Acyclic Graph) -를 Kafka Streams에서는 흔히 ProcessorTopology로 표현한다. 이 DAG는 데이터의 처리 흐름을 보여준다. 기본적으로 DAG, 그러니가 Processor Topology는 Source → Stream → Sink로 데이터의 흐름을 보여준다.

Kafka Streams : DataFlowProgramming - Subtopology
카프카 스트림즈는 SubTopology 개념을 가지고 있다. 카프카 스트림즈가 여러 Source 토픽에서 이벤트를 소비해야한다면, 카프카 스트림즈는 ProcessorTopology을 여러 개의 SubTopology로 나눌 것이다. 그리고 SubTopology 사이에는 데이터 교환이 일어나지 않는다.
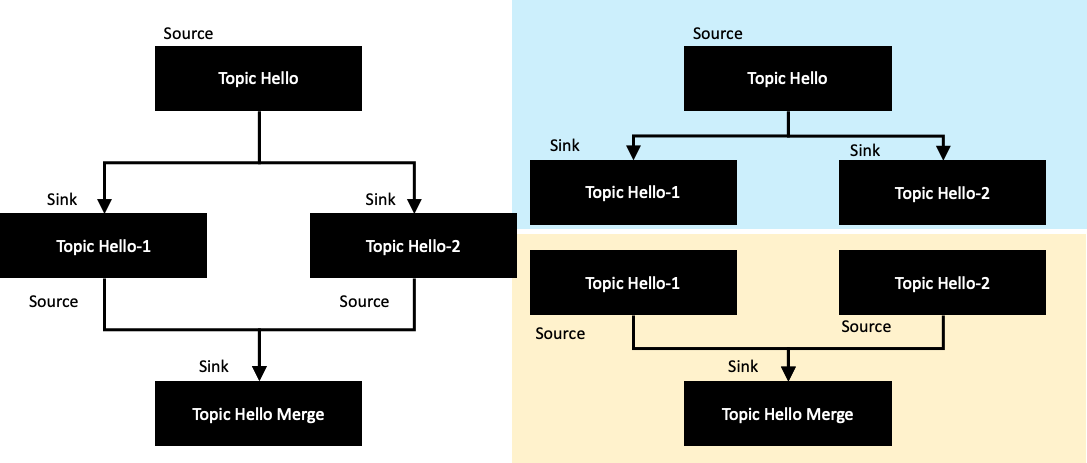
좌측 같은 토폴로지를 구현했다고 가정했을 때, 실제 토폴로지는 오른쪽과 같다고 볼 수 있다. ProcessorTopology는 두 개의 SubTopology로 나누어진다. 그리고 각각의 Subtopology는 실제로는 다음과 같이 연결되어 있지 않기 때문에 서로 간의 데이터를 주고 받는 동작을 하지는 않는다. 좀 더 정확히 이야기를 하면 Sink 토픽으로 흘러나간 메세지를, 다시 한번 Consumer로 불러온다는 의미다. 즉, 어플리케이션 상에서는 서로 다른 데이터로 인식을 하게 된다.
Kafka Streams : DataFlowProgramming - Depth First
카프카 스트림즈는 데이터를 처리할 때 Depth First 전략을 사용한다. Depth First 전략은 한번에 하나의 레코드씩 처리하고, 이 레코드를 끝까지 다 처리하면 다음 레코드를 처리한다는 의미로 이해할 수 있다. 그래프의 동작 방식은 DFS 알고리즘과 유사하게 동작하기 때문에 그렇게 이해해도 무방하다. Depth First 전략의 장점은 다음과 같다.
- 장점 : 데이터 흐름을 좀 더 이해하기 쉽게 해준다.
- 단점 : 데이터 처리가 느릴 경우, 다른 레코드의 처리가 함께 느려진다
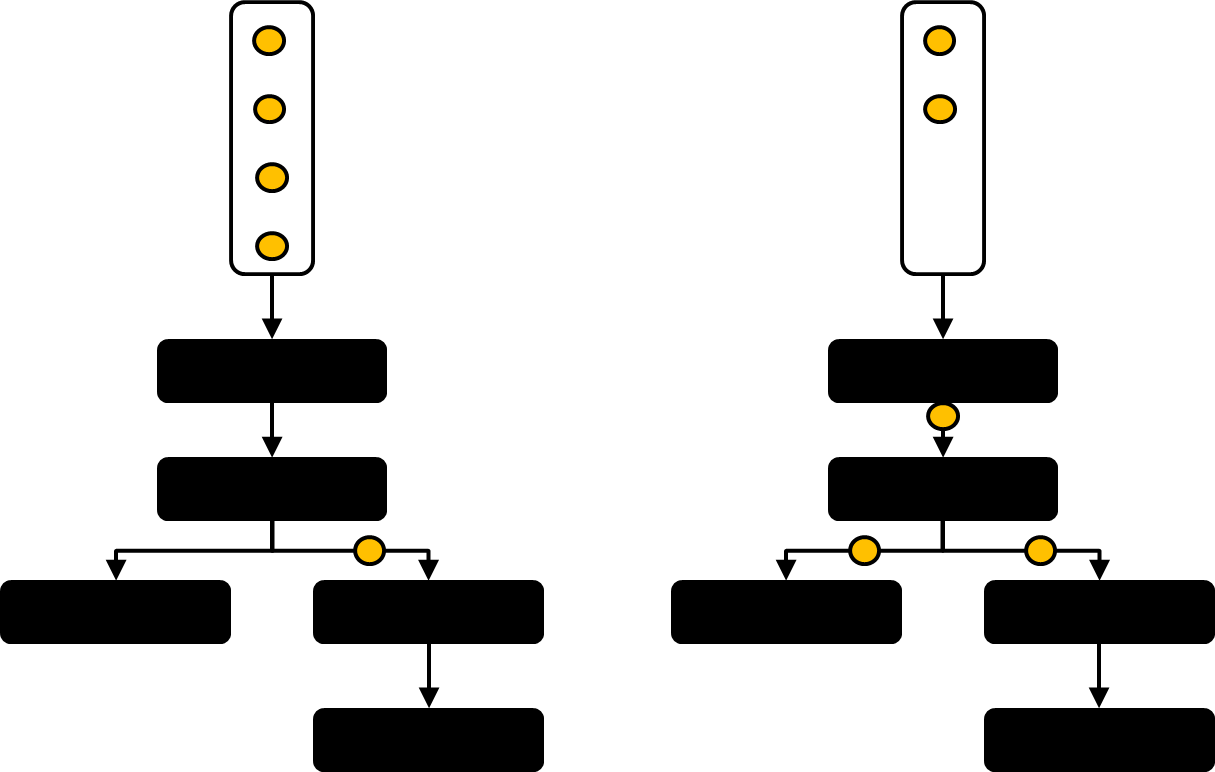
왼쪽 그림은 카프카 스트림즈에서 이야기하는 Depth First의 의미다. 한번에 하나의 메세지만 Processor Topology를 흐른다. 반면 다른 스트리밍 플랫폼에서는 한번에 여러 메세지가 흐를 수 있다. 이것이 카프카 스트림즈와 다른 스트리밍 플랫폼과의 차이점이다.
Kafka Streams : DataFlowProgramming - 장점
데이터 흐름 프로그래밍 패러다임으로 작성할 경우, 여러가지 장점을 얻을 수 있다.
- 방향성 그래프(DAG)로 프로그램을 표현하면, 프로그램을 쉽게 이해할 수 있다.
- 프로그램을 쉽게 이해하면, 카프카 스트림즈 어플리케이션을 더욱 쉽게 이해하고 유지보수 할 수 있다.
- Processor Topology는 여러 스레드와 어플리케이션 인스턴스로 쉽게 생성되고 병렬화 할 수 있는 템플릿으로 동작한다.
ProcessorTopology / Task / Stream Thread
카프카 스트림즈를 구성하는 것들 중에는 ProcessorTopology, Task, Stream Thread가 존재한다. Task는 ProcessorTopology를 참조하고, StreamThread가 Task를 참조하는 형태가 된다.
- ProcessorTopology : 프로그램의 전체적인 설계도
- Task : Kafka Streams에서 병렬로 수행될 수 있는 가장 작은 작업 단위다. ProcessorTopology에 파티션 개념이 들어간 것으로 이해할 수 있다.
- StreamThread : 실제로 일을 하는 주체다. 이 녀석들이 생성된 Task를 나눠가져서 수행한다.
조금 더 부연 설명을 하면 StreamTask는 카프카 스트림즈가 구독하는 토픽들 중 가장 큰 파티션의 수만큼 생성된다. 그리고 카프카 스트림즈 인스턴스의 일꾼인 StreamThread가 StreamTask를 나눠가지게 된다.
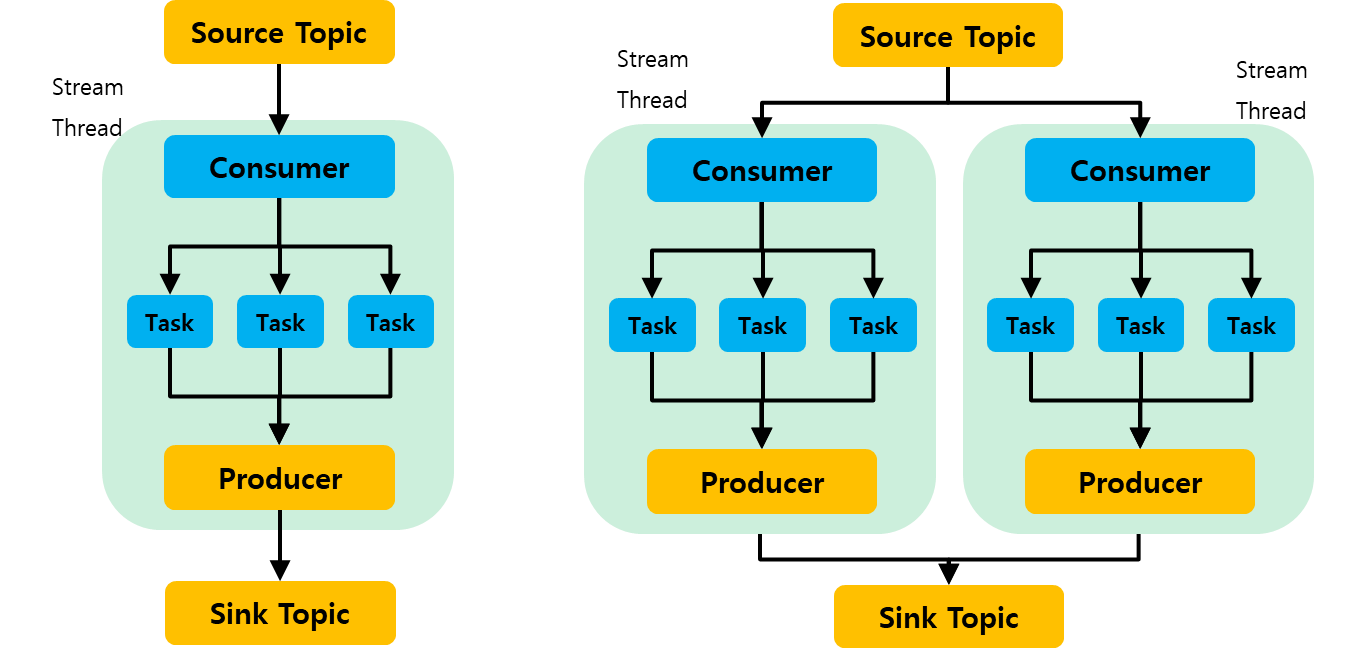
StreamThread는 각각 자신의 Consumer / Producer를 가진다. 그리고 하나의 StreamThread는 여러 StreamTask를 가지고, 이 StreamTask는 파티션을 기준으로 나누어진다. 각 Consumer에서 불러온 메세지들이 StreamTask에서 처리되고 각 Producer를 통해 Sink 토픽에 공급되는 형태가 된다.
스트림과 테이블
카프카 스트림즈는 카프카의 토픽을 Stream / Table로 추상화 할 수 있다. 이 때 Stream은 Stateless하고, Table은 Stateful하다. Stream과 Table을 파이썬 코드로 생각해보면 다음과 같다.
- Stream : 새로 들어온 레코드는 append 된다.
- Table : 새로 들어온 레코드는 update 된다. 딕셔너리의 동일한 Key에 Value를 업데이트 하는 것과 같다.
그렇다면 카프카의 레코드는 immutable한데 어떻게 'Update' 개념의 Table을 구현할 수 있게 된 것일까? Table은 Kafka를 이용해서 구현된 것이 아니라 Application 단에서 구현이 된 것이다. Table은 Application 단의 In-memory Key-Value 저장소를 이용하거나, 로컬 스토리지 영역의 RocksDB를 이용해서 물리화(Materialized)된다.
스트림 / 테이블의 이중성
스트림과 테이블의 이중성은 서로 변환할 수 있음을 의미한다. 스트림은 테이블로 변환될 수 있고, 테이블 역시 스트림으로 변환될 수 있다. 그렇다면 각각은 어떻게 서로로 변환될 수 있을까?
- 스트림 → 테이블 : 각 메세지는 Key, Value로 전달된다. 이 메세지는 In-memory, 혹은 RocksDB를 이용해 Key - Value로 저장되어 변환될 수 있다.
- 테이블 → 스트림 : 테이블은 특정 시점의 스트림을 보는 것이다. 테이블을 스트림으로 변경하면 업데이트를 삽입으로 처리해서 새로운 레코드를 append한다.
KStream / KTable / GlobalKTable
카프카 스트림즈에는 추상화 클래스를 제공한다. 각각은 어떤 것을 의미할까?
- KStream : 파티셔닝된 레코드 스트림의 추상화다. 데이터는 Append 형식으로 저장된다.
- KTable : 파티셔닝된 레코드 테이블의 추상화다. 데이터는 Put 형식으로 저장된다.
- GlobalKTable : 데이터의 전체 복사본을 포함하는 레코드 테이블의 추상화다. 모든 StreamThread는 같은 GlobalKTable을 가진다.
'Kafka eco-system > KafkaStreams' 카테고리의 다른 글
| Kafka Streams와 ksqlDB 정복 : 상태가 있는 처리 (4장) (1) | 2022.12.20 |
|---|---|
| Kafka Streams와 ksqlDb 정복 : 상태가 없는 처리 (3장) (0) | 2022.12.20 |
| Kafka Streams : Kafka Streams의 리밸런싱 관련 내용 정리 (0) | 2022.12.04 |
| Kafka Streams : pollPhase() (0) | 2022.12.01 |
| Kafka Streams : Repartition (0) | 2022.11.22 |



